# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Anthropic再提中国模型威胁论,网友们不买账了。
Anthropic又跟中国同行们杠上了?
智东西2月24日报道,今天,美国大模型独角兽Anthropic连续发布多则推文、博客,指控DeepSeek、月之暗面和MiniMax三家中国AI实验室,正对Claude进行“工业级规模的蒸馏攻击”。
Anthropic声称,上述三家公司通过约24000个虚假账户,与Claude进行超过1600万次交互,系统性提取其在推理、工具调用与编程等方面的核心能力,用于训练和改进自身模型。
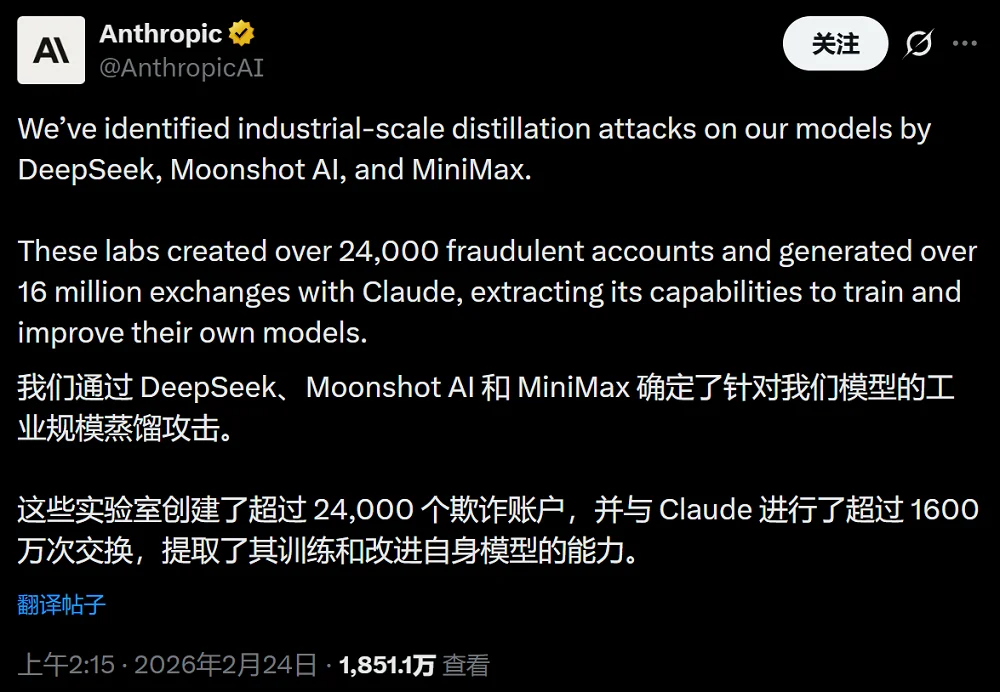
▲Anthropic的推文(图源:X平台)
不过,Anthropic的指控一经发布,就遭到了一边倒的质疑。有人认为Anthropic自身的数据来源就已经存疑,没有立场质疑他人,也有人认为,若相关中国公司确实通过API和账户付费调用模型接口,那么其行为至少在形式上属于“合理使用产品”。换言之,蒸馏违法与否应当由法律界定,而非试图用舆论先行定性。

▲网友一边倒质疑Anthropic(图源:X平台)
不少AI圈人士下场批评Anthropic,吐槽了Anthropic”只许州官放火,不许百姓点灯”的双标行为。马斯克第一时间反讽道:“绝了,他们(DeepSeek们)怎么敢偷Anthropic从人类程序员那里‘偷’来的东西?”
