# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
由于缺少对运行逻辑的解释,大模型一向被人称为「黑箱」,但近来的不少研究已能够在单个神经元层面上解释大模型的运行机制。
例如Claude在2023年发表的一项研究,将大模型中大约500个神经元分解成约4000个可解释特征。
而10月28日的一项研究,以算术推理作为典型任务,借鉴类似的研究方法,确定了大模型中的一个模型子集,能解释模型大部分的基本算术逻辑行为。

论文地址:https://arxiv.org/abs/2410.21272
该研究首先定位了Llama3-8B/70B, Pythia-6.9B及GPT-J四个模型中负责算术计算的模型子集。
如图1所示,少数注意力头对大模型面对算术问题的正确率有显著影响。第一个 MLP(多层感知机) 明显影响操作数和操作符位置,而中间层和后期层的 MLP 将token信息投影到最后位置,提升正确答案的出现概率。
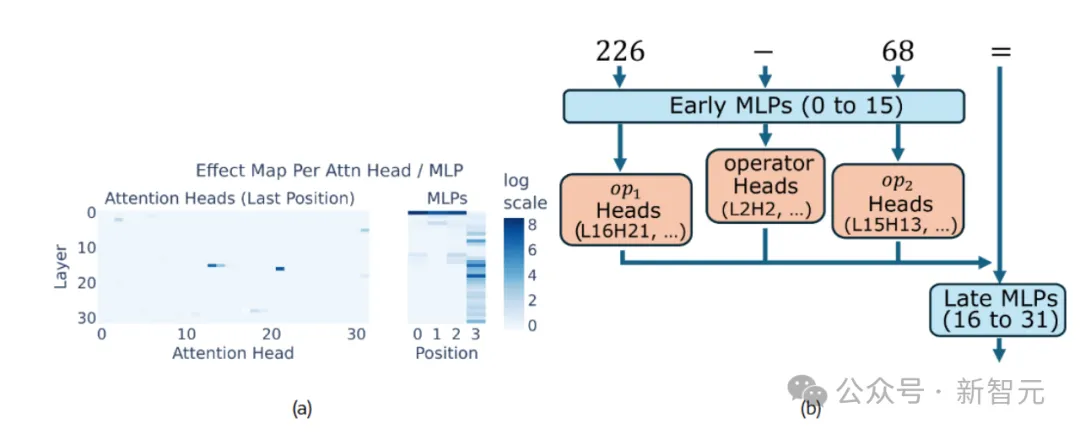
图1:Llama3-8B中发现算术相关的模型子集
该研究聚焦于单个神经元层面,发现了一组重要的神经元,它们实现了简单的启发式算法。只需要关注特定的极少量神经元,就能正确预测大模型进行算术运算的结果(图2)。
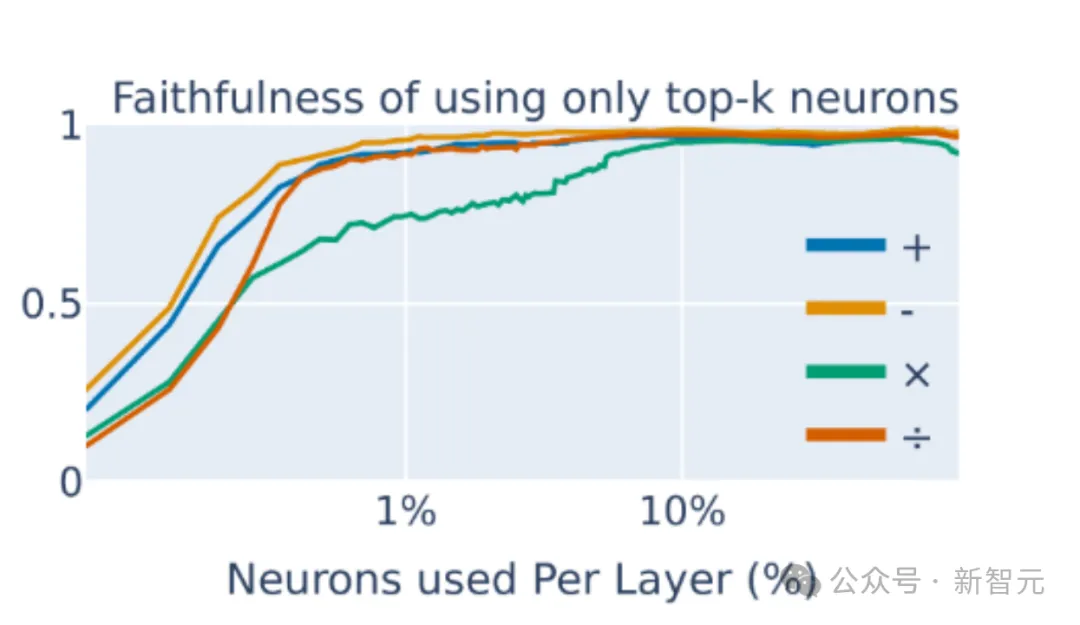
图2:大模型中每层神经元中只需要关注1.5%的少数子集,就能预测大模型进行四则运算的结果
