# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如今,强化学习(RL)已成为提升大语言模型(LLM)复杂推理与解题能力的关键技术范式,而稳定的训练过程对于成功扩展 RL 至关重要。由于语言具有强烈的上下文属性,LLM 的 RL 通常依赖序列级奖励 —— 即根据完整生成序列给一个标量分数。
然而,主流 RL 算法(如 REINFORCE 与 GRPO)普遍采用基于 token 的优化目标。这种「奖励在序列级、优化在 token 级」的不匹配引发了对于它们理论健全性与训练稳定性的担忧,因此已经有研究尝试直接使用序列级优化目标。
此外,token 级优化目标在混合专家(MoE)模型的 RL 训练中带来了新的挑战,比如 MoE 的动态专家路由机制可能破坏 token 级重要性采样比的有效性。由此引出的关键问题是:在什么条件下,用 token 级目标优化序列级奖励是合理的?有效程度又是怎样的?
针对这些问题,阿里千问团队提出了一种针对 LLM 的全新 RL 公式化方法。核心洞察是:为了优化序列级奖励的期望值,可以使用一个替代(surrogate)token 级目标作为其一阶近似。这一近似在以下两种偏差都足够小的条件下才成立:
这一观点从原理上解释了多种 RL 稳定训练技巧的有效性,比如 1)重要性采样权重天然出现在基于该一阶近似的 token 级替代目标中;2)剪切(Clipping)机制通过限制策略变化幅度来抑制策略陈旧;3)在 MoE 中,路由重放(Routing Replay)方法通过在策略优化过程中固定专家路由,能够同时减少训练–推理差异与策略陈旧,从而提高训练稳定性。

为验证本文理论洞察并探索实现稳定 RL 训练的有效实践,团队使用一个 30B 参数的 MoE 模型进行大量实验,总计耗费数十万 GPU 小时。
主要结论包括如下:

由于团队采用的是序列级奖励设置,即对整个响应 y 赋予一个标量奖励 R (x, y),因此专注于序列级优化,而不考虑基于价值函数的设置(比如 PPO),其中每个 token 会从价值模型获得一个标量评分从而引导策略优化。
至于为什么不采用价值函数方法,是因为团队发现:构建通用、可扩展且可靠的价值模型本身就极为困难(甚至几乎不可能)。
团队的公式化方法从真正希望最大化的序列级奖励期望出发:
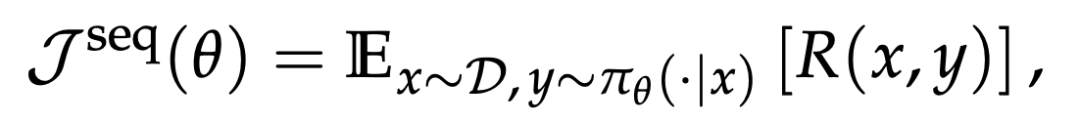
其中 π_θ 是目标策略。由于模型生成响应通常并非在训练引擎(如 Megatron、FSDP)中完成,而是在推理引擎(如 SGLang、vLLM)中进行,团队采用重要性采样(IS)来完成等价的变换:
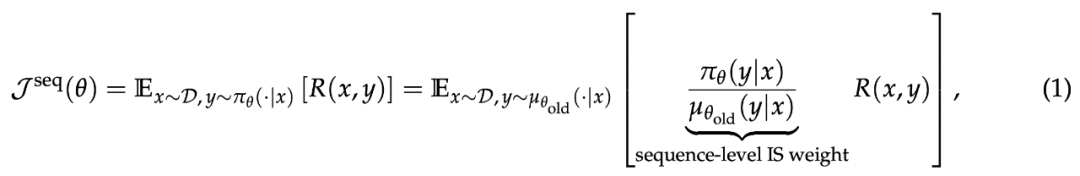
关键步骤是引入以下替代的 token 级优化目标:

其梯度为:

这一梯度形式实际上就是带 token 级重要性采样权重的基本策略梯度算法(REINFORCE)。核心洞察是:公式 (3) 中的 token 级目标可以视为公式 (1) 中序列级目标的一阶近似。也就是说,团队用一个更易优化的 token 级替代目标来逼近真正希望最大化的序列级期望奖励。
为了使上述一阶近似有效,需要满足一个关键条件:目标策略 π_θ 与 rollout 策略 μ_{θ_old} 必须足够接近。这一点乍看不太直观,因此为了便于理解,对于给定的提示 x 和任意 token y_t,团队将其重要性采样权重(IS)重写为:

