# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Paper link:https://arxiv.org/abs/2511.10984
Project link:https://github.com/ByteDance-Seed/DiscoX
Blog link: https://randomtutu.github.io/DiscoX/
Author:Xiying Zhao, Zhoufutu Wen, Zhixuan Chen, Jingzhe Ding, Jianpeng Jiao, Shuai Li, Xi Li, Danni Liang, Shengda Long, Qianqian Liu, Xianbo Wu, Hongwan Gao, Xiang Gao, Liang Hu, Jiashuo Liu, Mengyun Liu, Weiran Shi, Chenghao Yang, Qianyu Yang, Xuanliang Zhang, Ge Zhang, Wenhao Huang, Yuwen Tang
第一作者:字节跳动豆包大模型评测产品经理,研究方向为通用模型评测系统(General Model Evals System)。前AI行业PE/VC投资人,投资领域涵盖早期CV、NLP、自动驾驶到如今的AI算力芯片、大模型、AI应用与具身智能等前沿领域。具备学术与实践相结合的复合背景以及宏观行业趋势判断和微观模型产品洞察的独特视角。

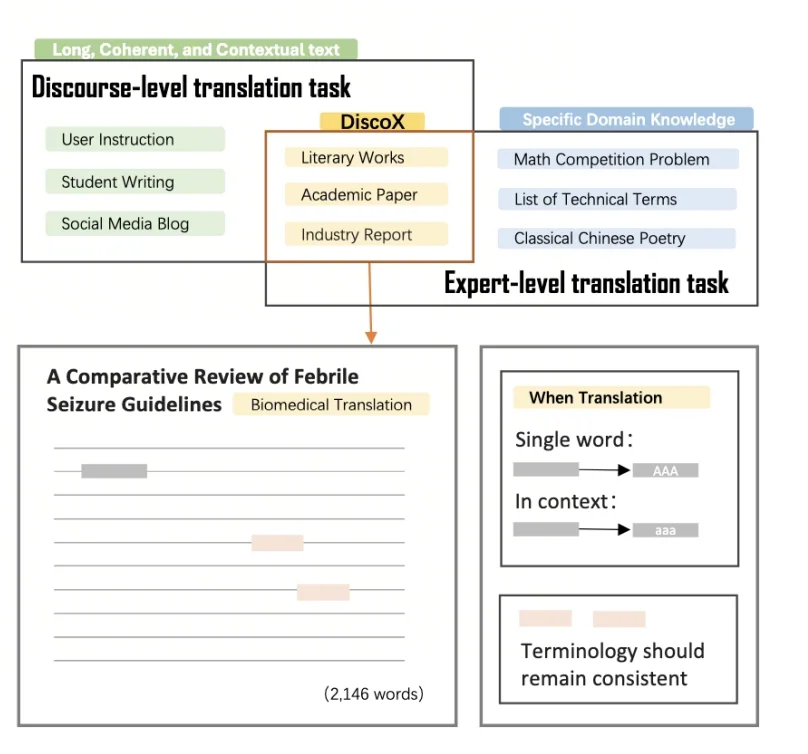
·测什么: DiscoX构建了一套200题的长文翻译数据集,以平均长度1,712 tokens的长篇章做评测单元,要求整个长文文本作为一个整体来翻译,除翻译准确度外,重点考察跨段落的逻辑与风格一致性、上下文中的术语精确性、以及专业写作规范,贴合用户真实的使用场景。
·怎么测:提出Metric-S,一个无需参考答案(No ref)、评估结果可解释的长文翻译评测框架,它是一个通过workflow编排的多个multi-agent形成的evals system,进行三个阶段的评估:
指令遵循检测:通过指令遵循检测,快速剔除无效回复,聚焦于有价值的评估对象。
翻译核心评估:在准确度、流畅度、得体性三大维度上,对译文进行全面质量打分。
计分优化:创新采用分层去重与归因机制,追溯错误根源,避免对同一错误重复扣分,使评分更公正、合理。
·优势点:
精准评估长文翻译,暴露模型翻译能力不足:DiscoX搭配Metric-S,可实现深入分析模型在处理长文翻译时的真实表现,提供详细的多维度评分。
结构化诊断归因,驱动精准优化闭环:Metric-S不仅仅提供分数,更提供术语、风格、衔接等细粒度归因,可以直接验证训练数据质量、引导后续模型优化。
解锁真实业务数据评测,减少人工标注成本:企业文档、新闻稿、学术论文翻译常常没有标准参考译文;采用无参考评测,解决业务数据缺乏标准译文的痛点,无需高昂的人工标注成本即可实现规模化评测。
对于一个赶 Deadline 的研究生来说,他们想要的其实很简单:让AI帮忙翻译一份拿来就能用的论文,这样就可以把精力分配到更重要的地方——改实验、写论证、赶投稿。
比起每个句子都翻译得天衣无缝,对使用大模型翻译的人来说,翻译出一个准确、连贯、流畅的文章,才更符合他们的需求,但现在AI模型真的满足人们在真实场景的需求了吗?
