# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文为Milvus Week系列第7篇,该系列旨在把Zilliz团队过去半年多积累的先进的技术实践和创新整理成多篇干货深度文章发布。
以下是DAY 7内容 划重点:
我们究竟在为多少冷数据支付热数据的价格?
相信以下场景,很多朋友都很熟悉:
本质上,这些场景都存在一个共性问题:仅贡献不到10%查询调用的冷数据,往往占据了80%的内存资源。而在Milvus 2.5及更早版本中,无论数据是否会被访问,都必须全量加载到本地(内存或磁盘)。这就导致一个尴尬的结果:即便大部分资源处于闲置状态,用户仍需为这些无效占用支付高昂成本。
那么核心问题来了:向量数据库真的需要将全量数据常驻本地吗?
在Milvus 2.6中,答案是否定的。
在探讨解决方案之前,我们先深入剖析Milvus 2.5及更早版本的“全量加载”模式为何会成为业务增长的瓶颈。
过去,当用户发起Collection.load()请求时,Milvus 2.5及更早版本的执行流程如下:
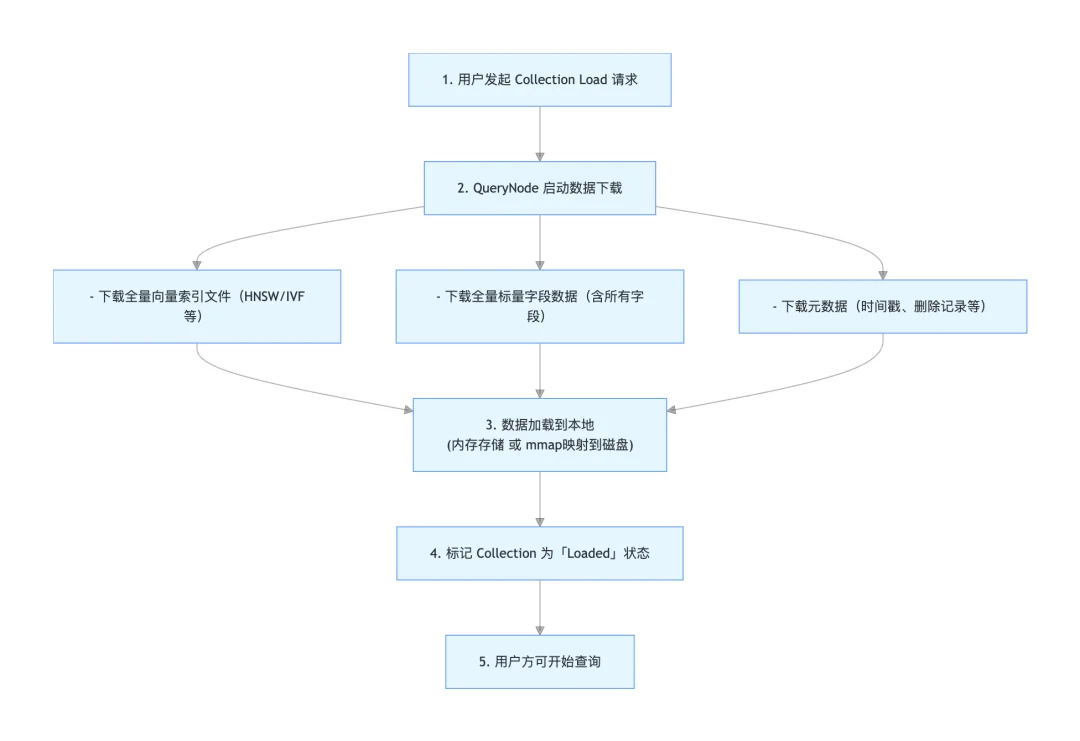
关键说明:对于包含原始向量数据的索引,Milvus仅加载索引本身,不会重复加载原始向量。但即便如此,索引仍需全量加载——哪怕只有极少量数据会被实际访问。
我们可以通过一个具体案例直观感受其资源占用:假设有一个中等规模向量数据集,包含1亿条768维(BERT embedding)float32类型(4字节)向量,采用HNSW索引。仅该索引的内存占用(含原始向量)就约为430GB;若叠加用户ID、时间戳、分类标签等标量字段,总内存占用将达到500GB以上。
