ICML 2026|Agent通讯的「运营商」哪家强?UIUC团队发布ProtocolBench
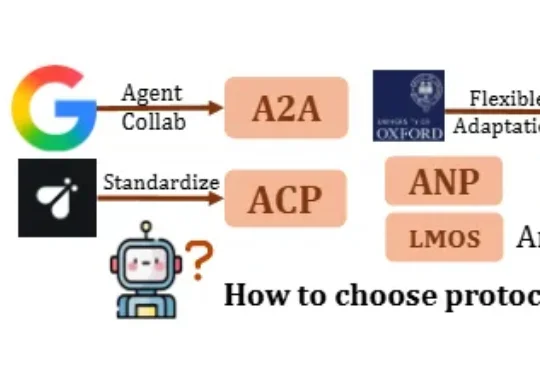
ICML 2026|Agent通讯的「运营商」哪家强?UIUC团队发布ProtocolBench多智能体系统正在从学界走向业界。 在 Coding、Research 等真实场景里,越来越多系统不再只依赖单个 agent,而是由多个 Agent 分工协作:有人负责规划,有人负责检索,有人调用工具,
来自主题: AI技术研报
8248 点击 2026-06-20 10:21
 搜索
搜索
多智能体系统正在从学界走向业界。 在 Coding、Research 等真实场景里,越来越多系统不再只依赖单个 agent,而是由多个 Agent 分工协作:有人负责规划,有人负责检索,有人调用工具,

过去两年,大模型写代码已经不再新鲜。从代码补全到 GitHub issue 修复,从竞赛编程到仓库级软件工程,人们习惯用一个简单标准评估 coding agent:代码能不能写对?测试能不能通过?

说在前面:这又是一篇讲Harness的Survey,你最近可能已经看过了数篇讲Harness的文章、论文,其中还可能包括我上周解读的《Agent Harness Engineering:Agent的底盘工程综述|CMU、耶鲁、Amazon》。

具身智能(Embodied AI)正在快速从实验室走向真实世界。
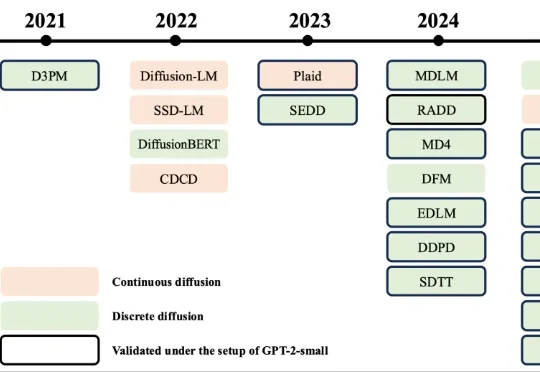
主要作者团队:Yuxin Chen 现为伊利诺伊大学厄巴纳 - 香槟分校(UIUC)硕士一年级学生,Chumeng Liang 为 UIUC 博士一年级学生,Hangke Sui 为 UIUC 博士二年级学生,Ge Liu 为 UIUC 计算机系助理教授。Liu Lab 团队长期聚焦扩散 / 流模型方向,

UIUC研究团队打造ResearchArcade,将ArXiv论文、OpenReview评审、图表代码等碎片数据连接成动态知识图谱。模型可直接学习引用关系、修改轨迹与审稿互动,让AI更好辅助科研写作、修订与预测,为下一代科研智能体奠定统一数据基础。
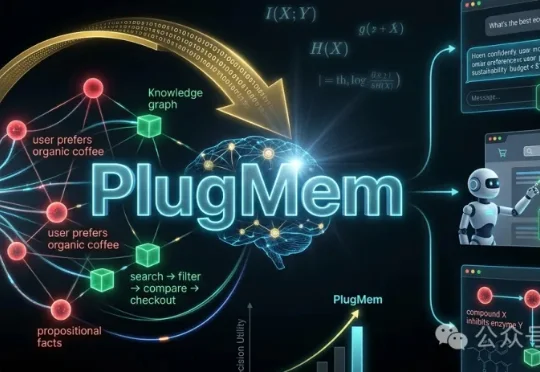
现在的AI agent往往把长交互历史直接存起来,但很难高效复用。最朴素的方法直接从「原始记忆」里检索,但常常把模型淹没在冗长、低价值的上下文里。PlugMem把经验转化为结构化、可复用的知识,并提出一个任务无关(task-agnostic)的统一记忆模块,在多种Agent基准上提升性能,同时消耗更少。