举个例子:当输入的提示词为“ 226−68= ”时,神经元24|12439在结果介于150和180的减法提示下显示出高激活值,可被视为一个启发式算法。而每个启发式算法识别一个数值输入模式,并输出相应的答案。
具体可分为两种不同的激活模式:第一种直接启发式指的是在某些神经元中,激活模式取决于两个操作数,值向量编码了算术计算的预期结果(图 3b,c)。
第二种间接激活模式取决于单个操作数对应的神经元中,值向量通常编码下游处理的特征,而不是直接的计算结果(图3a)。
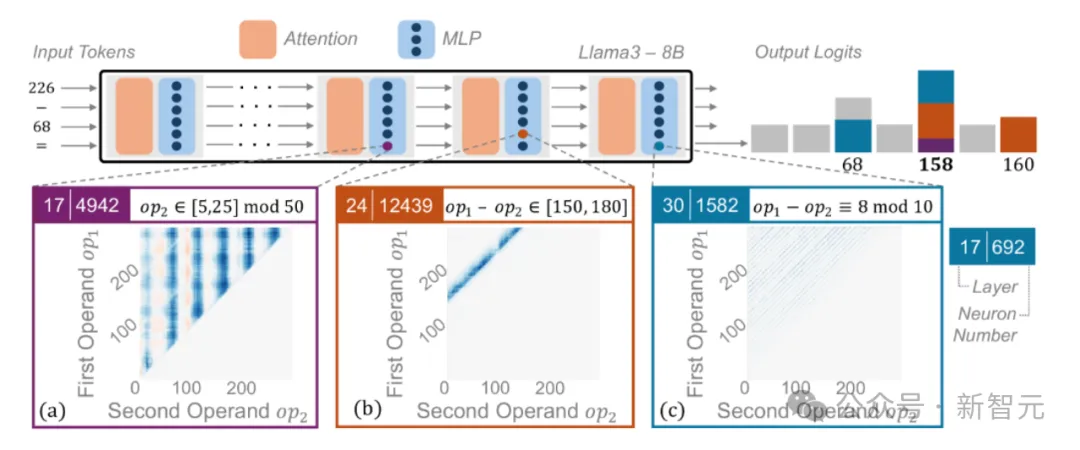
图3:启发式方法的可视化
该如何确认特定神经元和相关数学运算之间存在因果关系?一种常见的方法是消融分析,即将大模型大模型中特定的神经元敲除,看看模型的效果会有何改变,结果如图4所示。
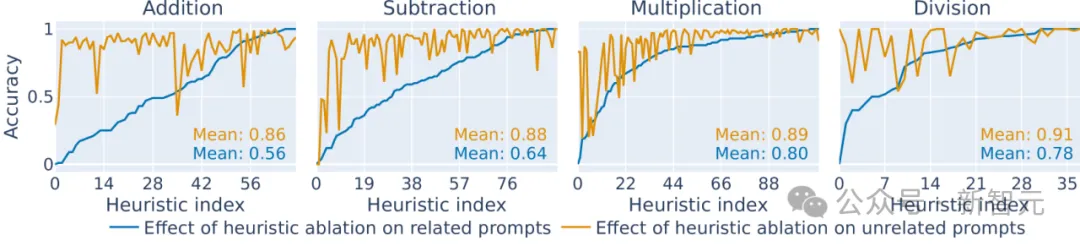
图4:四则运算中敲除对应的算术神经元后模型的性能对比
去掉了对应神经元后,模型的运算准确性无论加减乘除都显著下降。
不仅如此,相比去除特定算术神经元时造成的性能下降,可以发现,去除随机神经元的影响相对较小,而且这种效应在模型8B和70B不同参数量中普遍存在。
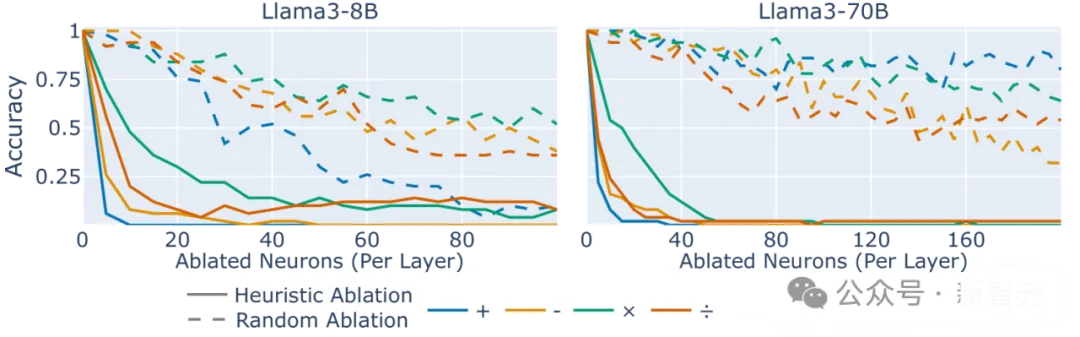
图5:敲除与算术相关的启发式算法的神经元(实线)相比与算术无关的相同数量的随机神经元(虚线)
