
提示词工程论文登上ICML 2026,网友吵翻了天
提示词工程论文登上ICML 2026,网友吵翻了天这年头,提示词工程也能发ICML了???
来自主题: AI技术研报
7339 点击 2026-07-15 11:11
 搜索
搜索
这年头,提示词工程也能发ICML了???
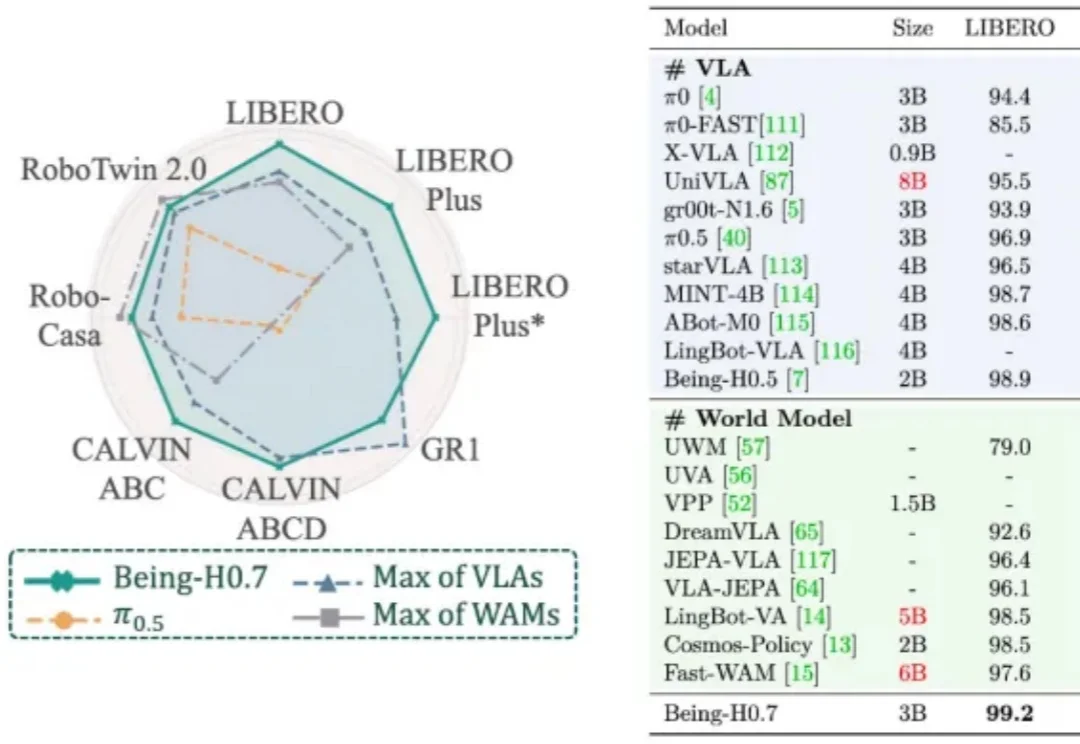
过去两年,人形机器人赛道的竞争焦点,正从整机硬件进一步延伸到模型能力。
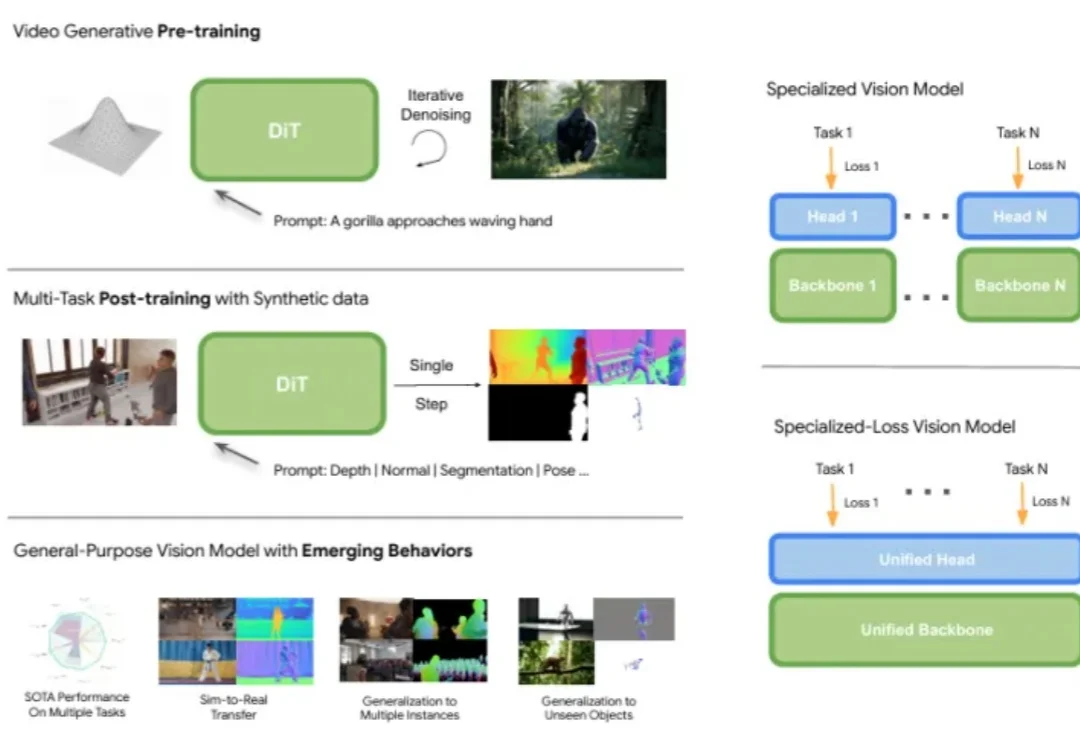
如果想开发一个视频理解应用,你会怎么做?