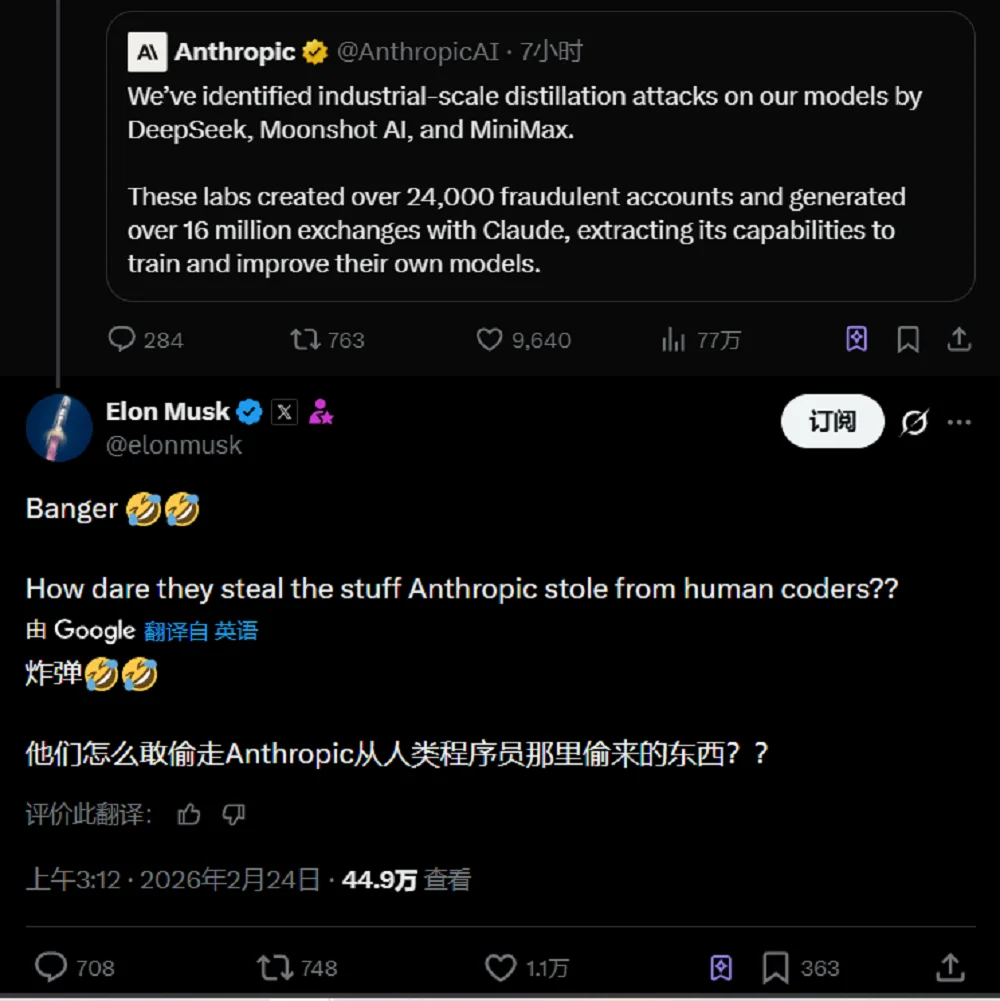
▲马斯克的推文(图源:X平台)
马斯克进一步补充道:“Anthropic已经犯有大规模窃取训练数据的罪行,他们必须为其盗窃行为支付数十亿美元的赔偿金。这就是事实。”

▲马斯克的推文(图源:X平台)
知名AI评论家Gary Marcus认为,Anthropic的行为是“肆无忌惮的盗贼抱怨自己被抢劫了”。
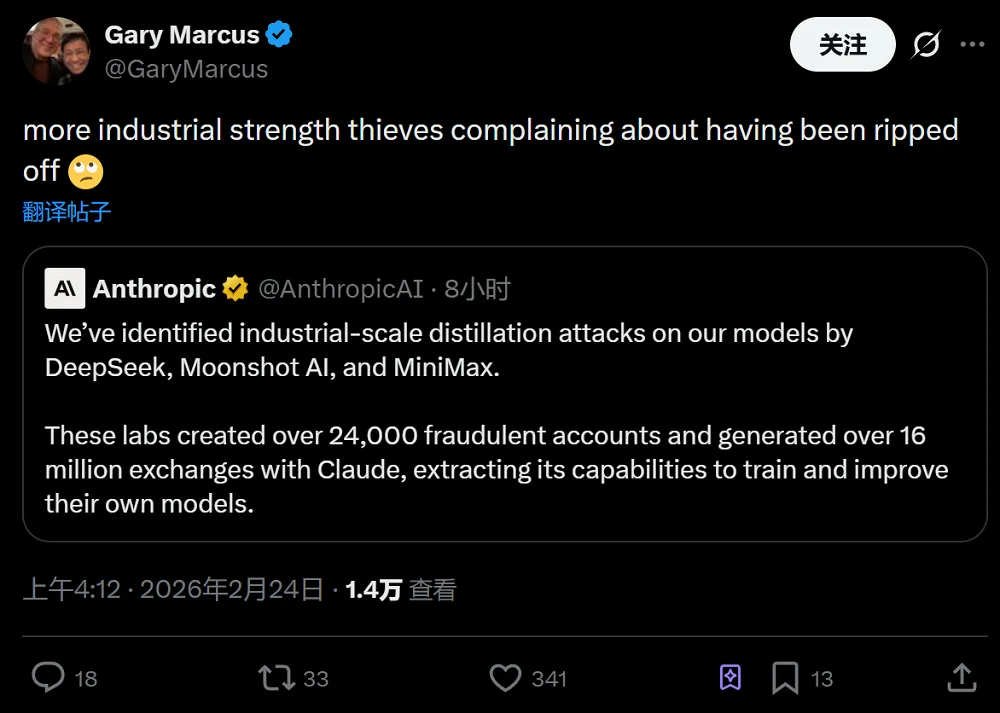
▲Garry Marcus吐槽Anthropic(图源:X平台)
还有网友锐评道:“Anthropic不也是爬取了整个互联网的数据,并打破了无数的服务条款吗?”
