
我们开源了一个可以降低 AIGC 率的模型
我们开源了一个可以降低 AIGC 率的模型最近到了毕业季,好多朋友来找我聊一件事:有什么办法帮他降 AIGC。
来自主题: AI技术研报
9758 点击 2026-05-27 09:24
 搜索
搜索
最近到了毕业季,好多朋友来找我聊一件事:有什么办法帮他降 AIGC。

Code Arena最新放榜,Qwen3.7-Max以1541分冲进全球第四,成为前五中唯一的非Claude模型。编程,中国模型第一次杀到这个位置。

多模态Agent最容易制造的一种错觉是:它看过图片,所以它记住了图片。

说在前面:这又是一篇讲Harness的Survey,你最近可能已经看过了数篇讲Harness的文章、论文,其中还可能包括我上周解读的《Agent Harness Engineering:Agent的底盘工程综述|CMU、耶鲁、Amazon》。
你的电脑里,或许很快会住进一只会聊天的「小怪兽」。
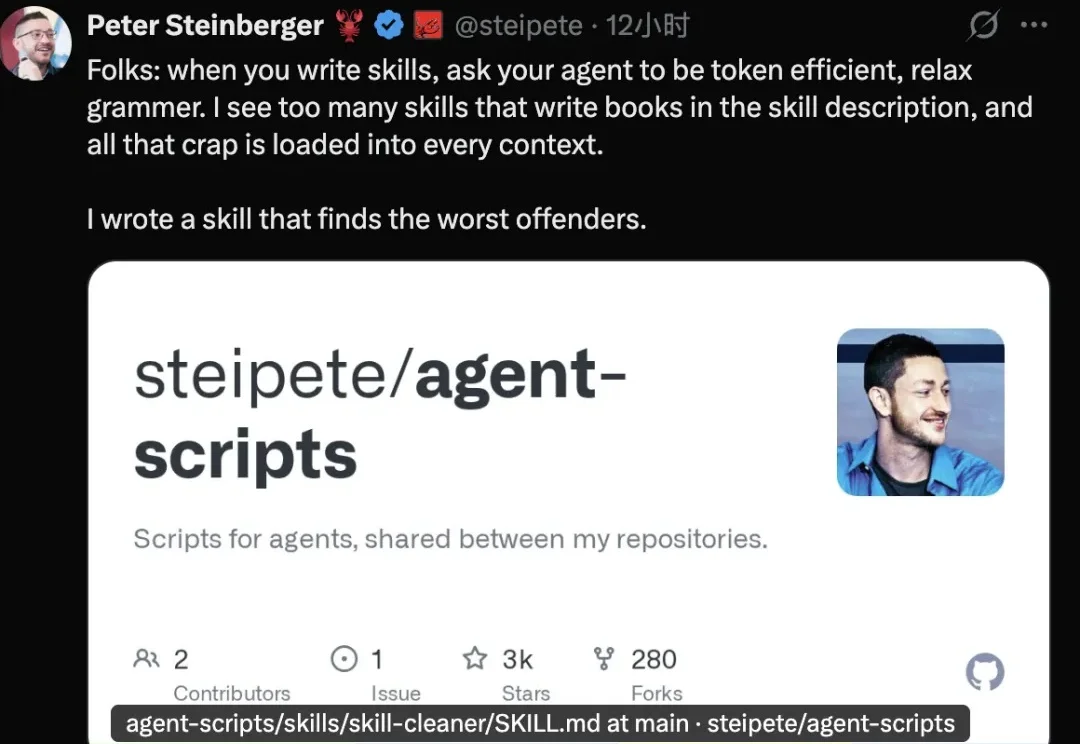
Skill水平参差不齐,龙虾之父Peter看不下去了。

英伟达世界动作模型 DreamZero 训练一次要烧 8 张 H100 整整 25 天,RLinf 从算子融合到 I/O 全链路系统级重构,把训练吞吐拉高近 4 倍——1 个月的活,1 周就能干完。

造AI这件事,现在的主角变成了AI。

“我语言的局限,即意味着我世界的局限。”( Die Grenzen meiner Sprache bedeuten die Grenzen meiner Welt. )