对于 MoE 模型而言,使一阶近似成立的条件变得更为复杂。具体来说,在生成每个 token 的前向计算中,MoE 模型会通过专家路由机制动态选择并激活少量专家参数。将专家路由纳入公式 (5) 后,MoE 模型的 token 级 IS 权重可写为:
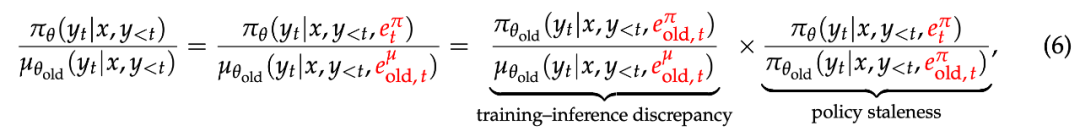
由此可以看出,MoE 场景下的强化学习挑战在于:专家路由与训练 — 推理差异、策略陈旧的紧密耦合,从而更容易导致公式 (3) 中基于一阶近似的 token 级替代优化目标失效。
由于专家路由会削弱 MoE 模型中一阶近似的有效性,可通过 Routing Replay 方法消除这一影响。Routing Replay 的核心思想是在策略优化过程中固定路由到的专家,从而稳定 MoE 模型的 RL 训练,使其在优化行为上更接近稠密模型。
Routing Replay 主要有两种具体实现方式:Vanilla Routing Replay(R2) 与 Rollout Routing Replay(R3)。
R2 的目标是减轻专家路由对策略陈旧的影响,其方法是在梯度更新阶段,复现训练引擎中 rollout 策略所选择的路由专家:
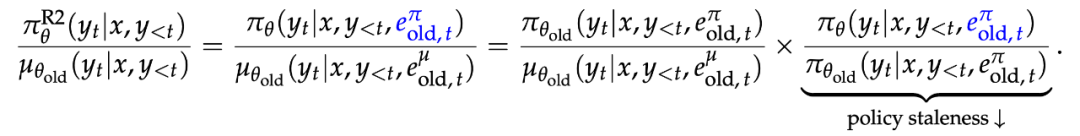
R3 的目标是减轻专家路由对训练 — 推理差异的影响,其实现方式是在训练引擎中统一复现推理引擎中 rollout 策略所选定的路由专家。这一做法不仅降低了训练 — 推理差异,也同时缓解了专家路由对策略陈旧的影响:
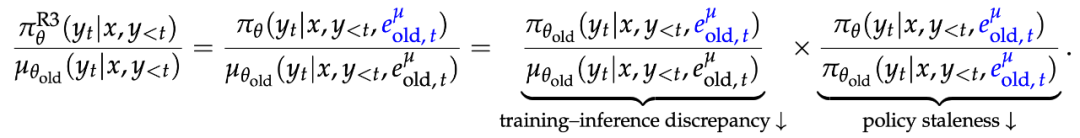
在实验中,团队对公式 (3) 的 REINFORCE 优化目标进行了两项最小化修改,从而构建了一个极简基线算法,称为 MiniRL。
团队在数学推理任务上进行了实验,内容为:模型生成的回答会与标准答案比对,并获得一个二值奖励。团队构建了包含 4096 道、均具有经过验证答案的数学题目作为 RL 训练的提示集。评测时,团队在 HMMT25、AIME25 和 AIME24 基准上(这三个基准共包含 90 道竞赛级数学题)分别采样 32 个响应,并报告其平均准确率。
实验采用了从 Qwen3-30B-A3B-Base 微调得到的冷启动模型。训练采用 BF16 精度,而推理由于使用 FP8 精度而具有更低数值精度,从而构成一种严格的应力测试场景,即训练与推理之间存在较大的数值差异。除了训练奖励,团队还监测了两项动态指标:目标策略的 token 级熵以及推理引擎与训练引擎中 rollout 策略之间的 KL 散度。
从下图 1 中,团队得到了以下观察结果与结论:

从下图 2 至图 4 中,团队得到了以下观察结果与结论:一旦引入 off-policy 更新,Routing Replay 与 clipping 都成为实现稳定训练的关键要素。
具体来讲,如图 2 和图 3 所示,只要缺失 Routing Replay 或 clipping 中的任一项,训练都会提前崩溃,进而导致峰值性能下降。这说明:Routing Replay 能够缓解专家路由带来的不稳定因素;Clipping 则能有效抑制过度激进的策略更新。两者共同作用,从而抑制策略陈旧,保障训练稳定性。



在下图 5 中,团队展示了三种不同的冷启动初始化方式最终都取得了相近的性能。这一现象表明,研究重点应更多放在强化学习(RL)方法本身,而不必过度关注冷启动初始化的具体细节。
此外,通过对比图 1 至图 4,团队发现:无论是 on-policy 还是 off-policy,只要训练过程得以稳定,其峰值性能都高度一致。这些结果进一步说明:稳定的训练过程在成功扩展 RL 中起着决定性作用。

更多技术细节请参阅原论文。
文章来自于“机器之心”,作者 “机器之心编辑部”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