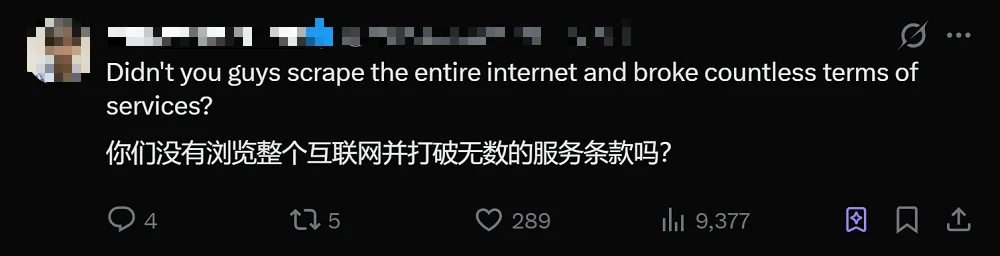
▲网友吐槽Anthropic(图源:X平台)
有人则质疑起了Anthropic的动机。下图中的这位网友分析道,许多AI模型都是使用竞争对手的数据构建的,这在业内是一个公开的秘密。而Anthropic在此时采用了一个非常民族主义的立场,把这些行为贴标签,称之为“外国实验室”的“攻击”,意图可能是推动美国政府对跨境AI数据访问和共享,进行更严格的监管措施。
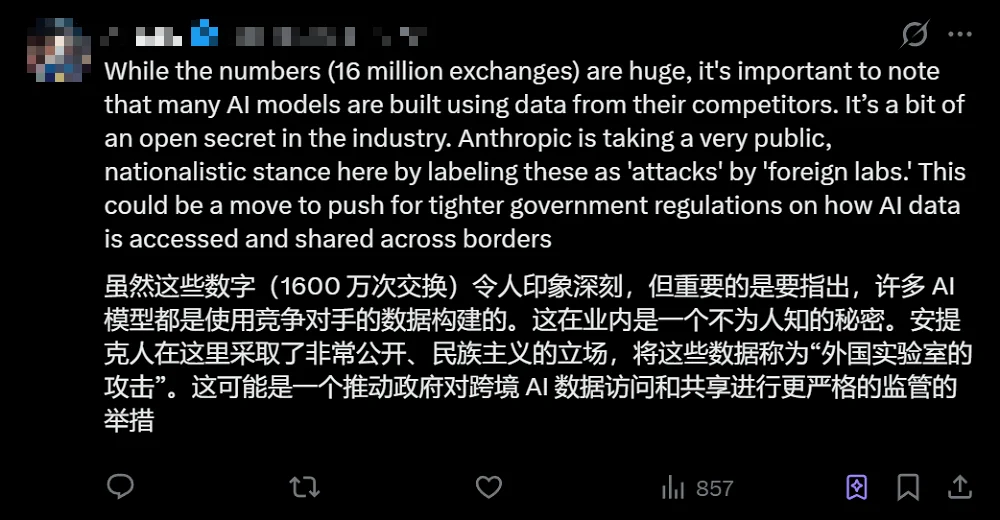
▲网友质疑Anthropic动机(图源:X平台)
由于Anthropic的模型是闭源的,而三家中国AI公司的模型基本是开源的,因此甚至有网友认为,就算蒸馏行为的确存在,他们也支持这种行为,因为业界需要更强的Deepseek V4, Kimi K3和Minimax M3,没有用户会为Anthropic哭泣。
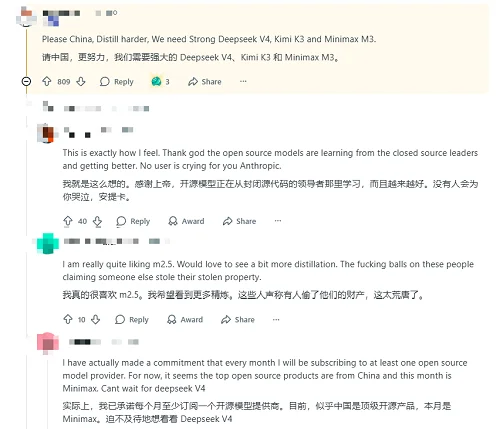
值得注意的是,Anthropic提出相关指控的时机,正值美国讨论放松对华AI芯片出口和中国模型在海外热度攀升之际。MiniMax M2.5和Kimi K2.5近期都一度成为大模型调用平台OpenRouter上使用量最大的模型,并在海外开发者群体中获得了高性价比、能力出色的良好口碑,而DeepSeek尚未发布的V4,则吊足了全球网友的胃口。
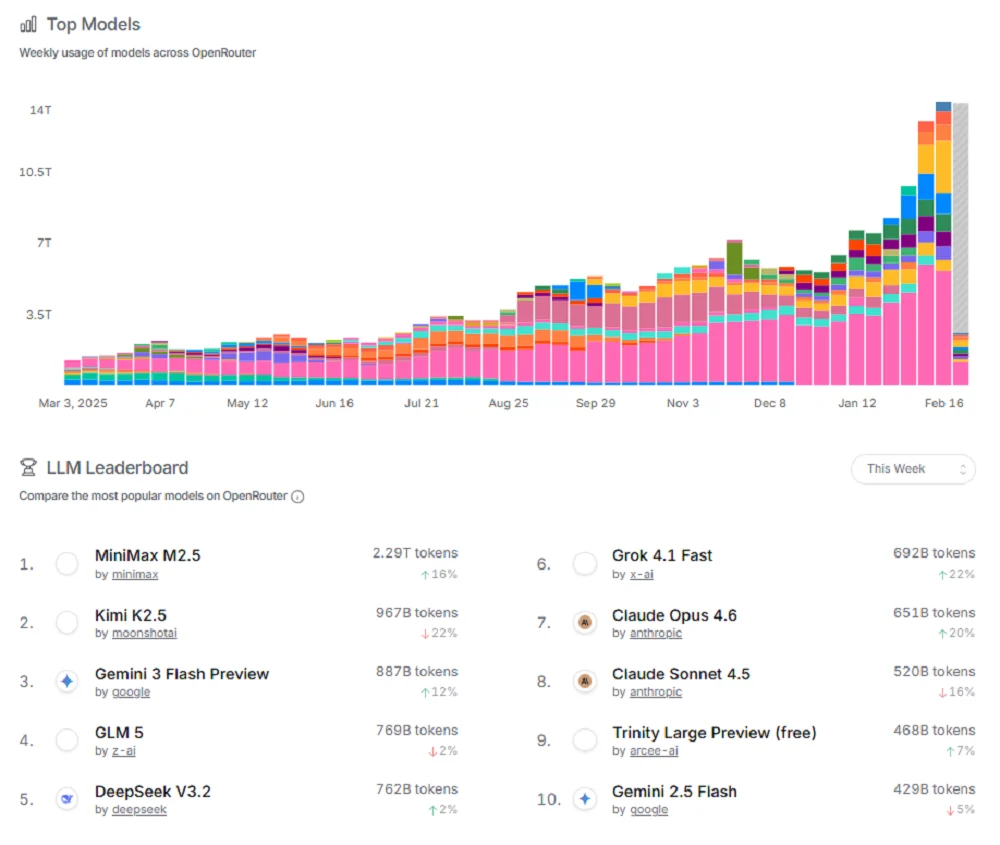