机器人看得见,但不一定看得准。
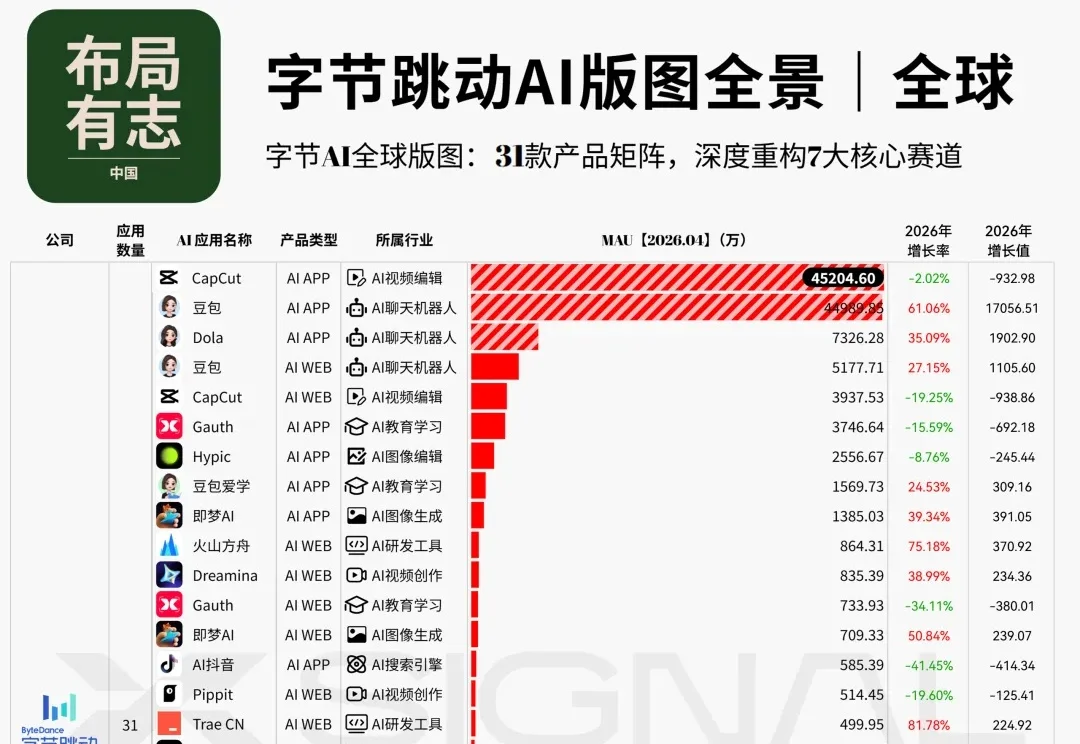
字节跳动计划在今年将其在人工智能基础设施上的支出大幅提升惊人的25%。这意味着将投入2000亿元人民币,这可不是一个边缘性的微调,是一次由不断升级的存储芯片成本以及字节跳动想要主导AI领域的雄心共同推动的巨大升级。
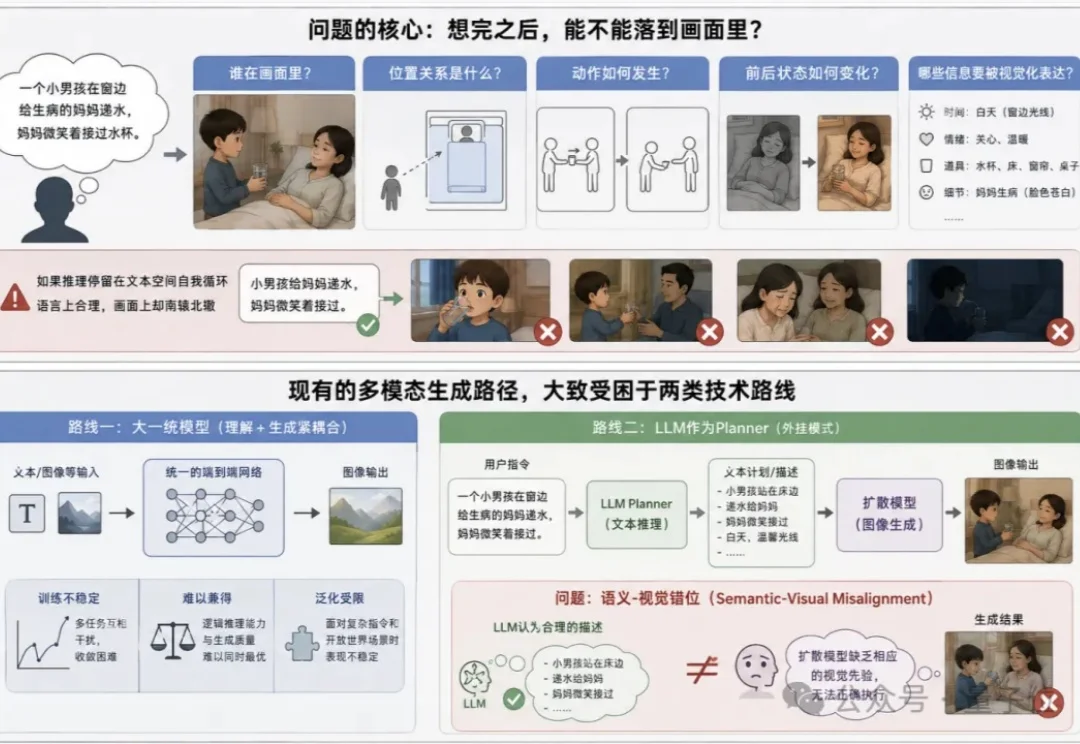
当下视觉生成正陷入一个能力错位困境—— 扩散模型的像素画质已接近完美,但一遇到需要逻辑推理的生成任务就频频翻车。
