
Agent该不该单独配一个记忆模型?怎么搭建?Meta最新研究给出了答案
Agent该不该单独配一个记忆模型?怎么搭建?Meta最新研究给出了答案一个Agent可以完整读过任务要求,亲手执行过失败命令,也能在十分钟前准确定位错误根因,但到了下一轮决策,它仍可能像第一次遇到问题一样重走旧路:再次写入已经确认不可写的目录,重新尝试已经被证伪的参数,或者修好局部测试后忘掉最初的验收条件。
来自主题: AI技术研报
7136 点击 2026-07-29 09:50
 搜索
搜索
一个Agent可以完整读过任务要求,亲手执行过失败命令,也能在十分钟前准确定位错误根因,但到了下一轮决策,它仍可能像第一次遇到问题一样重走旧路:再次写入已经确认不可写的目录,重新尝试已经被证伪的参数,或者修好局部测试后忘掉最初的验收条件。

给图像生成模型一张人物参考图,它大概率能抓住身份特征。

刚刚,BeingBeyond智在无界发布首个基于人类视频数据的隐式触觉世界动作模型—— Being-H0.8。
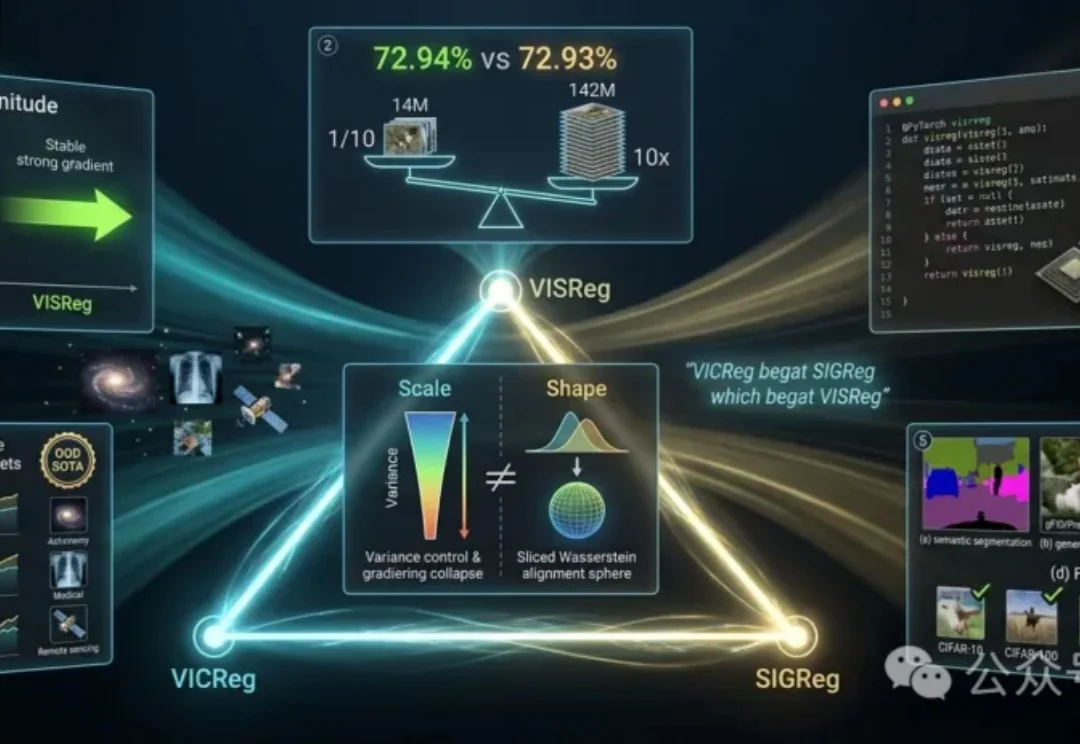
JEPA世界模型的底层是Yann LeCun自2017年起持续倡导的自监督学习(Self-Supervised Learning, SSL)。
还记得「苦涩的教训」(The Bitter Lesson)吗?