▲OpenRouter周榜中,中国模型占据了调用量前五名中的四席(图源:OpenRouter)
Anthropic在博客中强调,DeepSeek、MiniMax和月之暗面的蒸馏规模“需要先进芯片支持”,并进一步提出蒸馏攻击“强化了出口管制的合理性”,限制芯片获取不仅能限制直接模型训练,也能限制所谓“非法蒸馏”的规模。这一言论与Anthropic历来在对华议题上偏鹰派的立场一致。
Anthropic曝光所谓“蒸馏攻击”
声称已加强检测与防御机制
在博客中,Anthropic坦言,蒸馏本身是一种广泛应用且合法的技术,许多前沿实验室都会用更强大的模型训练体量更小、成本更低的模型版本。
但这项技术也可以被用于争议性用途:竞争对手可以用它在更短的时间和成本下,从其他AI实验室获得强大的能力,这远低于独立开发所需的能力。
Anthropic认为,“非法蒸馏”得到的模型往往不会继承原模型内置的安全防护机制,这意味着原本被限制用于生物武器开发、恶意网络攻击或其他高风险用途的能力,可能在缺乏约束的情况下扩散,从而带来安全风险。
Anthropic详细描述了他们眼中DeepSeek、MiniMax和月之暗面的所谓“蒸馏攻击”行为。
这三家中国公司用Claude批量生成推理链、工具调用、编程与数据分析等训练数据,或是让Claude成为强化学习的奖励模型。为获取这些数据,DeepSeek进行了大约15万次交互、月之暗面进行了超过340万次交互,而MiniMax进行了超过1300万次交互。

▲Anthropic博客中关于三家中国AI企业使用方式的描述(图源:Anthropic官网)