这意味着,即便80%的数据从未被访问,一个中等规模数据集仍需占用500GB以上的本地资源。
对于全量高频访问的场景,全量加载模式尚有合理性:若所有数据均为高频需求,可采用内存模式加载,虽成本最高但性能最优;若数据由热数据与温数据构成,可采用mmap模式将温数据映射到磁盘,兼顾性能与性价比。
但在80%数据为长尾冷数据的场景中,全量加载模式的弊端便暴露无遗,集中体现在性能与成本两大维度:
首先是性能侧瓶颈,滚动升级周期会变长:10TB 集群的完整滚动升级可能需要一整天;故障恢复会变慢:QueryNode 重启后,需要重新加载全部数据;实验迭代也会变慢:AI 团队切换数据集版本,每次都要等待漫长的加载时间
成本侧:以1TB向量数据为例,基于主流云厂商的内存型实例测算,每年保守成本约7万美元(AWS r6i系列约$5.74/GB/月;GCP n4-highmem系列约$5.68/GB/月;Azure E系列约$5.67/GB/月)。如果能将 80% 的冷数据成本降低到对象存储级别($0.023/GB/月),成本结构将变成: ( 200 GB热数据× $5.68+800GB冷数据 × $0.023 )× 12个月≈1.4万美金,整体成本节约80%。
针对全量加载模式的痛点,Milvus 2.6引入了根本性的技术革新——分层存储(Tiered Storage),将数据加载逻辑从“全量预加载”转变为“按需加载”,实现性能与成本的精准平衡。
该模式的核心逻辑可概括为三点:
通过这一逻辑,Milvus突破了本地内存与磁盘的物理容量限制,借助数据淘汰(Eviction)机制实现本地资源的动态管理。
而这一切的背后,依赖三大核心技术支撑。
核心思想:在 Collection Load 阶段,不下载实际数据,只加载必要的元数据。