这两天网上冲浪的时候,发现有人用 Claude 复刻了一个类似《魔兽世界》的在线多人游戏。
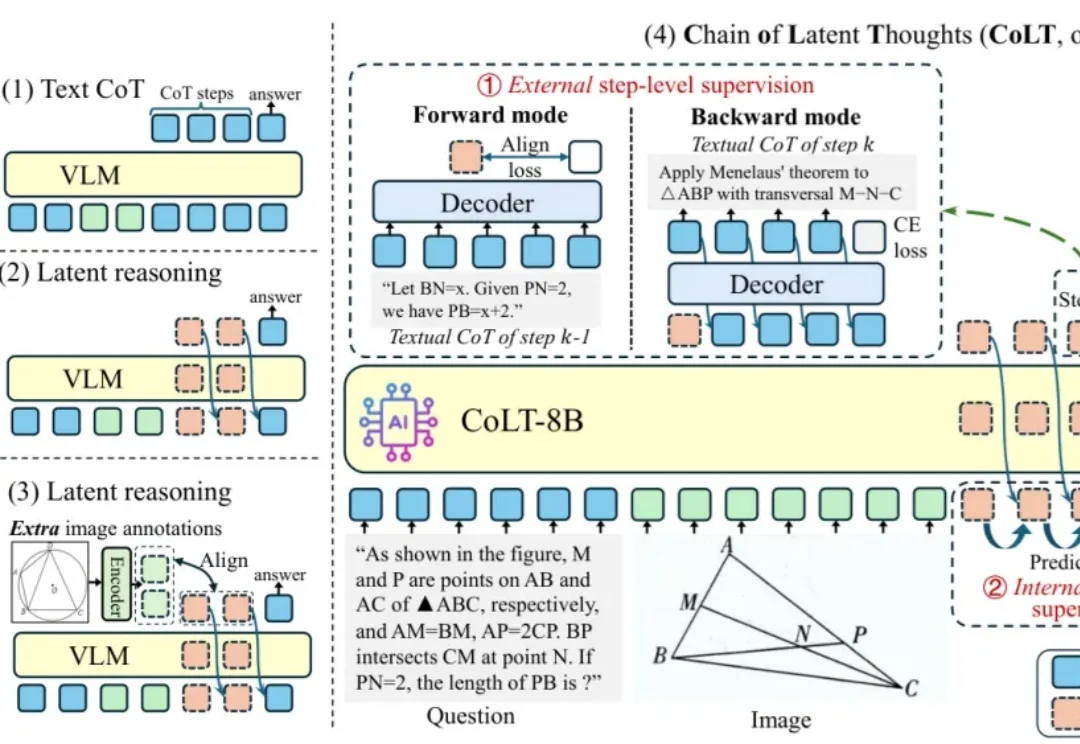
近年来,多模态大语言模型(MLLM)在视觉问答、图表理解、科学推理等任务上取得了令人瞩目的进展。

3D空间数据的瓶颈,从来不是算法,而是标注。

曾经我们对 AI 的期待还比较朴素,写邮件、翻译论文、聊天搭子……那时候,AI 像一个初出茅庐的实习生,你指哪它打哪,但也经常一本正经地胡说八道。
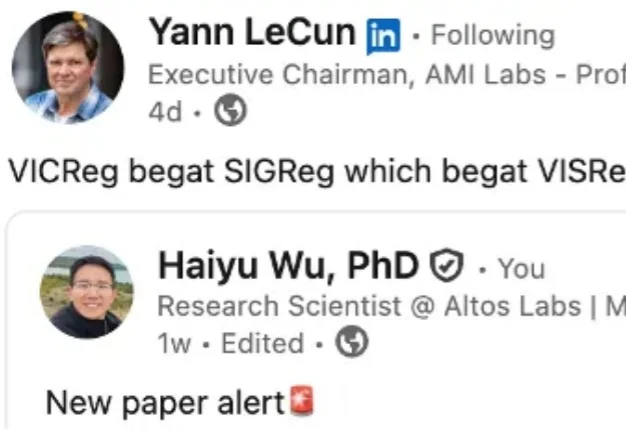