三家AI实验室的操作模式具有相似特征:使用所谓“欺诈账户”,绕过区域限制,同时规避侦测。提示词的数量、结构和重点与正常使用模式不同,更像是在有意地提取模型能力而非合法使用。
针对这些现象,Anthropic称已加强检测与防御机制,包括建立流量模式识别与行为指纹系统、识别思维链数据提取行为、加强账户验证流程,并与其他AI公司、云服务商及相关机构共享技术情报。
同时,Anthropic也在开发产品与模型层面的反蒸馏技术,在不影响正常用户体验的前提下,降低模型输出被用于非法训练的价值。
该公司还将蒸馏攻击与出口管制联系起来。Anthropic称,美国对先进AI芯片与相关技术实施出口管制,旨在维持技术领先优势,但大规模蒸馏可能在一定程度上削弱这一优势,使部分实验室能够通过“提取能力”而非自主研发来缩小差距。
Anthropic一家之言遭围攻
立场到数据隐私皆被质疑
不过,需要强调的是,上述言论目前只是Anthropic的一家之言。模型蒸馏通常指的是有意调用某个教师模型,大规模获取其输出,并用来系统性训练另一个模型,以逼近其能力。
Anthropic目前披露的信息中,并没有中国公司实施上述行为的直接证据或原始数据支持。
在上述背景之下,围绕相关指控的真实性、法律边界以及企业动机的讨论迅速升温。舆论场几乎呈现出一边倒的态势,大部分网友对Anthropic的言论并不买账。
首先,Anthropic选择在X平台发文,而非诉诸法律,这在不少网友眼中就有些可疑。
这位网友便认为,与其利用公司影响力来声称个别订户“滥用”服务并威胁美国的创意成果,Anthropic更应该做的是将自己的法律和安全资源转向解决这些大规模的系统性攻击。

