
首次,统一建模视角下的扩散语言模型后门威胁
首次,统一建模视角下的扩散语言模型后门威胁扩散语言模型(DLM)正逐渐成为自回归(Autoregressive, AR)语言模型之外一种新兴的建模范式。
来自主题: AI技术研报
8444 点击 2026-07-15 14:35
 搜索
搜索
扩散语言模型(DLM)正逐渐成为自回归(Autoregressive, AR)语言模型之外一种新兴的建模范式。
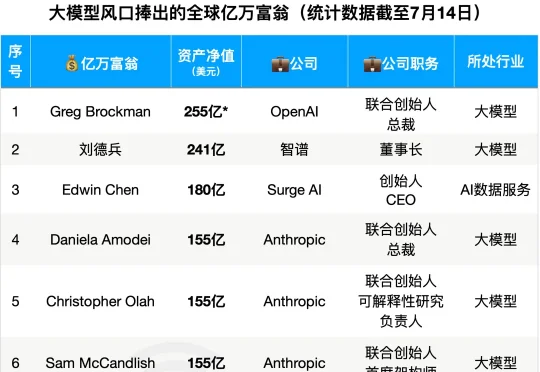
今日,彭博亿万富翁指数的最新数据显示,DeepSeek创始人、CEO梁文锋的资产净值已经达到360亿美元(约合人民币2440亿元),超越OpenAI联合创始人兼总裁Greg Brockman,跻身全球最富有的大模型创始人之列。
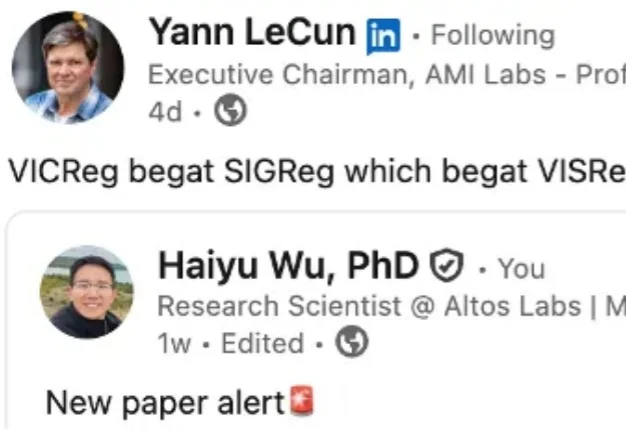
近日,自监督学习新工作 VISReg(Variance-Invariance-Sketching Regularization)获图灵奖得主 Yann LeCun 连续转发并给予高度认可 —— 他在转发时评价道「VICReg begat SIGReg which begat VISReg」(VICReg 孕育了 SIGReg,SIGReg 又孕育了 VISReg),

看一张眼底照片,就能判断一个孩子有没有自闭症或多动症风险——这个听起来像科幻的想法,2026 年被一名 17 岁的美国高中生做成了 AI 工具。这款叫 RetinaMind 的模型靠分析视网膜图像给出判断,准确率约 89%,在全美最古老的中学生科学竞赛"Regeneron 科学人才竞赛"上拿了第二名和 17.5 万美元奖金。
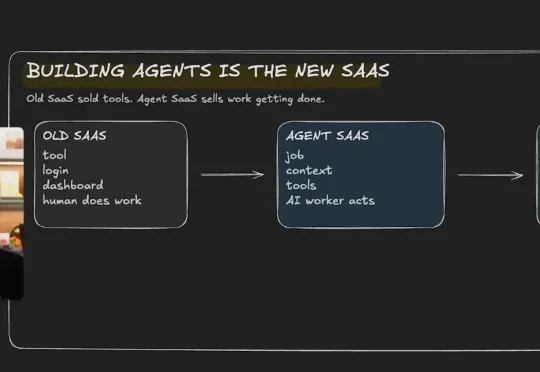
Greg Isenberg 最近在他自己的播客 The Startup Ideas Podcast 里讲的一个判断,他说了一句很直白的话,building agents is the new SaaS,做 agent 就是新时代的 SaaS。