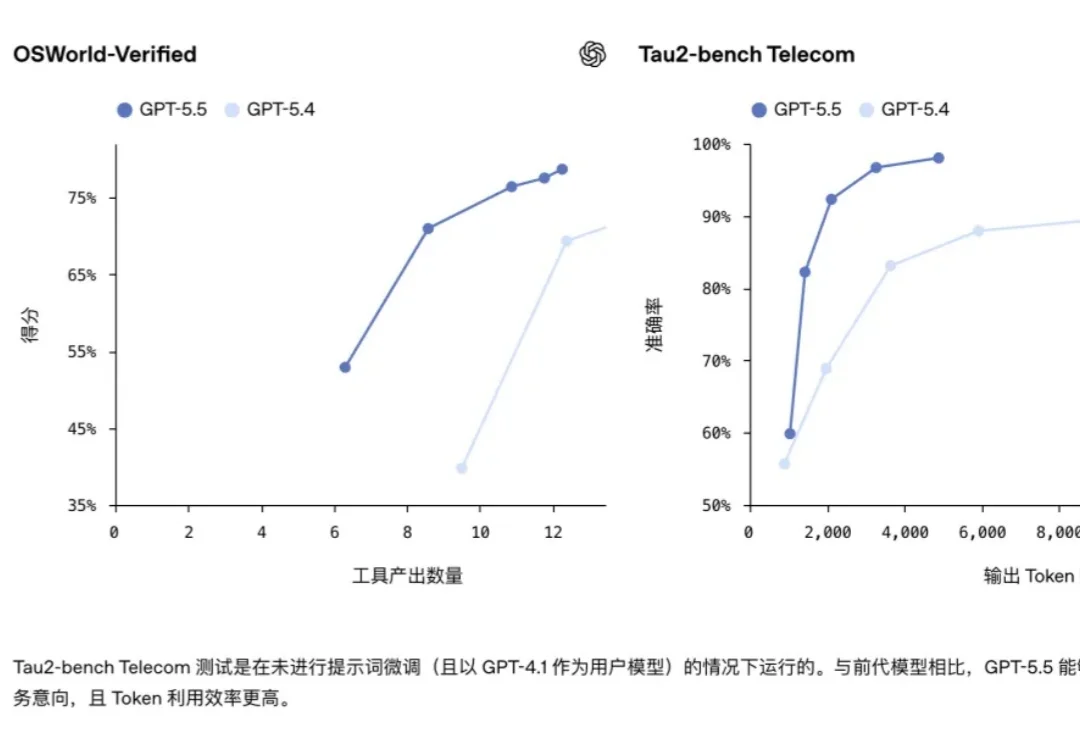
判断 Agent 靠谱与否,核心指标只有一个:是不是真干完活了
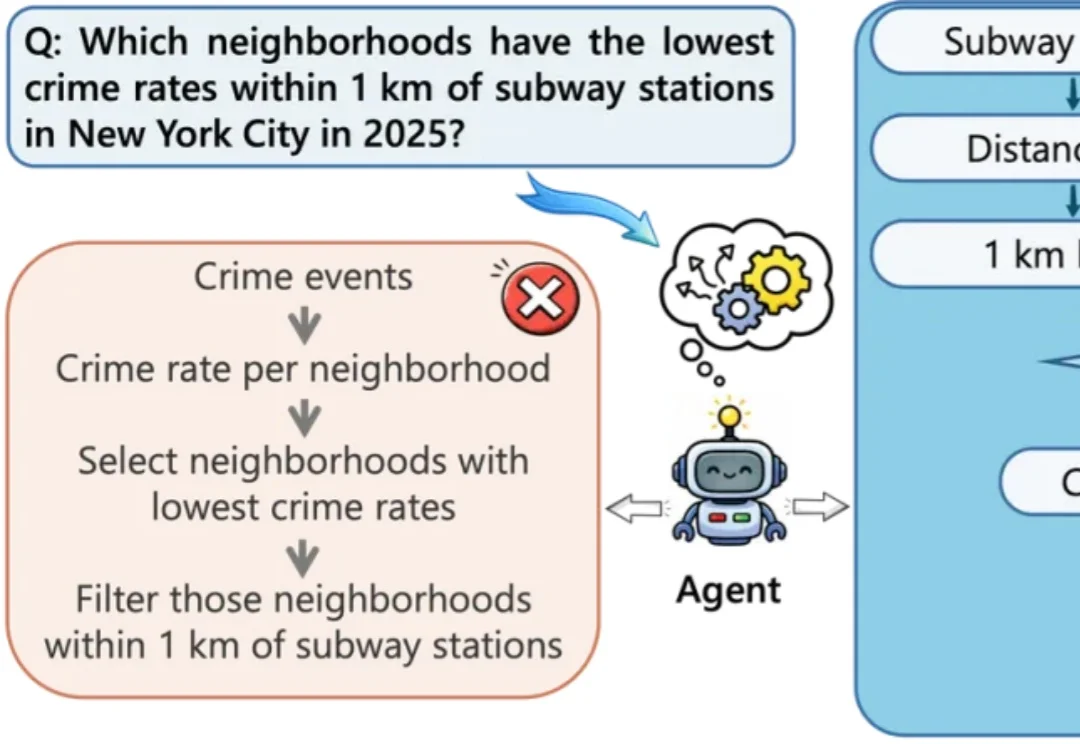
大语言模型在地图、城市、交通等空间领域的应用越来越广泛。对于这些场景来说,问题往往不只是 “查一个地点” 或 “调用一次路线 API” 就能解决的,而是需要把用户的自然语言问题组织成一段可执行、可验证的地理分析流程。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。