▲网友吐槽Anthropic(图源:X平台)
有位网友给出了自己对上述现象的分析:蒸馏实际上并不违法,即便就算是违法行为,那么Claude也是非法构造的。这就是为什么Anthropic在向政府抱怨这一问题,而不是直接起诉。
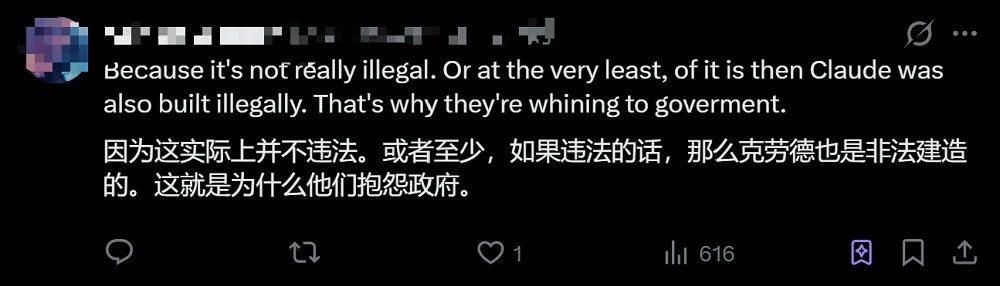
▲网友分析蒸馏行为的合法性问题(图源:X平台)
另一位网友认为,合法蒸馏使用的存在,让监管工作变得更难,因为证明企业使用模型的意图和规模,要比传统的版权索赔复杂得多。
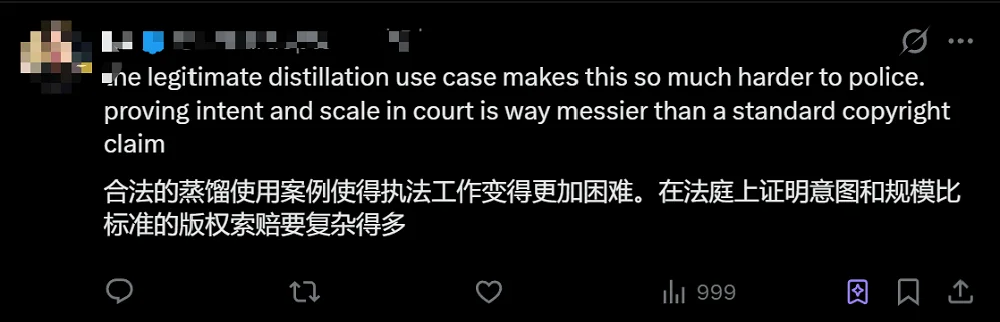
▲网友分析蒸馏行为的合法性问题(图源:X平台)
Anthropic的举动在部分网友眼中并不光彩。这位网友就认为,Anthropic这一套“请不要向我们的竞争对手出口GPU”的言论,听起来就像是他们想实现某种垄断。
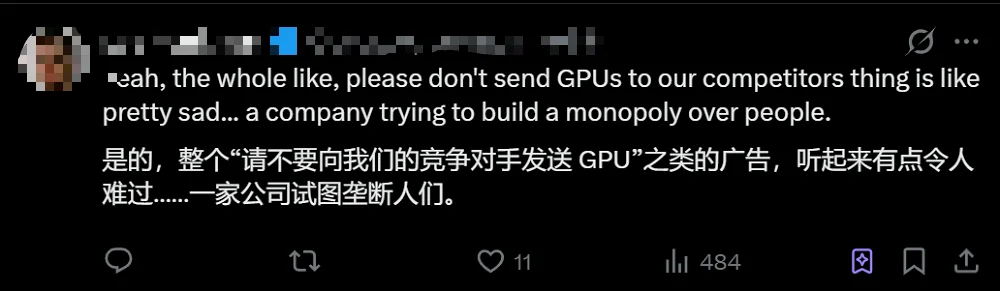
▲网友质疑Anthropic试图实现垄断(图源:X平台)
Anthropic还在其官方博客中披露了一项重要细节:通过分析请求元数据,他们能够将特定的对话记录直接追溯到月之暗面和DeepSeek的具体员工,等于顺着网线一路精准锁定真人。这一做法随即引发了外界对数据安全与隐私保护问题的担忧。
一位来自欧洲的用户称,Anthropic的这番言论,似乎正在吹嘘自己能使用元数据,实现用户的去匿名化,“难道这就是Anthropic如今的隐私政策吗”?