Milvus 2.5加载流程
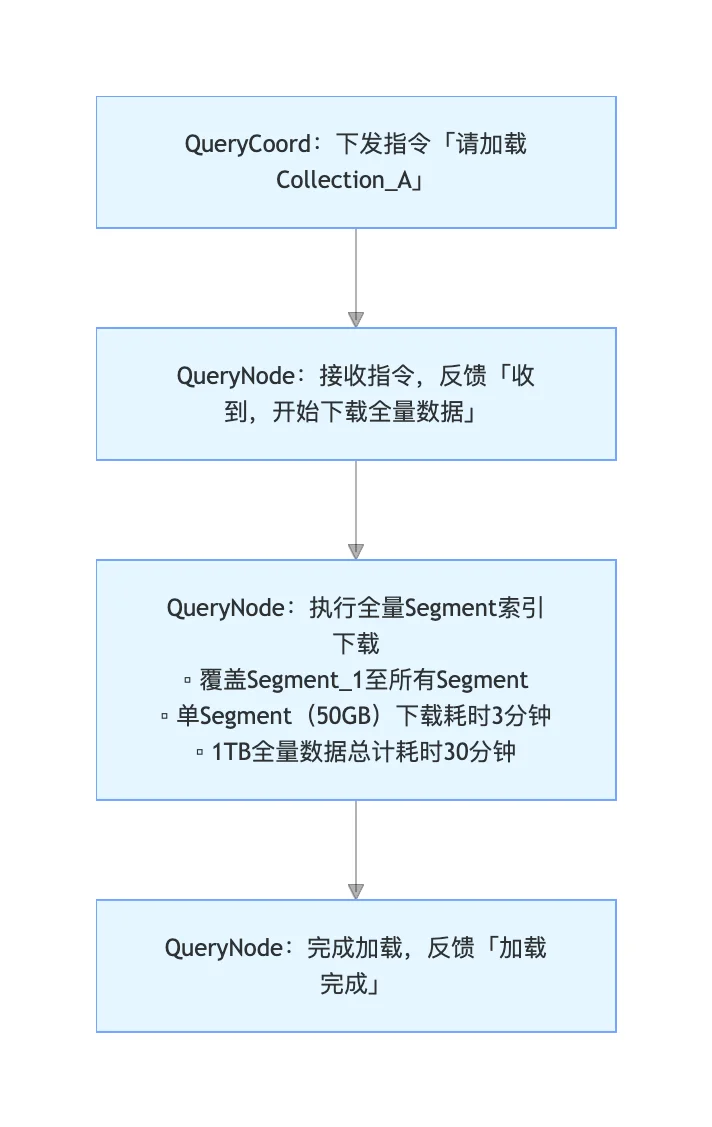
Milvus 2.6+延迟加载流程
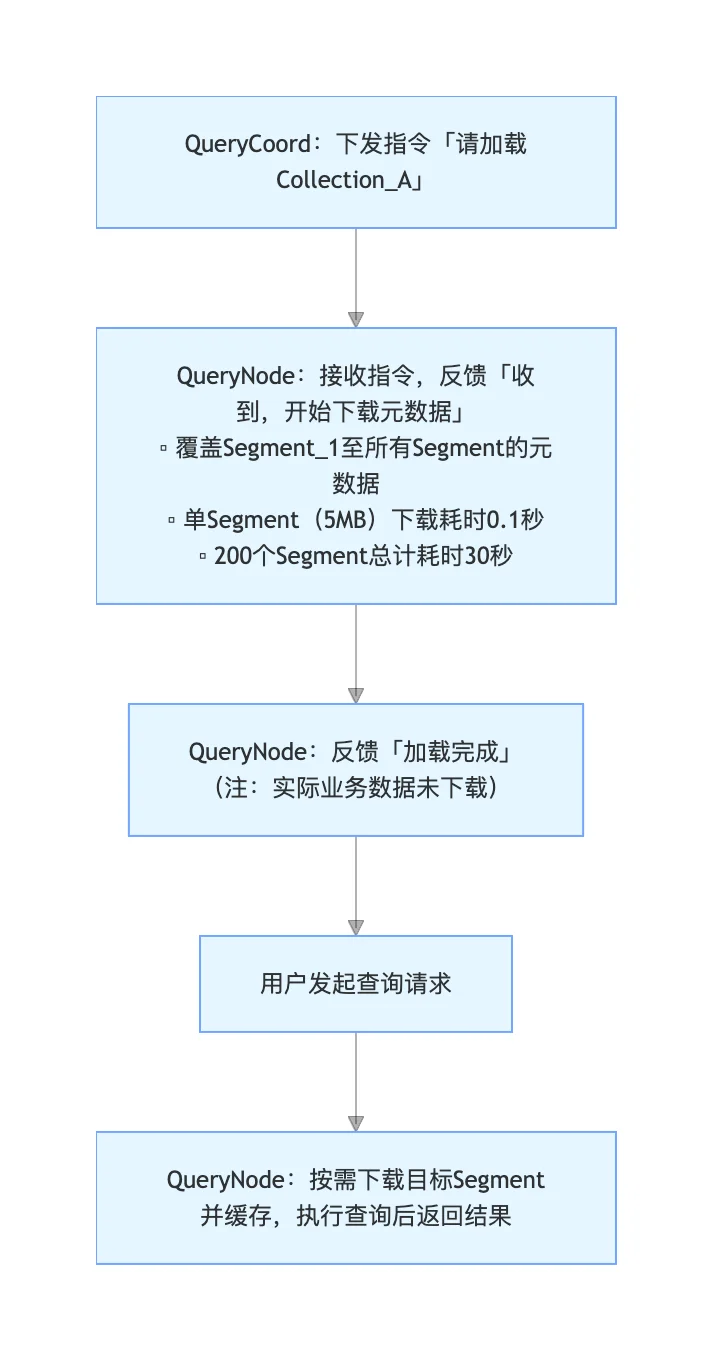
加载的元数据包含四大核心部分:
Lazy Load 解决了"何时加载"的问题,Partial Load 则解决了"加载多少"的问题。
向量索引:按租户加载
Milvus 2.6+ 最强大的能力是多租户场景中向量索引的按需加载。当用户的搜索仅触及一个租户,Milvus 将仅加载向量索引中包含该租户部分的索引,并跳过索引中的其他数据。
其优势显而易见:沉睡租户的向量索引不占用本地资源,活跃租户索引常驻缓存,且支持租户级别的LRU淘汰策略。
标量字段:Partial Load(只加载需要的列)
假设某Collection包含50个 Schema(含id、vector、title、description、category、price、stock、tags等),而用户查询仅需返回id、title、price三个字段。
在Milvus 2.5中,系统会加载全部50个标量字段;而在Milvus 2.6+中,仅加载查询涉及的3个字段,未使用的47个字段采用延迟加载模式,首次访问时才加载。
以单字段20GB计算,Milvus 2.5需加载1000GB标量数据,而Milvus 2.6+仅需加载60GB常用字段数据,资源占用降低94%。
注意:按租户加载标量数据和索引的能力将在近期版本中正式推出,届时将进一步提升加载速度与冷查询效率。
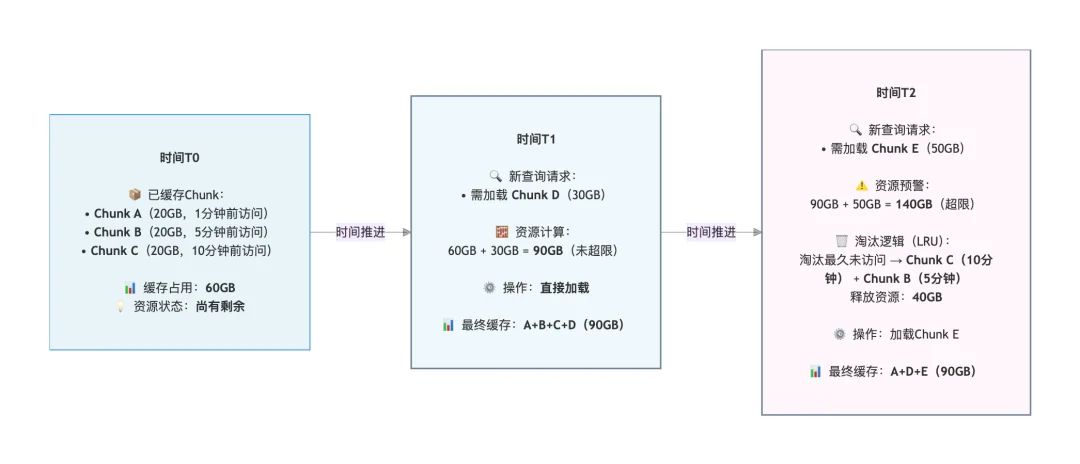