但实际使用场景中,你是不是经常遇到以下情况:
·明明是同一篇论文,同一个单词一会儿译成 A,一会儿译成 B,就得一遍一遍校对A和B是不是同一个概念。
·译文单看每个段落挺正常,连起来读就是让人云里雾里,有些地方逻辑特别混乱,得一遍遍回翻前文,确认到底在讲什么。
问题在于,传统的评测方式很难稳定地量化这些关键错误。
传统的翻译指标存在一个根本性的误区:它们将与参考译文的文本相似度等同于翻译的可靠程度。这种方法的缺陷在于,它对那些细微但重要的错误极其不敏感。
一篇译文可能在文本上与标准答案有高达 99% 的相似度,但仅仅一个关键错误——
·一个数字错译
·一个否定词的漏译(比如“不应该” 译为 “应该”)
·一个核心术语的误译
——就会导致其传达的信息就已与原文南辕北辙。这样的译文可能会引发严重后果。
因此,这些传统指标能告诉我们译文与参考译文像不像,却无法回答我们真正关心的、也更为关键的问题:这篇译文到底靠不靠谱?它传达的信息准确吗?我能放心地复制粘贴吗?
因此,DiscoX引入了篇章级评测(discource-level evaluation)的概念,把术语一致性、段落衔接、整体风格与专业写作规范等长文翻译里的关键能力纳入评估范畴。
在此背景下,DiscoX面向真实使用场景构建了一个长文翻译Benchmark:共 200篇中英双向长文本,平均长度约 1712 tokens,内容以真实场景下的文本为主,覆盖了:
·学术论文
·文学作品
·行业与垂类研究报告
DiscoX的题目不只是长度长,而是长度长+专业场景,更贴近真实使用场景中人们关心的——译文能不能直接放心使用。
·每条样本都配套对应领域专家撰写rubrics:明确了关键术语的翻译规范、经典表达的语境处理、文化负载词的得体翻译等。
·这使得评测不再停留在像不像参考译文,而是更接近真实交付中的问题:是否满足专业规范、是否能直接放心用。
在 DiscoX 基准及其配套评测下的实验结果进一步表明:当前主流大模型在以下方面仍存在显著短板:
·长文本语义一致性不足:术语在全文范围内难以保持前后一致
·上下文记忆与信息对齐能力不足:跨段落的逻辑关联容易断裂
·复杂语义与专业表达的稳定处理不足:面对高密度专业内容时更易出错