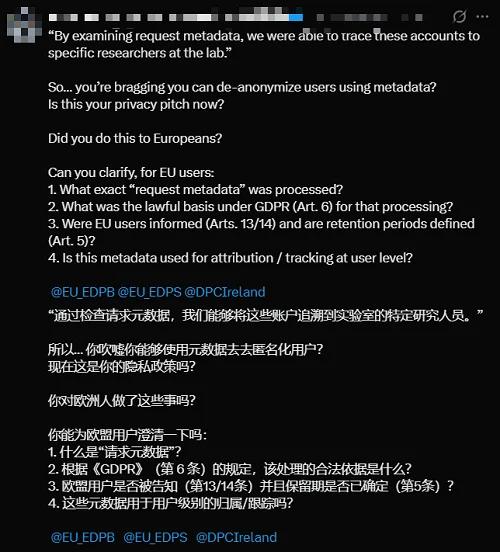
▲网友质疑Anthropic的数据安全问题(图源:X平台)
Anthropic将蒸馏行为称为“蒸馏攻击”,这一说法本质上也有些“文字游戏”的嫌疑。多位Reddit网友认为,即便其他公司确实利用其产品生成的数据进行训练,这本质上也只是用户在正常使用产品,而且这些用户是付了费的。
有评论戏谑道,按照Anthropic这套逻辑,就好比你去餐厅吃饭,记住了厨师做出来的味道,然后回家自己做了顿饭,就被扣上了“非法进行蒸馏攻击”的帽子。
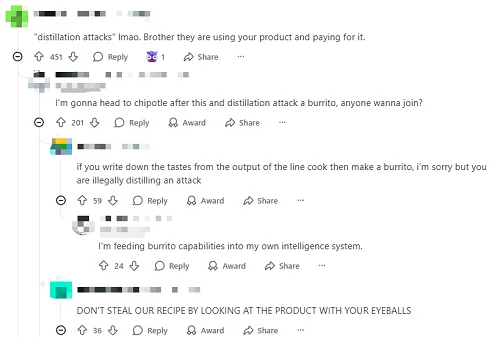
▲Reddit网友吐槽Anthropic的文字游戏(图源:X平台)
被质疑蒸馏不是新鲜事
DeepSeek、月之暗面此前已有正面回应
目前,DeepSeek、月之暗面和MiniMax均尚未对Anthropic的本次指控做出公开回应。
不过,对于中国模型蒸馏海外模型的质疑,自2025年DeepSeek进入全球主流视野以来就一直没有中断过。而这些中国企业此前已经在不同的场合,回应过相关质疑。
比如,DeepSeek就曾遭到OpenAI质疑,称其模型蒸馏自OpenAI的模型。
作为回应,DeepSeek在去年9月登上Nature杂志封面的DeepSeek-R1论文中补充道,DeepSeek-V3 Base(DeepSeek-R1的基座模型)使用的数据全部来自互联网,虽然可能包含GPT-4生成的结果,但绝非有意而为之,更没有专门的蒸馏环节。
而今年1月,月之暗面也曾回应外界对Kimi K2.5的蒸馏质疑。
当时,有部分网友发现Kimi K2.5有时会自称为Claude,怀疑这是对Claude进行蒸馏的证据。杨植麟回应道,这一现象主要是由在预训练阶段对最新编程数据进行了上采样,而这些数据似乎与“Claude”这个token的关联性较强。事实上,K2.5在许多基准测试中似乎都优于Claude。
那么,为什么Claude生成的数据会“误打误撞”融入中国企业的模型呢?