随着大语言模型 Agent 开始在对话、问答与复杂交互环境中长期运行,“记忆该如何设计” 正在成为一个绕不开的核心问题。
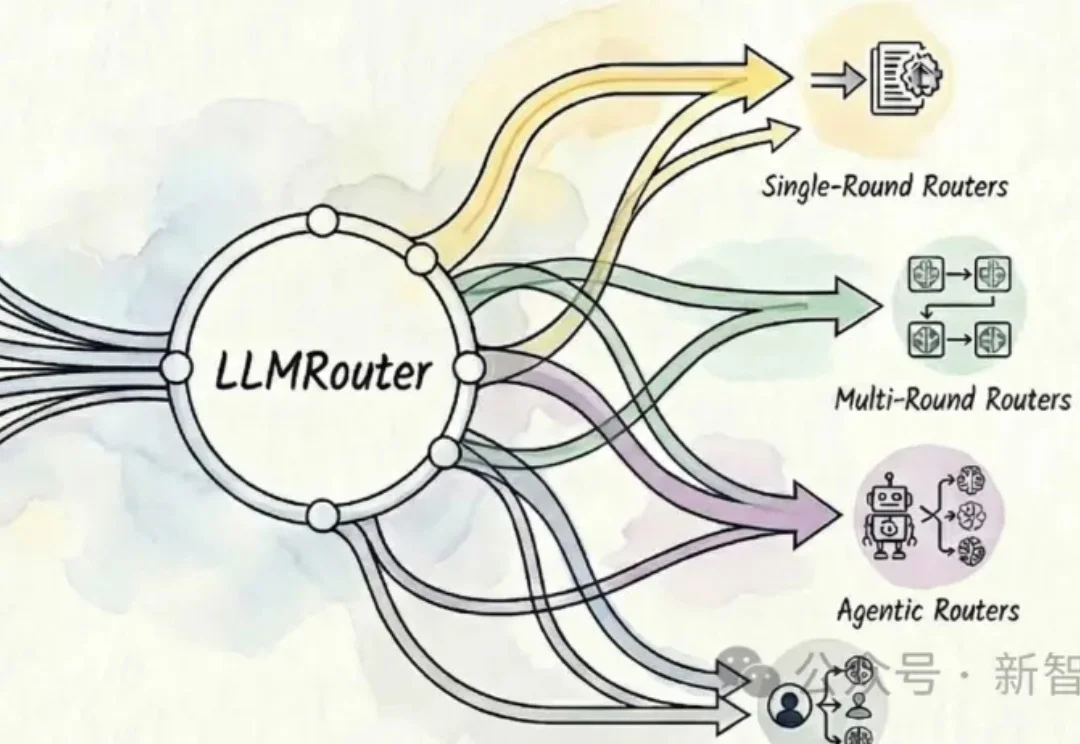
UIUC开源的智能模型路由框架LLMRouter可以自动为大模型应用选择最优模型,提供16+路由策略,覆盖单轮选择、多轮协作、个性化偏好和Agent式流程,在性能、成本与延迟间灵活权衡。

2025 年 1 月 20 日,DeepSeek 发布了推理大模型 DeepSeek-R1,在学术界和工业界引发了对大模型强化学习方法的广泛关注与研究热潮。 研究者发现,在数学推理等具有明确答案的任务