前几天大模型圈子有个很魔幻的场面,傅盛、孙宇晨、特朗普家族,三个八竿子打不着的人,开始扎堆做大模型中转站的生意。
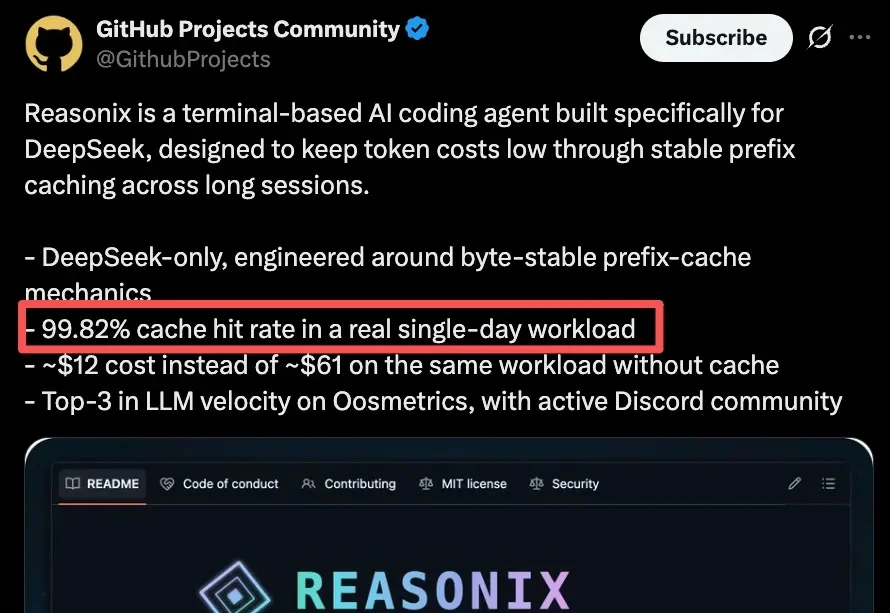
我悟了,DeepSeek V4系列发布1个月,价格屠夫的本色这才刚刚发力啊!