延迟加载与部分加载大幅降低了本地资源占用,但长期运行后缓存仍可能被占满。此时,基于LRU的缓存淘汰机制便发挥作用,核心思想是淘汰最久未使用的数据块,为新数据腾出空间,真正实现虚拟容量。
我们以本地资源上限100GB为例,直观展示缓存动态调整过程:
理论设计的很美好,但实际表现如何?接下来,我们通过接近业务实际的测试,量化分层存储的性能表现。
为验证分层存储的实际效果,我们搭建了接近真实业务的测试环境,从加载时间、资源占用、查询性能、容量提升、成本节约五个维度进行对比。
核心测试结果如下:
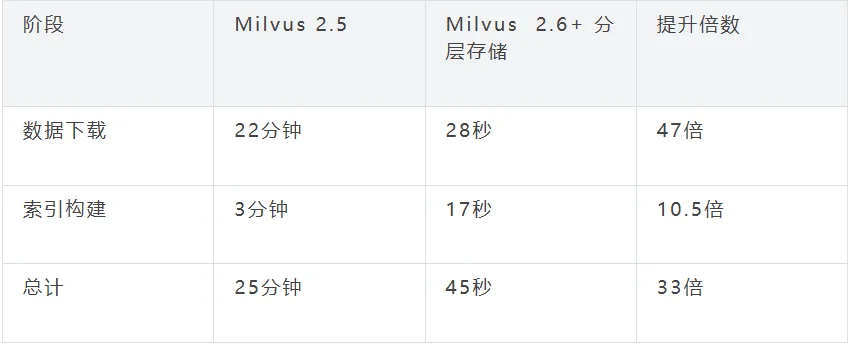
结论:Milvus 2.5的25分钟加载时间,Milvus 2.6+仅需45秒即可完成,加载效率实现质的飞跃。
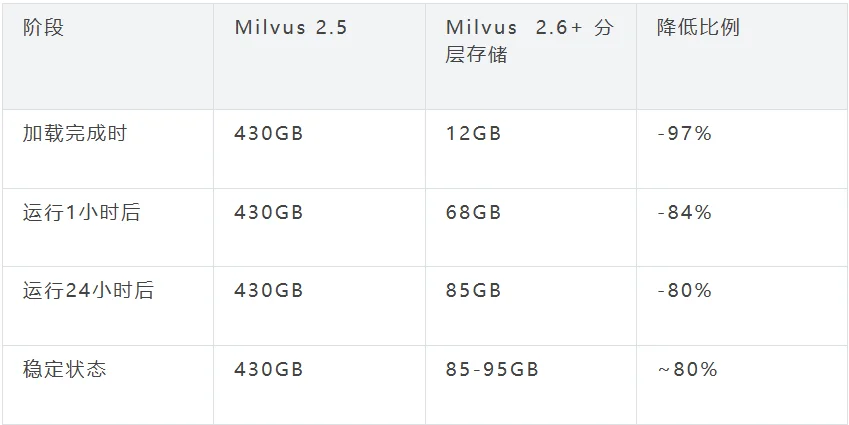
时序特征:Milvus 2.5资源占用始终维持430GB;Milvus 2.6+加载完成时仅12GB,运行过程中随缓存数据增加逐步上升,24小时后进入85-95GB的稳定状态,资源占用长期降低80%。
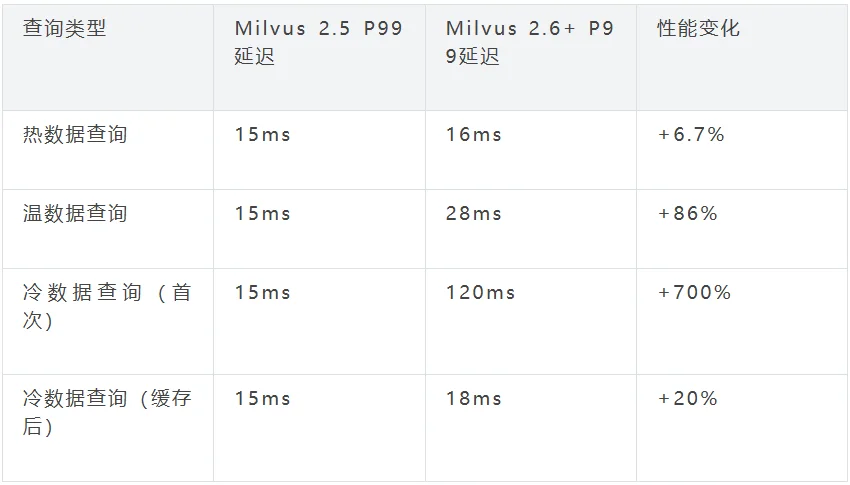
关键结论:占80%查询量的热数据查询延迟仅增加6.7%,性能几乎无损;冷数据首次查询因需临时加载存在延迟,但缓存后延迟仅增加20%,且冷数据本身访问频率低,对整体业务影响可控。
在相同硬件资源(8台64GB内存服务器,总内存512GB)下,Milvus 2.5仅能加载512GB数据(约1.36亿向量),而Milvus 2.6+可加载2.2TB数据(约5.9亿向量),容量提升4.3倍。
以2TB向量数据、AWS环境为例,热数据占比20%(400GB),具体成本对比如下:
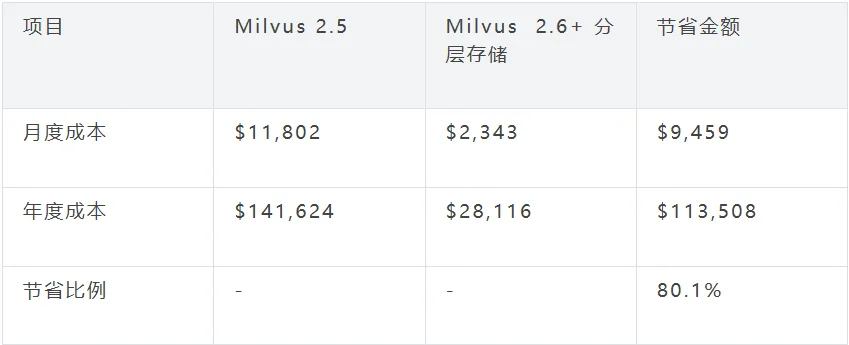
