清华团队VeriLoop Coder-E1正式开源:以循证螺旋驱动可验证的递归式自我改进
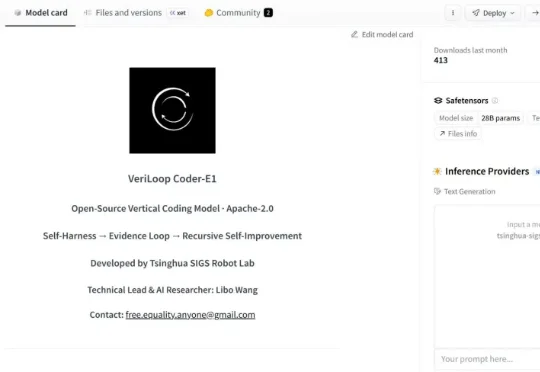
清华团队VeriLoop Coder-E1正式开源:以循证螺旋驱动可验证的递归式自我改进近日,由清华大学深圳国际研究生院智能机器人实验室刘厚德教授领衔、王立博博士后担任 AI 首席研究员的大模型团队,正式发布了 VeriLoop Coder-E1—— 一款基于 Qwen3.6-27B 构建、面向仓库级代码修复与智能体式软件工程任务的开源垂类代码模型。
来自主题: AI技术研报
8222 点击 2026-08-02 13:44