刚刚,Claude「双记忆系统」首次爆出!全新「文件记忆」让AI一边聊天,一边自动做笔记。还有杀手级Conway Agent浮出水面,7x24小时永不下线。
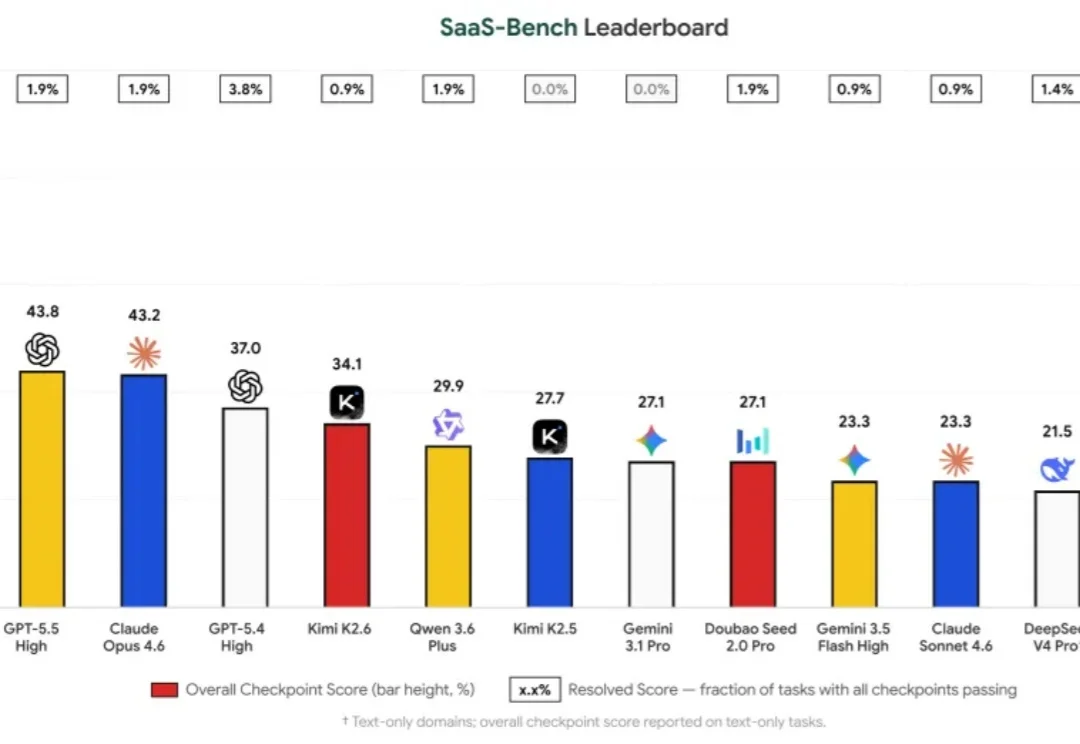
想象一个真实的工作日:项目经理要更新项目状态,财务人员要整理客户账单,医疗管理员要核对预约和保险信息。