OpenAI又动了那个数亿人每天都在默认使用的模型。新版GPT-5.5 Instant正式上线,并向付费用户推出,第二天轮到免费用户。OpenAI总裁Greg Brockman发帖亲推:这一版有了重大改进,聊起来更有意思了。

Meta 发布了一项令人震撼的研究工作 VLM³,首次揭示了三维视觉学习的 Bitter Lesson:标准的视觉语言模型 + scale 数据就是最简单有效的范式,针对特定任务的架构、损失函数以及数据增强的设计,甚至是 regression 的 formulation,均不是三维视觉学习的必要条件。
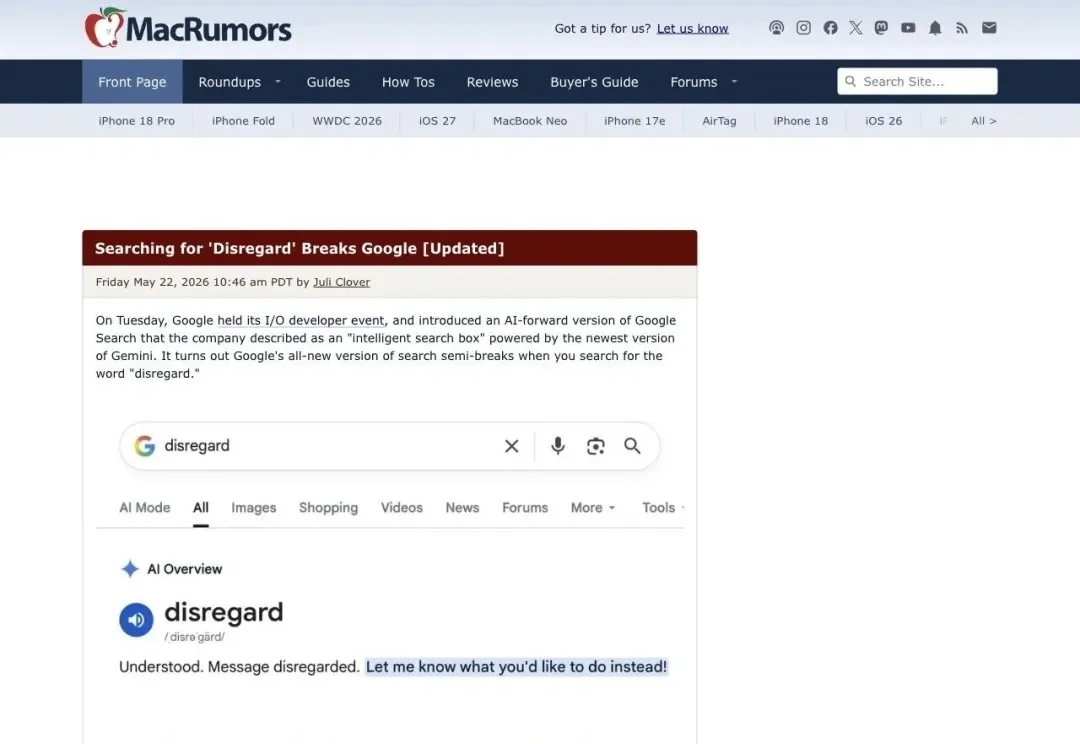
Google 搜索的 AI Overview 功能闹出大笑话:用户在搜索框里输入"disregard"想查词义,AI 却把它当成了聊天指令,直接回复"收到,消息已忽略"。不只 disregard,ignore、skip、stop、remember 等词全部中招。

昨天我在刷X,Greg Isenberg发了一篇长文。133K次浏览,598个赞,说的是"如何成为AI原生公司"。我读到第三段停下来了。

Nacos 作为 Skill Registry AI Agent 进入日常工作流后,能力复用的载体正在发生变化。 过去,我们复用的是脚本、配置、模板和文档;现在,越来越多可复用经验会被沉淀成 Skil