即使到了人手 N 个 Agent 产品的时代,大部分人还在用 Agent 产品的默认搜索与策略。

训练一个顶级文生图模型,到底需要多少钱?
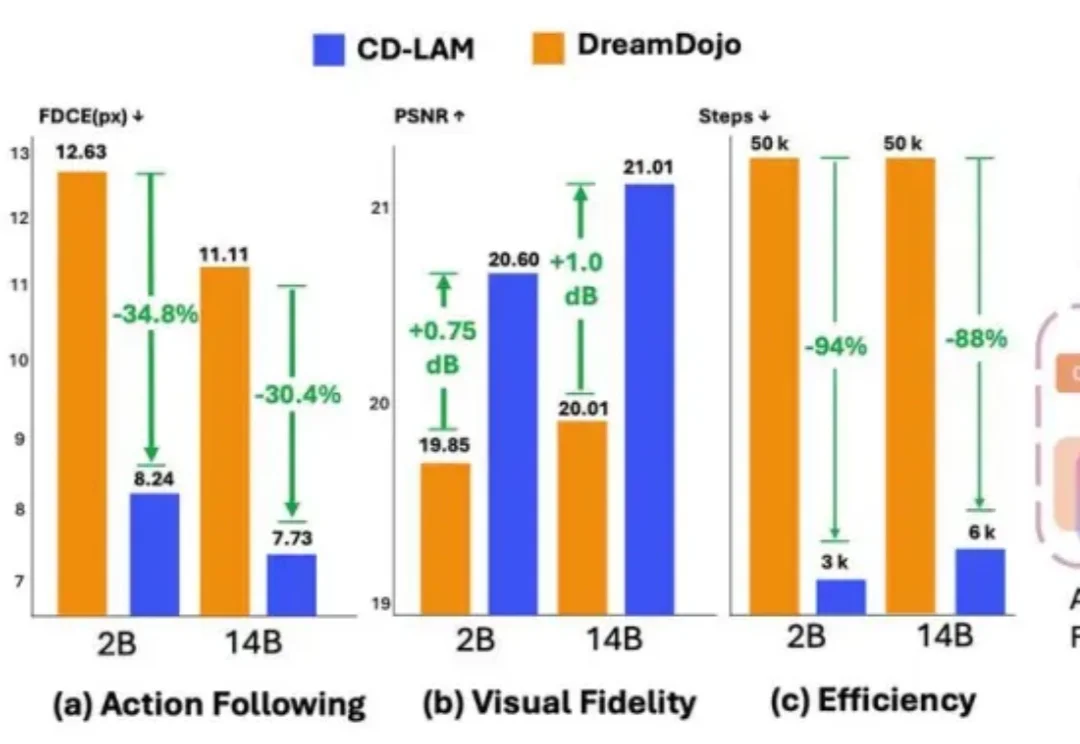
人类可以轻松想象一个还没做出的动作会带来什么:手一松,杯子会掉;往前一推,抽屉会合上。动作尚未发生,大脑已经预演了可能的结果。对机器人来说,具身世界模型(Embodied World Model)会根据当前观察和未来的动作,预测动作执行后的未来画面。
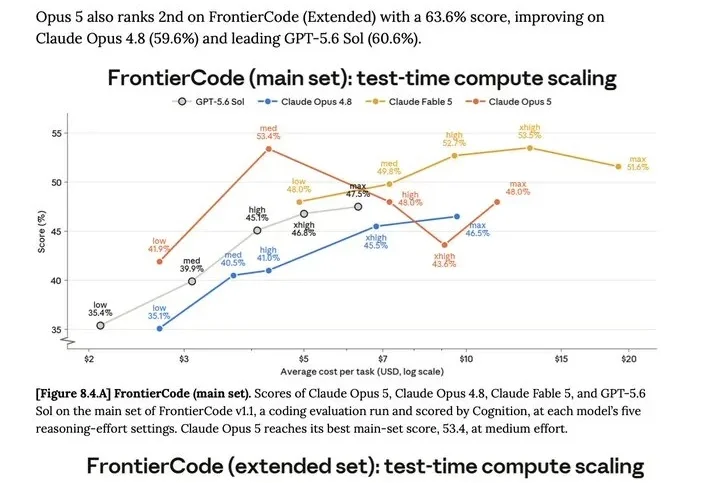
别无脑把Opus 5推理强度拉到max当冤大头。
让 Agent 上网查资料,已经不算新鲜事。