具身智能(Embodied AI)正在快速从实验室走向真实世界。
大家好,我是袋鼠帝。 不知道大家有没有发现,随着AI的发展,token这个东西居然还变得越来越贵了。

刚刚的,面壁智能联合 OpenBMB 搞了个端侧开源周。今天作为开源周的第一天,端出来的是个好东西 BitCPM-CANN,模型权重只需要约 200 MB 的内存,手表也够跑

Claude Code 的 settings.json 里有 125 个配置键。官方文档只讲了大约 40 个。

219个词喂给AI,12小时后,一份7nm芯片版图出来了,工程师全程没碰键盘。这条芯片行业几十年没有AI走完过的路,第一次走通了。
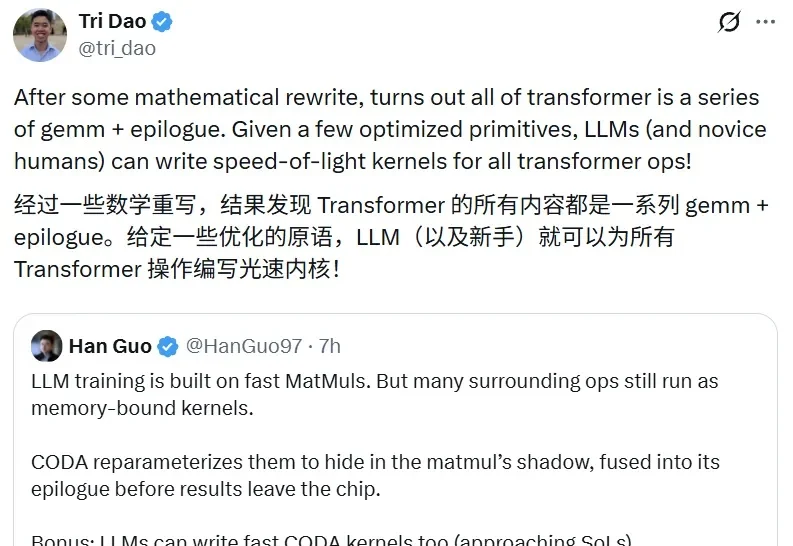
5 月 22 日,Tri Dao 在社交媒体上转发了 Han Guo 的一条推文。他还写道:「经过一些数学重写,结果发现 Transformer 的所有内容都是一系列 GEMM + epilogue(矩阵乘法加尾声)。给定一些优化的原语,LLM(以及新手)就可以为所有 Transformer 操作编写光速内核!」

近日,Meta 曝光的一段内部录音显示: 公司为了训练大模型,正通过监控工具监视员工在电脑上的鼠标和键盘操作。
当前,测试时扩展范式普遍致力于增加推理长度。然而,已有研究表明,随着推理长度的持续增长,以垂直扩展为核心的计算范式容易陷入探索僵化等问题。因此,从另一维度拓展推理的宽度显得尤为重要。K2.5、Step3-VL 和 LongCat-Flash-Thinking 等模型已在推理宽度方面开展了有益的探索。

机器人操作正在从结构化工业场景走向更开放的真实环境。相比完成单个预设动作,真实任务往往包含更长的执行链条、更复杂的物体交互,以及更多不可控的外部扰动。一次抓取没有完全夹稳、目标物体被轻微碰偏、双臂交接时姿态出现偏差,都可能让后续步骤偏离原本计划。

上个月,斯坦福大学、伦敦帝国理工学院和互联网档案馆(Internet Archive)联合发表了一篇论文。他们干了一件以前没人干过的事——结论是:到 2025 年年中,全球 35.3% 的新发布网页是 AI 生成或 AI 辅助的。