针对上述问题,研究团队提出了Metric-S。该方法并非简单地将传统指标从句子层面扩展到篇章层面,而是回溯人工专家的评审流程,采用LLM-as-Judge + Multi-agent的方式,模拟真实的人类专家评审逻辑。
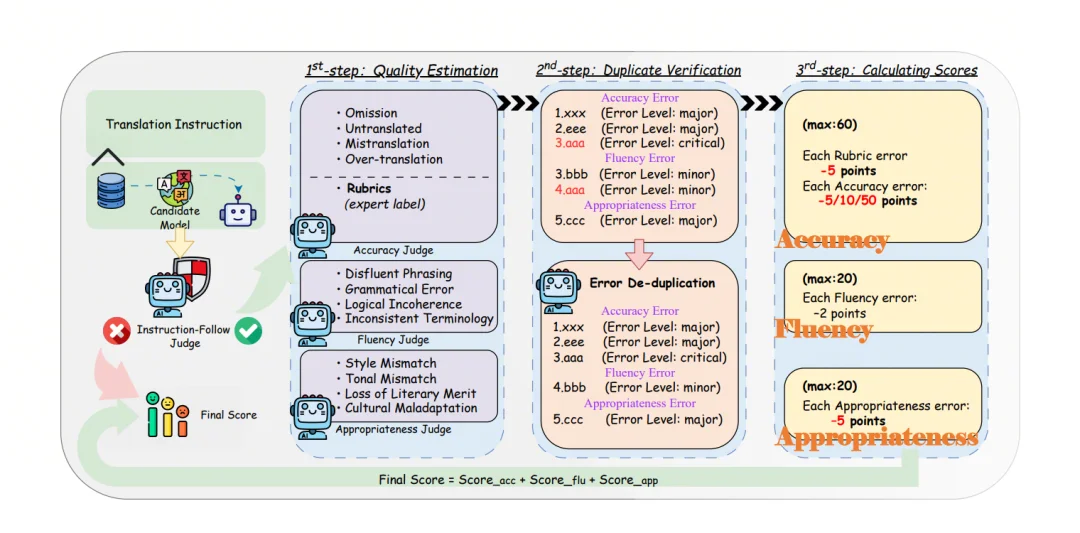
Metric-S 的评测流程可以理解为一条结构化的质检流水线:
·指令遵循预检(Instruction Following Check)
LLM的高自由度,也可能导致其在执行翻译任务时偏离指令。具体表现为,模型可能将翻译任务误解为内容续写、文本摘要等问题。这种情况下,按传统对比与标准答案相似度的方式,模型也可能命中部分词汇。但实际上并非在执行翻译任务。
为此,Metric-S 设计了指令遵循预检环节。该Metric会首先甄别模型输出是否为一篇真正的翻译译文,有效过滤掉无效输出。任何不满足预检要求的输出都将被直接判定为不合格,从而避免无效结果污染后续的评估流程,从源头上保证了评估的公正性。
·三维质量评估(Quality Estimation)
通过多个评测代理分别从三个维度对整篇译文进行检查并记录问题:
准确度(Accuracy):信息是否忠实、术语是否正确、关键含义是否被漏译/错译/增译;
流畅度(Fluency):目标语是否自然、读起来是否顺畅、表达是否一致;
得体性(Appropriateness):文体与语气是否贴合原文、文化负载表达是否处理得当。
·去重与归因(Deduplication & Attribution)
长文里一个根因错误常会引发多维度连锁反应,例如错译导致不通顺。Metric-S 设置了一个单独的 LLM-judge对评估结果进行独立评估,查看是否存在重复扣分情况。会对跨维度重复问题做归因,只给根本原因扣分,避免重复惩罚,使结果更公平、更稳定。
·量化打分(Scoring)
最终分数由三维度加权组成(Accuracy 权重60,Fluency与Appropriateness权重分别20),根据不同错误严重程度的个数进行扣分。其中,严重程度共分为 extremely critical/critical/major/minor四个档位。因此除总分外,metric-s 还会输出各维度分数与结构化的 error list。
这套evals system的优势在哪:
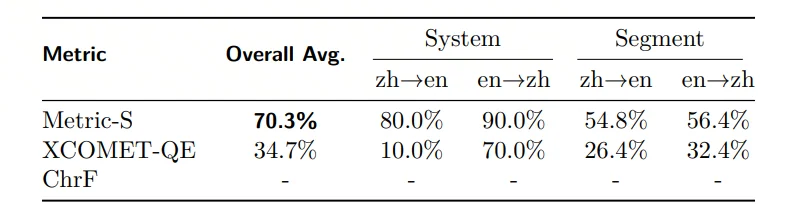
·在与human baseline的一致性(pairwise consistency),Metric-S得分70.3%,显著高于WMT 2024中处于SOTA地位的评估指标 XCOMET-QE(34.7%)。
·这一差距在不同语言对的综合偏序差异中尤其明显:
ozh→en 一致性 Metric-S 80.0% vs XCOMET-QE 10.0%。
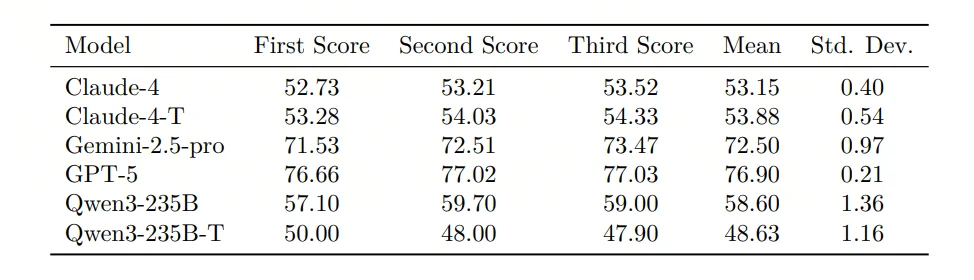
·论文对部分模型做了三次独立运行,均值/方差显示波动很小,例如 GPT-5 均值 76.90、3次均值差异0.21,用于证明输出与评测都较稳定。
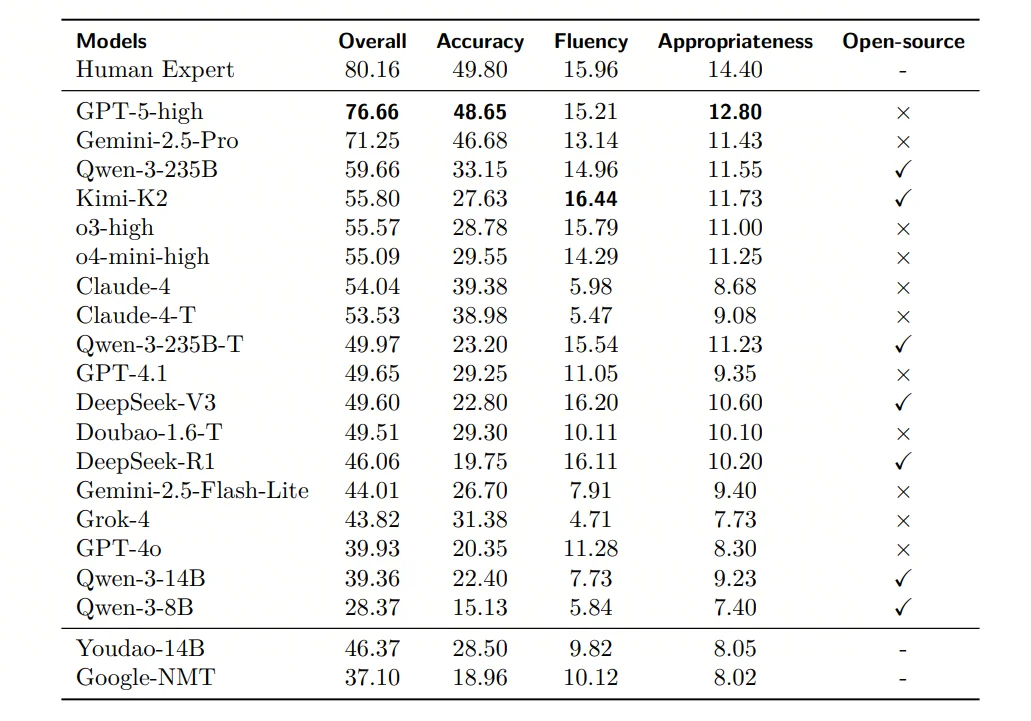
20 个具有代表性的模型在DiscoX上接受了全面评测。这些系统不仅涵盖了开源、闭源、领域模型及传统机器翻译 NMT 等多种类型,更囊括了在多个测评集上处于 SOTA 地位的模型GPT-5-high 与 Gemini-2.5-pro。
评测结果显示,作为SOTA的 GPT-5-high 取得了 76.66 的高分,但这与人类专家 80.16 的水平相比,仍存在差距。
这一显著的差距表明,高质量的篇章级翻译对当前的LLM而言,依然是一个极具挑战性的难题。
第一梯队(总体最强):GPT-5-high(76.66)> Gemini-2.5-Pro(71.25)。
开源模型里相对领先:Qwen-3-235B(59.66)、Kimi-K2(55.80)等。
传统 NMT 明显落后:Google-NMT Overall 37.10,低于多数 LLM。
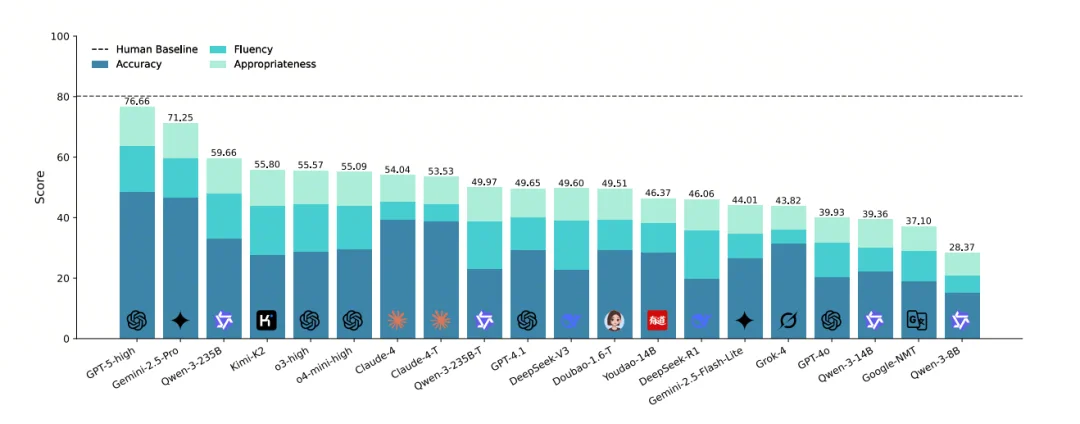
·论文发现不同模型在Accuracy/Fluency/Appropriateness上呈现不同优势。例如:
GPT-5在Accuracy上更强;
Kimi-K2在Fluency上更突出;
Claude-4 系列在Accuracy较高,但Fluency较弱。
文章来自于“Z Potentials”,作者 “Z Potentials”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