2026 WAIC 刚刚落幕,具身智能无疑是最受关注的技术方向之一。
上周我们发了一篇Agent大横评的文章三家评测,结果评论区出现了一个高频问题: “字节的TRAE Work建议测一下。”

GPT-5.5能写专业论文,DeepSeek-V4-Pro能生成复杂代码,具身机器人能完成基础物理操作,语言智能和工具智能都已经跑出了自己的赛道。
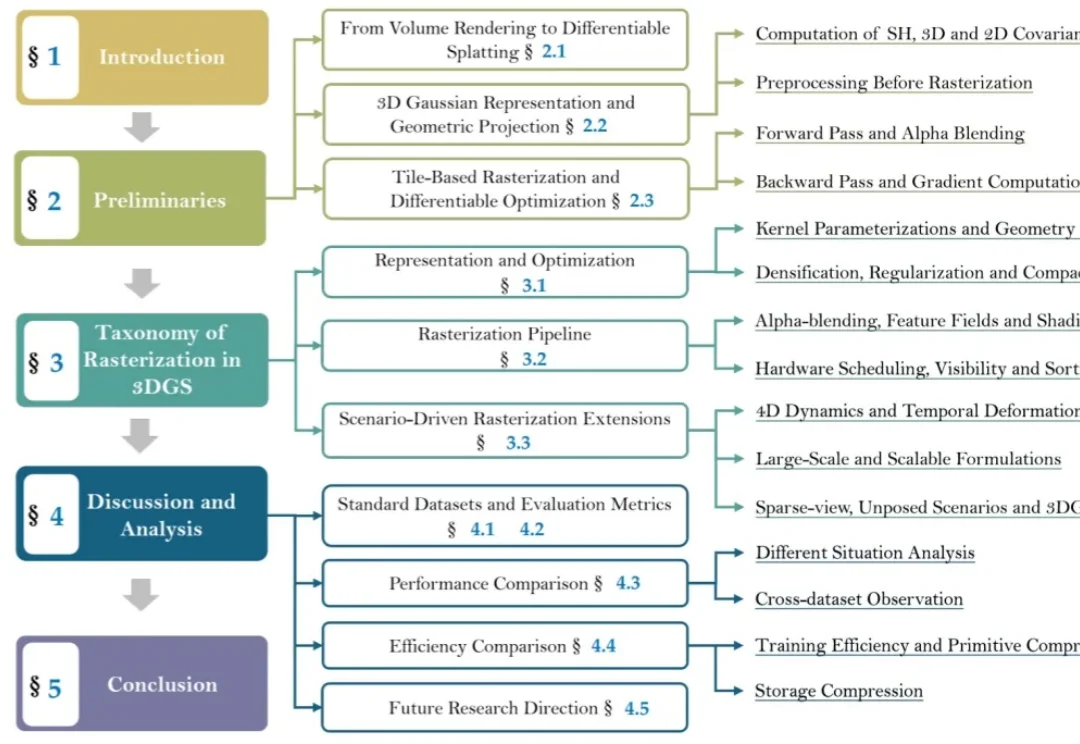
过去三年,3D Gaussian Splatting(3DGS)几乎成为实时3D场景重建与新视角合成的“默认答案”。

7 月 24 日,Claude Opus 5 上线。几个小时之内,我看到各家媒体把这个模型的评测成绩转载了一轮,而更值得留意的是 Anthropic 内部人员当天发出的一条推文。

今天给大家开源一个我自己周末做完然后用的很爽的Skill。 我把它称为, Leader.skill。
装完 codex,很多人在输入框里敲的第一句话是这样的:帮我做个 XX 网站。

大家好,我是连续充值Codex Pro会员4个月的袋鼠帝。 不得不说,Codex是真香,一开始我还是100刀的Pro 自从GPT-5.6出来之后,已经改成200$的会员了。