近日,自监督学习新工作 VISReg(Variance-Invariance-Sketching Regularization)获图灵奖得主 Yann LeCun 连续转发并给予高度认可 —— 他在转发时评价道「VICReg begat SIGReg which begat VISReg」(VICReg 孕育了 SIGReg,SIGReg 又孕育了 VISReg),

7月6日,腾讯混元Hy3正式版发布。

近日,新基石研究员、北京大学集成电路学院教授、深圳研究生院信息工程学院院长杨玉超团队,联合中国科学院上海微系统与信息技术研究所宋志棠研究员团队等,在国际顶级学术期刊《科学》发表最新成果,在新型神经动力学计算芯片领域取得重大突破。
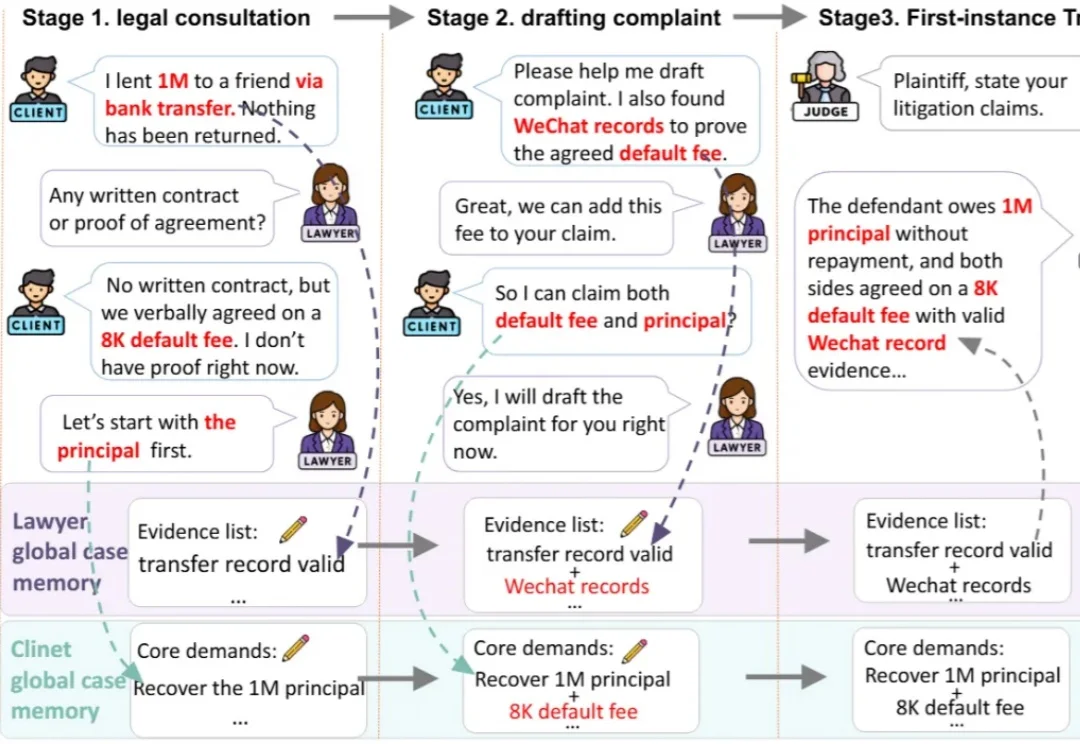