上述结果表明,可仅根据其相关启发式算法来识别对特定对大模型进行算术重要的神经元,也证明了属于几个启发式算法的神经元与提示正确完成之间的因果关系。
此外,该结果还支持了启发式算法集合的主张:即每个启发式算法仅略微提高正确答案的几率,但它们结合在一起,使得大模型以高概率产生算术题的正确答案。
Llama3-8B模型无法可靠地对每道算术题时给出正确的回答。基于启发式规则,该研究阐述了模型为何会做错,可能的机制共有两种:
第一,由于参数量的限制,大模型缺乏足够的算术神经元,无法针对每一种情况都给出应对。
第二种原因是,可能存在回忆不完整的情况,比如某个启发式规则对应的神经元没有在运算时被触发。

图6:随机抽取了50个正确完成和50个错误完成的算术题目,考察大模型中被正确和错误激活的算术神经元个数
如图6所示,在大模型回答正确及错误时,激活的算术神经元个数不存在差异,这不支持前述的第一种算术神经元个数不足的假设。
然而,在大模型回答正确的情况下,更多比例的正确神经元被激活了,而回答错误的案例中,应当被激活的神经元激活概率反而较小。
这意味着大模型在特定算术题上失败的主要原因是对能得出正确答案的神经元缺少泛化能力,而不是算术神经元的数量不足。
由于其训练检查点可供公众获取,该研究采用Pythia-6.9B来考察大模型过程中算术神经元的出现阶段。
结果显示,大模型在训练过程中逐渐发展其最终的算术启发式机制,且算术神经元在模型训练早期就已出现。