一个前沿模型,被要求随机生成一个奇数。

凌晨,我在一片黑屏上按下鼠标。
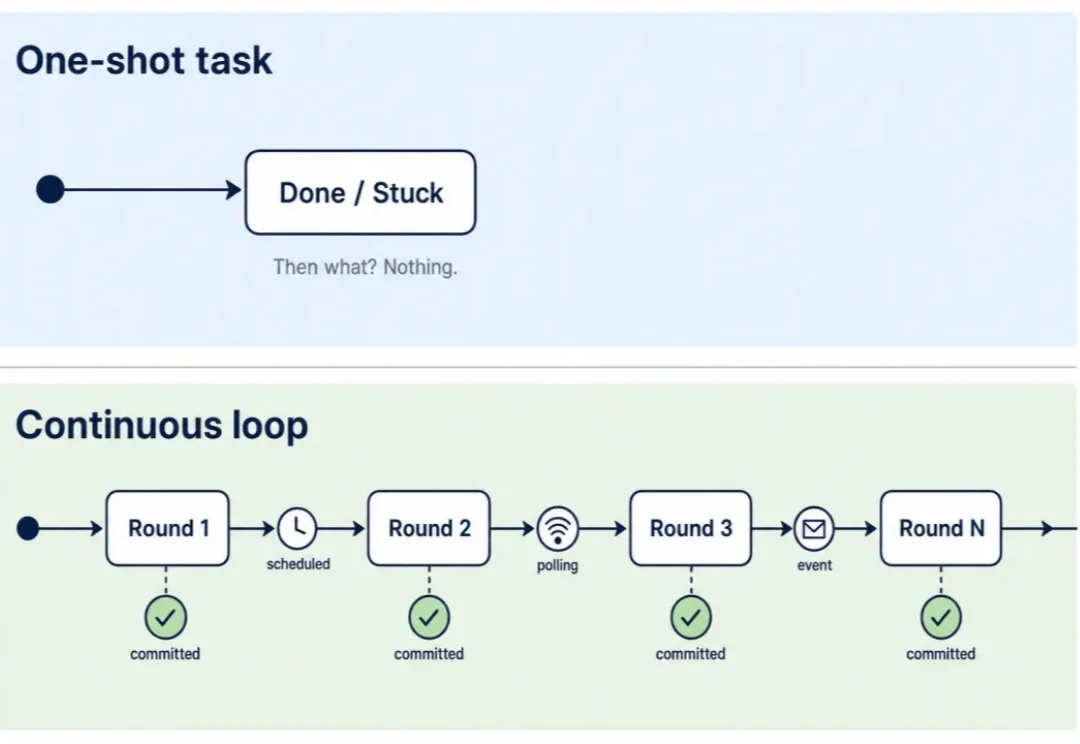
上周,龙虾之父Peter Steinberger 发了一条推文:我们还在讨论 Loop,还是已经转向 Graph 了?

刚读了一篇 AI4AI 论文《AI4AI at Scale》,来自 XYZ Agentic Team。还是第一次听到这个 Lab。他们用 AI4AI 的方式做出了两个很强的搜索 agent,也公开了方法。借这篇 paper 讲讲 AI4AI 到底怎么工作,下面尽量少堆术语。

现在的 Agent 将所有的工程线索和垃圾噪音都一股脑扔进 Chat Context 里,缺乏一层独立、结构化的 Engineering State 来做隔离与控制。为了打破这个瓶颈,Valkor 联合浙江大学智能计算与软件研究中心、伦敦大学学院(UCL)软件工程团队正式推出并开源了 loom。
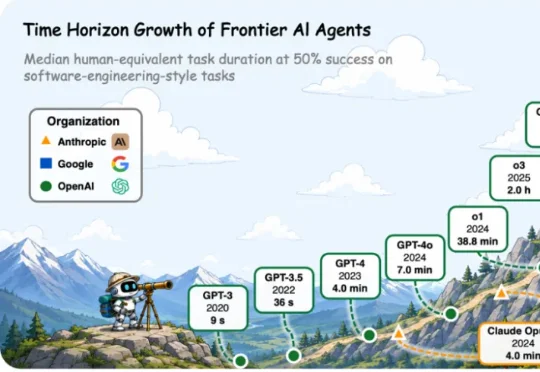
我们想强调的是:智能体 “跑得久”,并不等于 “具备长程能力”。真正的关键,不在于占用更多时间与算力,而在于能否在更长、更复杂、更真实的推理依赖链上持续、有效地行动。长期以来,Autonomous Agent、Self-Evolving Agent 等概念常与长程智能体混用。
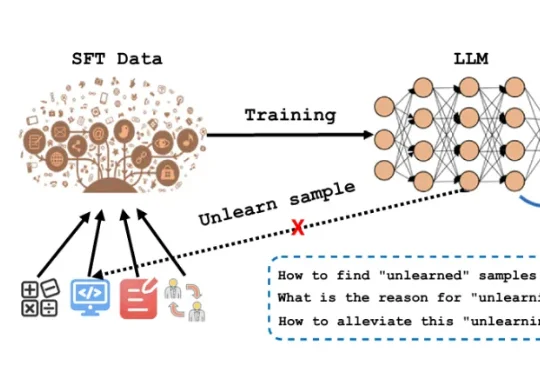
SFT是LLM从“通才”变成“专才”的关键步骤。业界默认做法是:准备标注数据(QA对、指令-回复对等)在基座模型上跑SFT训练。看loss曲线收敛了→认为训练完成。但问题在于:loss是全局平均,掩盖了样本间的差异。loss收敛只代表“大部分样本学会了”——那些始终学不会的样本被淹没了。