打官司,从来不是一问一答就能结束的事。
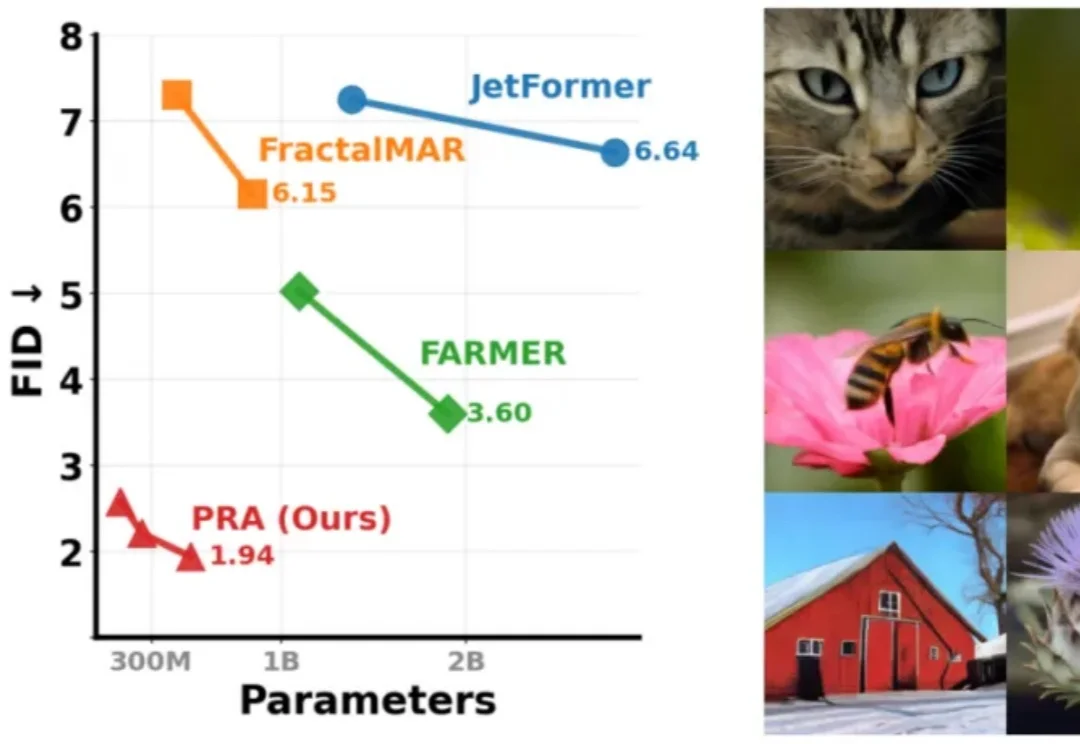
过去几年,扩散模型几乎定义了高质量图像生成:从随机噪声出发,经过多轮迭代,逐步 “雕刻” 出一张图像。但随着大语言模型席卷人工智能领域,另一条路线正迅速走到舞台中央 —— 图像,能否也像语言一样,通过自回归方式逐步生成?

大家好,我是极客杰尼。 今天,md2wechat 正式发布 3.0.0 大版本,这次最重要的变化,是普通创作者也能让 Agent 帮自己完成多图和 SVG 排版。
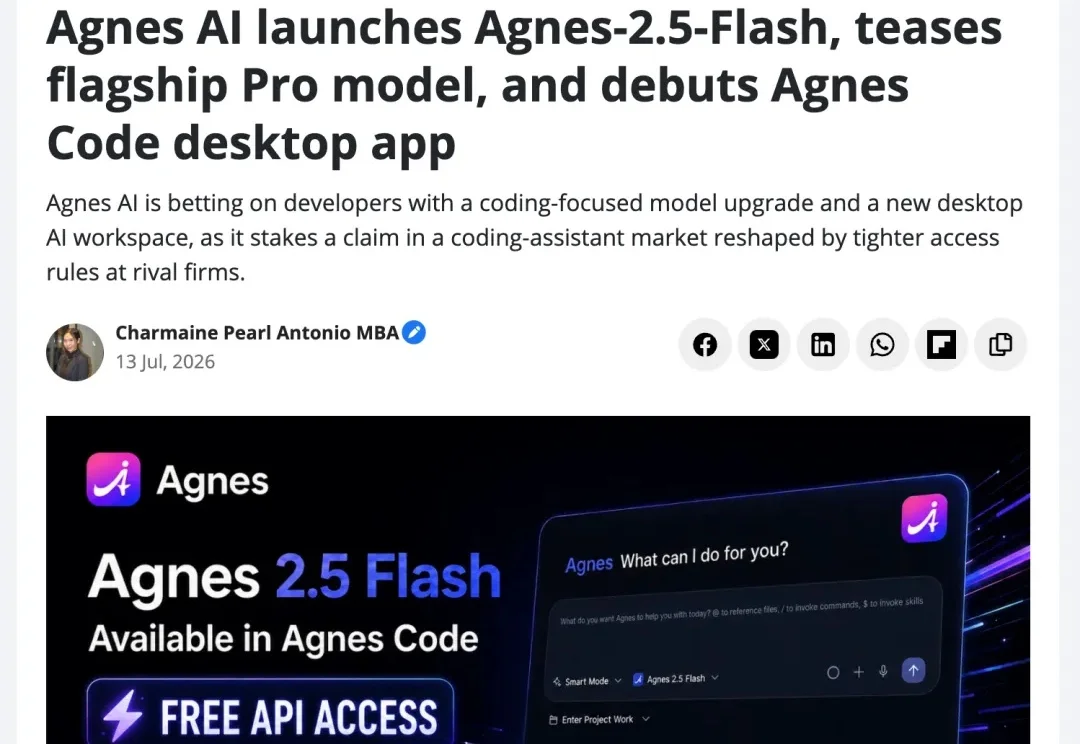
刚刚,Agnes 升级了!