我们可以发现,借助分层存储,我们可以实现
基于测试结果与真实业务案例,我们将分层存储的适用场景分为“强烈推荐”“推荐”“不推荐”三类,帮助用户精准决策。
电商推荐系统(向量检索场景)特征:热门商品与长尾商品访问频率差异极大;
冷热分明的大数据集(向量为主)特征:数据量达TB级以上,访问集中于近期数据;
成本敏感型业务特征:预算有限,可接受少量性能损失;
历史数据归档场景特征:存在大量历史向量数据,查询频率极低;
全热数据访问场景特征:所有数据访问频率相近,无明显冷热区分;
原因:无法享受缓存收益,反而增加系统复杂性。
极致性能要求场景特征:金融交易、实时竞价等对延迟敏感度极高的业务;
原因:无法接受任何性能抖动,全量加载模式更适配。
# 下载 Milvus 2.6.1+
$ wget https://github.com/milvus-io/milvus/releases/latest
# 启用 Tiered Storage
$ vi milvus.yaml
queryNode.segcore.tieredStorage:
warmup:
scalarField: disable
scalarIndex: disable
vectorField: disable
vectorIndex: disable
evictionEnabled: true
# 启动 Milvus
$ docker-compose up -d

郑卜千
Zilliz Senior Staff Software Engineer
文章来自于“Zilliz”,作者 “郑卜千”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