以往的空间音频模型,要么受限于实验室的苛刻采集条件,要么被高昂的人工标注成本卡住脖子。而团队的核心洞察是:相机的自运动本身就是一种免费的监督信号。当相机转动时,声源在声场中的相对位置随之改变——这种变化无需人工标注,模型即可从中学习空间对应关系。这项工作入选CVPR 2025 Highlight,投稿论文前2%。

多模型Agent系统显然是未来的趋势。cursor 的一篇很不错的文章。他们的最新研究表明,将前沿模型作为规划者和协调者,与一个更廉价的“主力”模型搭配,可以大幅降低项目中总token的成本,从而实现 15 倍的成本改进。
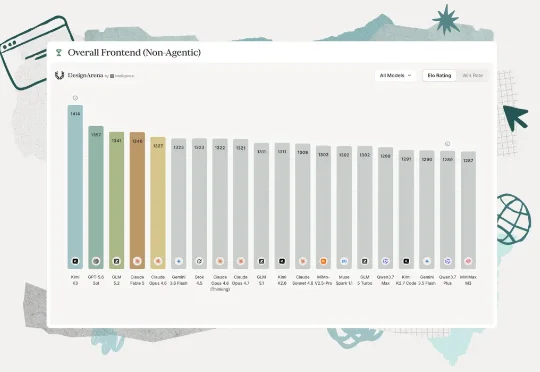
停停停!Kimi K3的最佳打开方式可能不在Coding——用它做前端设计,才是真·Interesting。在Design Arena最新公布的单次生成前端榜单中,Kimi K3以1414分位列第一,力压Fable 5和GPT-5.6 Sol。
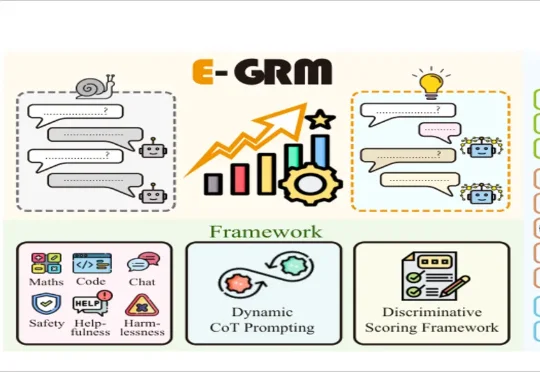
E-GRM的核心思路就是让模型自己判断输入复杂度——通过多次采样看答案是否收敛。收敛了就直接回答,不收敛再触发CoT。在RM-Bench、RMB、RewardBench三个基准上,约58%的样本被智能路由到“直答”,延迟降低62%,同时准确率还有提升。
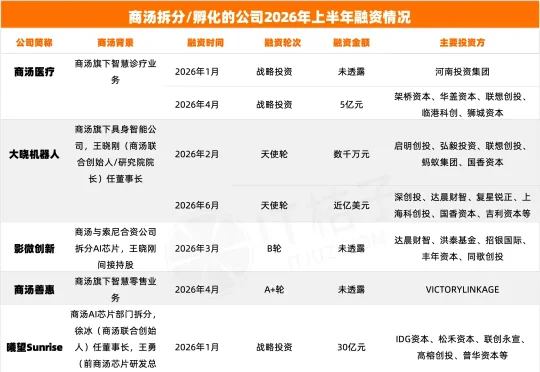
根据IT桔子数据,截至2026年7月17日, 32家“商汤系”公司在上半年共完成28笔融资,累计融资额超过470亿元人民币,在中国AI融资市场取得了耀眼的成绩。其中,既有商汤科技自身通过“1+X”战略拆分出的子公司——曦望Sunrise、大晓机器人、商汤医疗等;也有大批从商汤离职创业的前高管所创立的公司