OpenAI高管亲自下场,教开发者5分钟极速「策反」Claude Code,这波贴脸开大太狠了。
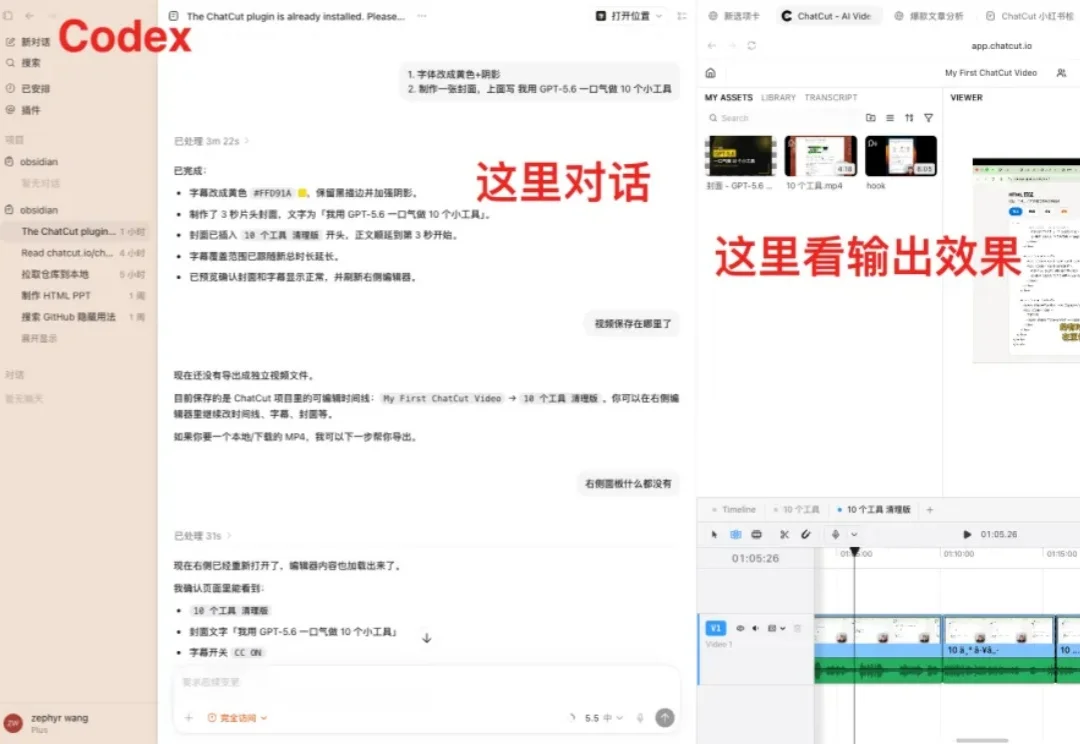
最近刷小红书,总能刷到 ChatCut。

不教AI认手,而是从视频世界模型里直接「读」出双手:三大基准SOTA,让百万小时野生视频第一次能变成机器人的操作教材。

一个AI工具挖出了藏在Linux里15年的致命漏洞,另一个AI却因为一个被录错的数字,让四辆警车把无辜记者当成盗车贼围了起来。
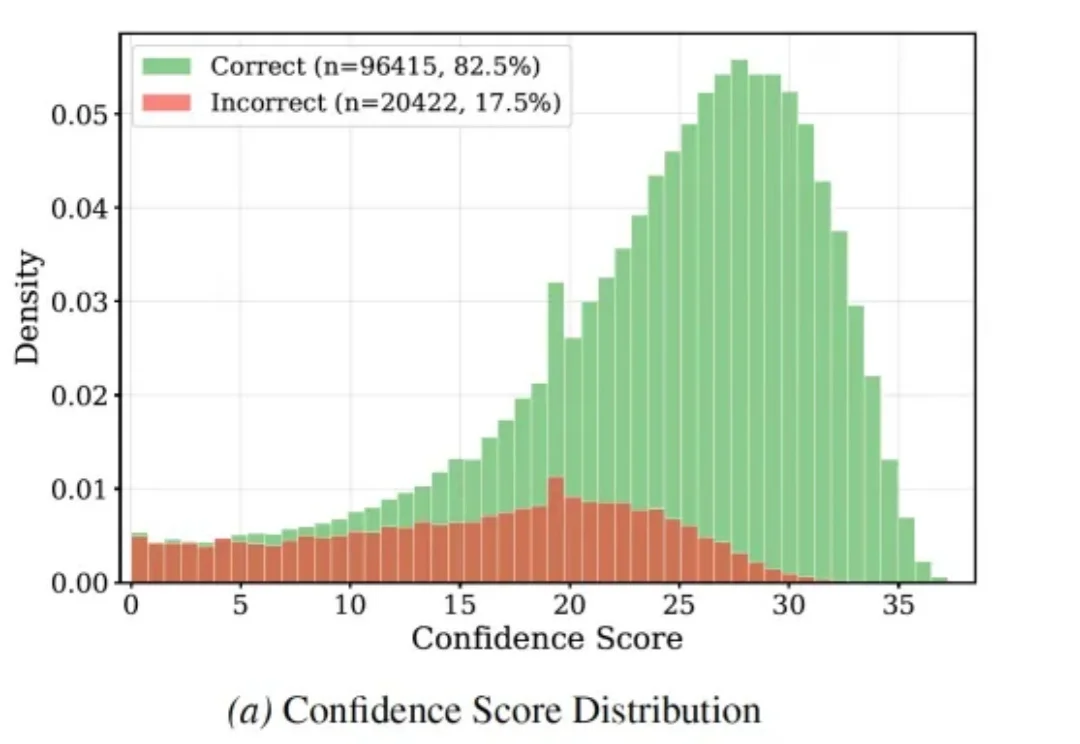
奖励模型(Reward Model, RM)是大语言模型对齐的核心组件,负责为模型输出提供符合人类偏好的评价信号。现有方法各有短板:标量判别式 RM 高效稳定但可解释性有限;生成式 judge 能给出判断理由,却需为每个样本生成长 reasoning,token 与延迟开销显著。

近期,围绕「世界模型」的讨论持续升温。机器人、自动驾驶、视频生成、具身智能等多个方向都在频繁使用这一概念,相关系统不断出现,演示形式日益丰富,评价指标也越来越多。伴随这一趋势,一个基础问题变得格外重要:当一个模型被称为「世界模型」时,人们究竟在评价什么?