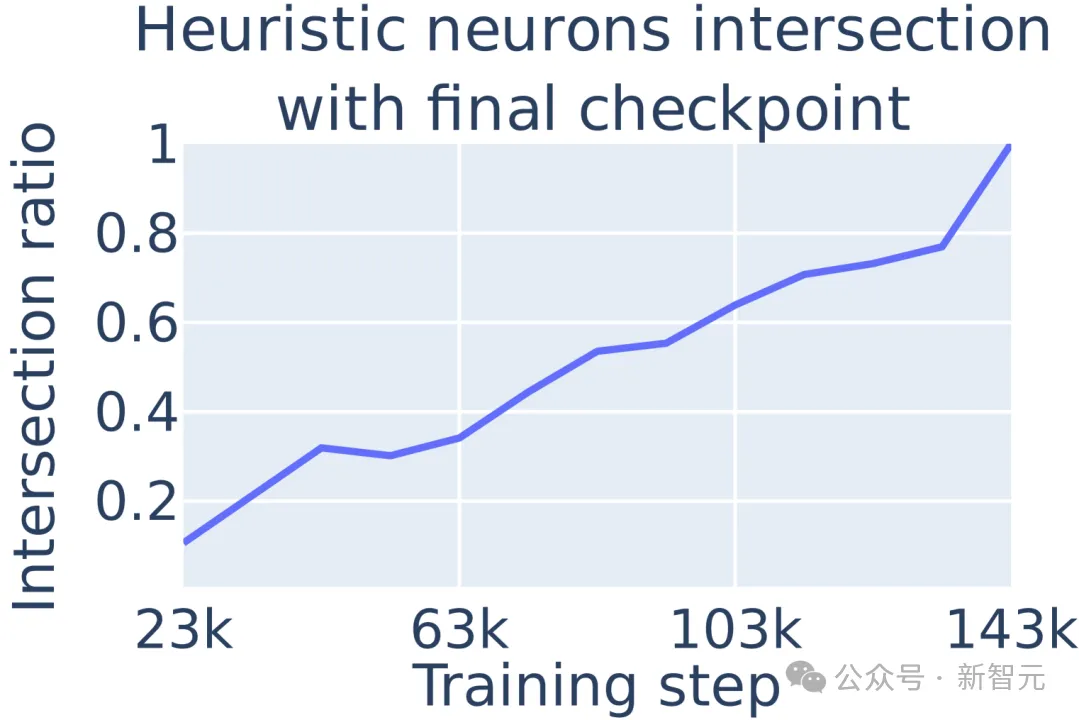
图7 :启发式的算术神经元的百分比随着训练增加
在模型训练的不同阶段,移除特定的启发式神经元会大幅降低模型在所有训练检查点的准确性,这表明算术准确性主要来自启发式,即使在早期阶段也是如此。算术启发式神经元与大模型算术能力的因果关系在整个训练过程中都存在。
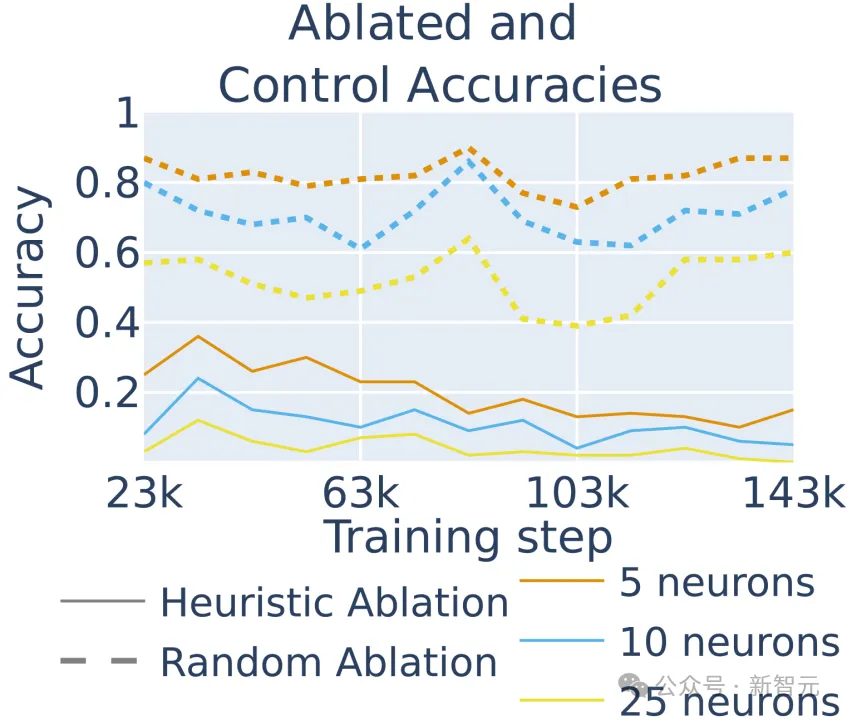
图8:不同阶段敲除算术神经元对大模型进行算术运算准确性的影响
理解大模型如何进行数学运算,不仅可以打开大模型内部运行的黑箱,解释它们为何在简单的数学题上翻车,例如最著名的「9.11和9.8哪个大」。
这项研究告诉我们,并不是因为大模型缺少相关训练,而是激活了错误的启发式神经元,例如将这个问题当成了询问哪个版本更大。
理解了大模型的算术运算,是依赖于启发式方法集,而非单纯的依靠记忆(背题目)或学会规则,这表明提高大模型的数学能力可能需要训练和架构的根本性改变,而不是像激活引导这样的小修小补。
对训练过程的分析结果指出,大模型在训练早期就学会了这些启发式方法,并随时间推移逐渐强化。这可能会导致模型过度拟合到早期的简单策略,因此可作为之后优化方向的参考。
参考资料:
https://arxiv.org/abs/2410.21272
文章来自于“新智元”,作者“peter东 乔杨”。




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