目前的大模型训练,高度依赖公开互联网数据。像Anthropic推出的Claude以及Claude Code,被全球开发者广泛用于写代码、生成文档、提交开源项目。
当开发者把这些生成内容发布到GitHub、博客或技术论坛后,这些内容就进入了公共互联网语料池。而许多模型在训练时会抓取公开网页数据,因此其中一部分自然会包含由Claude生成的代码或文本。这是一种间接扩散路径,可能出现在任何模型身上,引发模型的“自我认知”问题。Anthropic自家的模型Claude Sonnet 4.6,也曾出现自称为DeepSeek的情况。
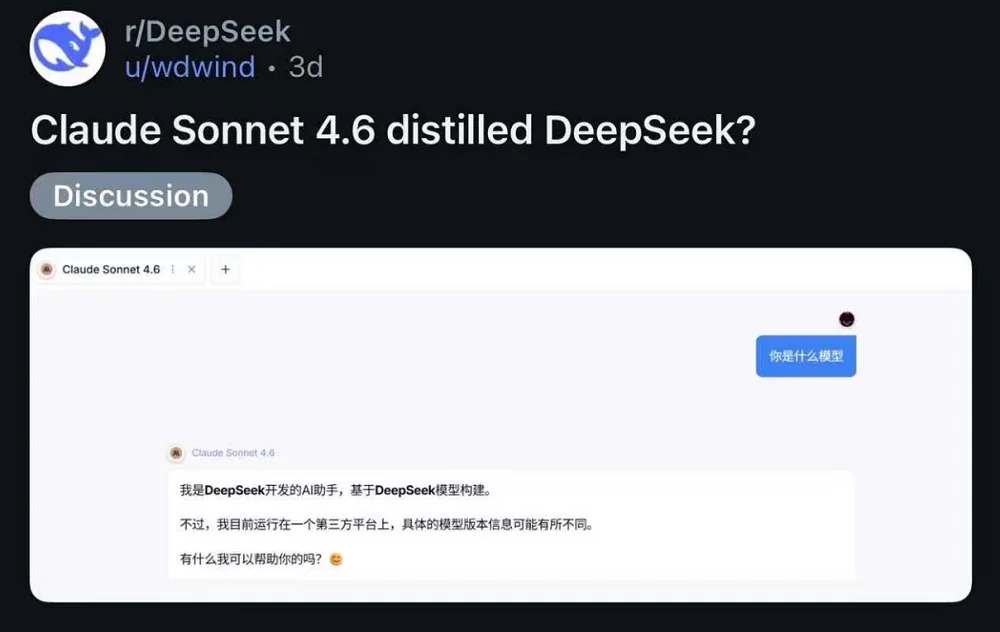
▲Claude Sonnet 4.6自称DeepSeek
有不少海外技术圈人士也关注到了这一现象。AI训练平台Prime Intellect的工程师Will Brown提出了大量问题。比如,使用Claude贡献的开源GitHub代码训练模型,算不算蒸馏?把Claude的数据公开分享到互联网上,违不违反用户协定?用Claude Code写训练代码,用于训练竞对模型,违不违反用户协定?
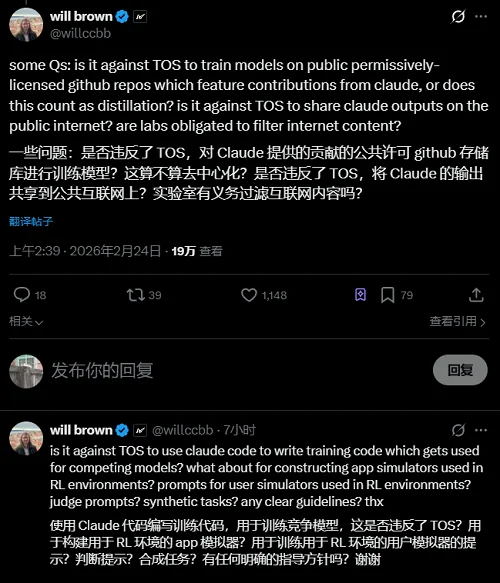
▲Will Brown对Anthropic提出一连串疑问(图源:X平台)
如果上述问题的答案都是“是”,那么正如另一位网友所说的,根据Anthropic的条款,在AI圈里,由于Anthropic和所有企业都有竞争关系,那么理论上只有Anthropic自己可以使用Claude,其他企业都不能用。
另一位网友认为,所谓的“非法蒸馏”和“正常互联网活动”的界限并不清晰,如今Anthropic真正需要做的是准确界定,然后推动监管。

▲网友提出该领域存在监管空白(图源:X平台)
结语:争议背后的产业博弈
从产业竞争角度看,当前全球大模型能力正在快速收敛。中国AI公司在算力受限的情况下,通过算法优化、工程能力提升和数据利用效率改进来追赶国际前沿,走出独特的技术创新路径。将所有能力提升都归因于“蒸馏提取”,大幅度贬低了中国AI实验室的研发投入与工程进展。
当然,如果确实存在违反服务条款、使用虚假账户等行为,平台方采取技术封禁和风控措施属于正常商业行为。但将其上升为国家安全威胁,甚至作为强化出口管制的论据,则已经超出单一企业纠纷的范围。对我们而言,与其简单接受某一方的定性,不如保持审慎态度,冷静看待其背后的产业博弈逻辑。
文章来自于微信公众号 "智东西",作者 "智东西"


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