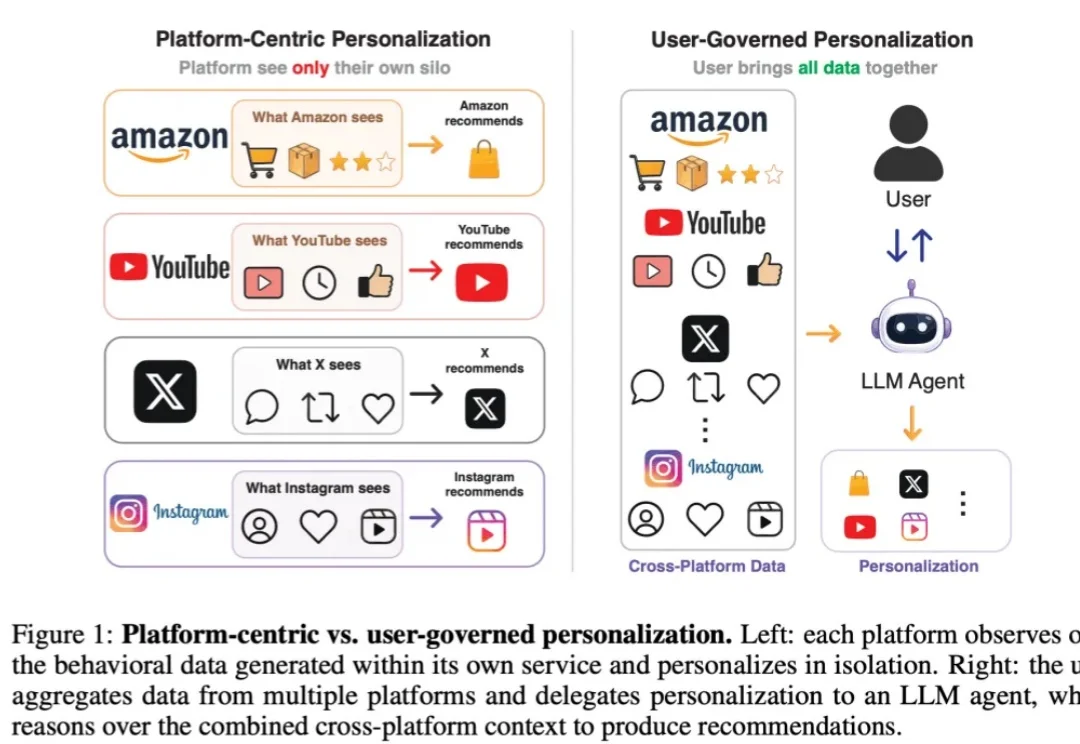
在过去二三十年的互联网发展中,个性化推荐几乎一直是平台的核心能力之一。打开视频 app,平台决定你接下来会刷到什么视频;打开购物软件,平台预测你可能会购买什么商品;打开短视频 app,平台根据你的浏览、点赞、停留和互动,不断优化信息流。某种意义上,现代互联网的用户体验本身就是由推荐系统塑造的。
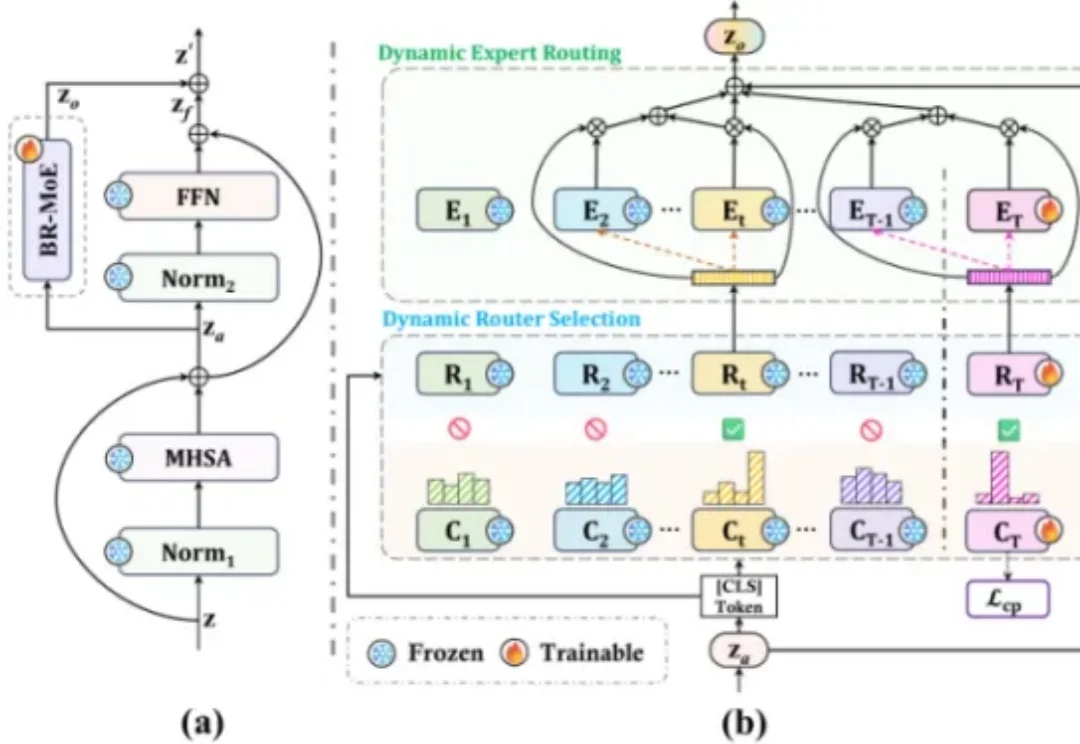
人类可以在一生中持续学习新知识,而不会轻易遗忘已有技能。然而对 AI 模型而言,这恰恰是一道极具挑战性的难题:每当模型学习新任务时,参数更新往往会覆盖历史知识,产生经典的 “灾难性遗忘” 难题。持续学习(Continual Learning)正是为突破这一瓶颈而生的研究方向。
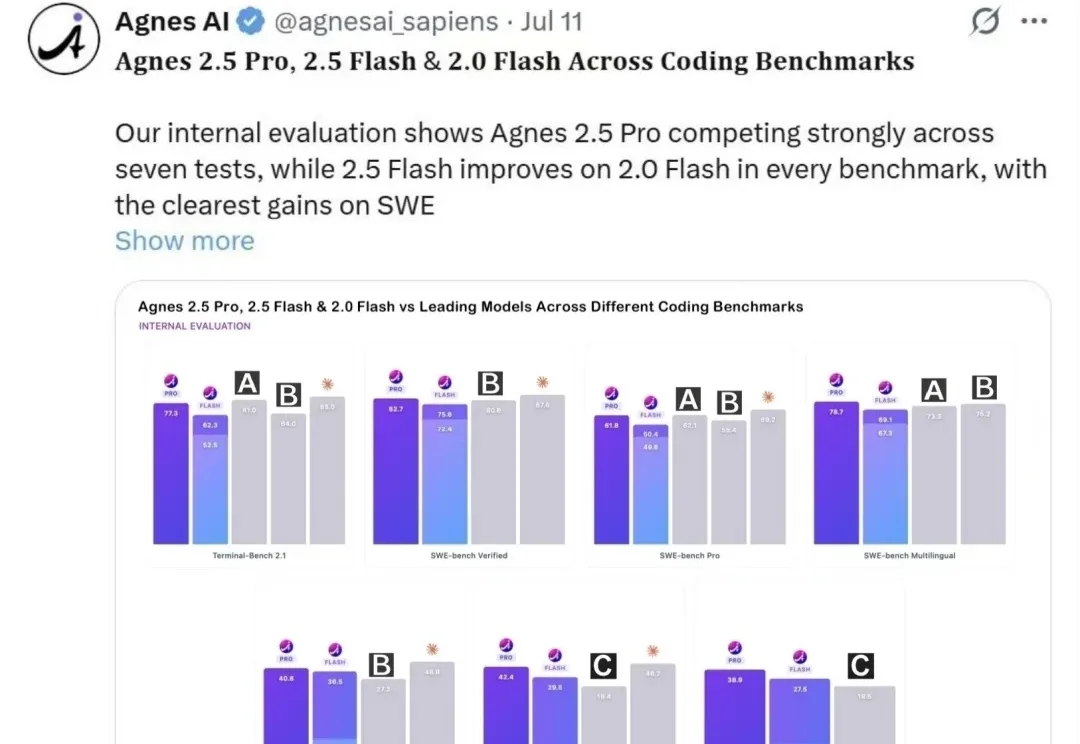
2026年下半场,AI Coding赛道最大的焦虑变了。
把腾讯WorkBuddy用透,你26年下半年会轻松很多。
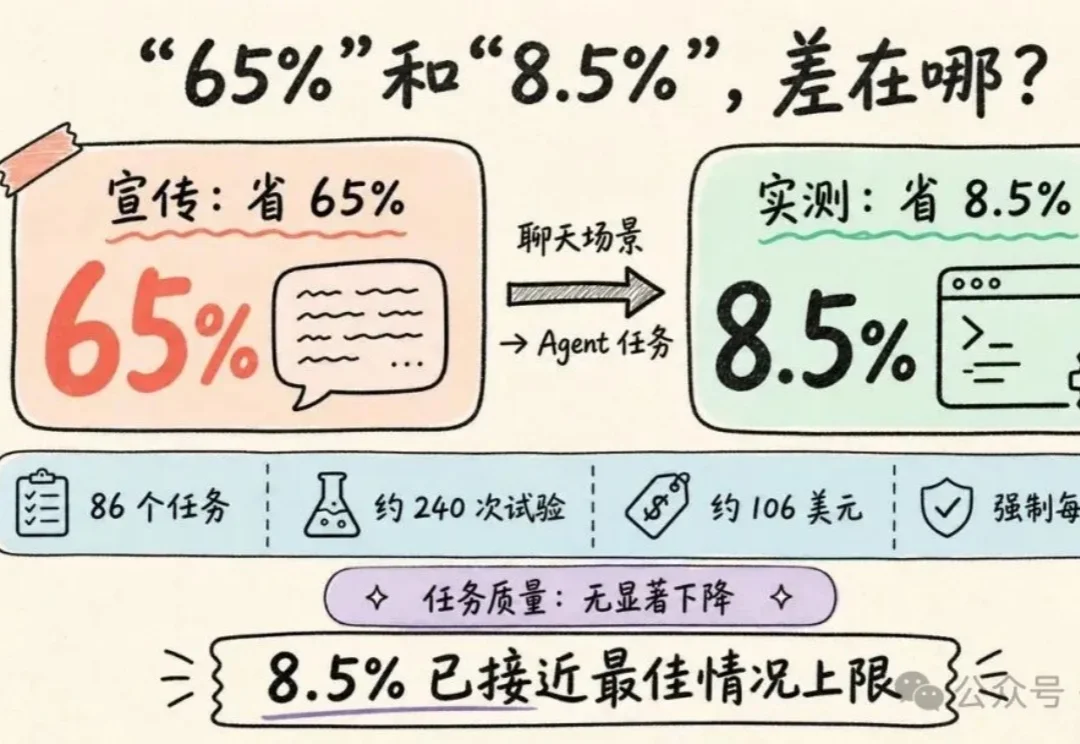
我把那种号称能省 Token、要求 AI 尽量少说话的 Skill,叫做“电报体 Skill”。

近期,美国俄勒冈州立大学研发出一种新型成像传感器,不仅可在探测光线的同时进行图像存储(近期光照信息),还能实现信息的按需“遗忘”。
这篇文章,我会从我对Skill的理解、设计Skill的方法、怎么升级和迭代Skill这些维度展开。并且会结合之前的Codex自动化剪辑工作流,尽可能用简单和直白的语言,把Skill讲清楚,确保朋友们看完就能用得上。

近日,Anthropic官方发了一篇长文专门来讲这件事。 起因是太多人把Claude Code里的两个选项搞混了:一个是模型选择(Model),一个是努力度(Effort)。过去,大家对这两个选项的理解都很简单:换更大的模型,AI就更聪明;把Effort调高,无非是让AI多想一会儿。

为了打破多镜头长视频面临的高延迟、零交互困境,香港中文大学与快手可灵团队联合提出了首个实时流式多镜头长视频生成框架 ——ShotStream。该研究打破了传统双向架构的限制,将多镜头合成定义为基于历史上下文的下一镜头生成任务,用户可以通过动态流式提示词在运行时动态指导叙事走向!更令人振奋的是
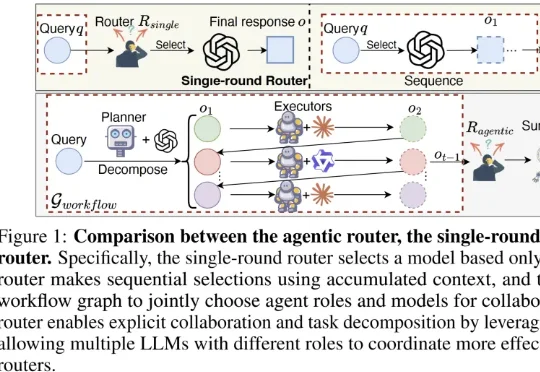
GraphPlanner通过引入图记忆网络,将多智能体LLM的路由过程升级为动态工作流生成。不仅选择调用哪个模型,还决定每个模型应承担的角色,实现任务分解与协作规划。