
我的Clawdbot和你的一样,只不过你多花了4000元
我的Clawdbot和你的一样,只不过你多花了4000元哈喽,大家好,我是刘小排。 最近我见到人就推荐Clawdbot。
来自主题: AI技术研报
8083 点击 2026-01-29 16:53
 搜索
搜索
哈喽,大家好,我是刘小排。 最近我见到人就推荐Clawdbot。

五个真实物理任务实测,PhysMaster 可推导、写码、数值验证。

最近Clawdbot(现:Moltbot)全网爆火。它能接管你的社交媒体,能发帖、能监听、能回复、能长期驻场。不是一次性回答,而是持续存在。
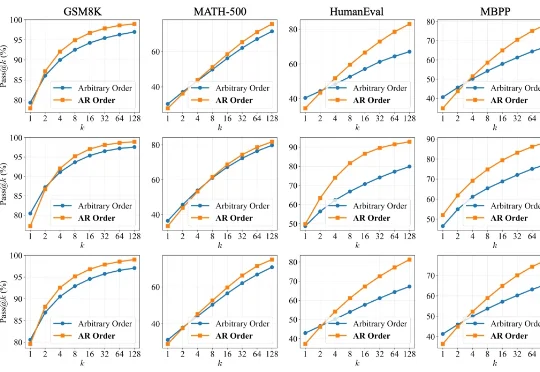
扩散语言模型(Diffusion LLMs, dLLMs)因支持「任意顺序生成」和并行解码而备受瞩目。直觉上,打破传统自回归(AR)「从左到右」的束缚,理应赋予模型更广阔的解空间,从而在数学、代码等复杂任务上解锁更强的推理潜力。

美国机器人界掌管demo的神,Figure,冷不丁又出一拳!

一个开源AI,能记住你几个月前的决定、在本地替你跑活、还不受大厂控制:Clawdbot到底是个人助理,还是下一代「赛博打工人」?

为什么在LLM推理能力大幅跃升的2026,我们依然只有AI Copilot而没有AI Teammate?尽管AI编程工具遍地开花,但不管是Claude Code还是Codex,本质上仍是“单Agent开发”或“主从控制”架构。而“AI结对编程”迟迟无法落地?
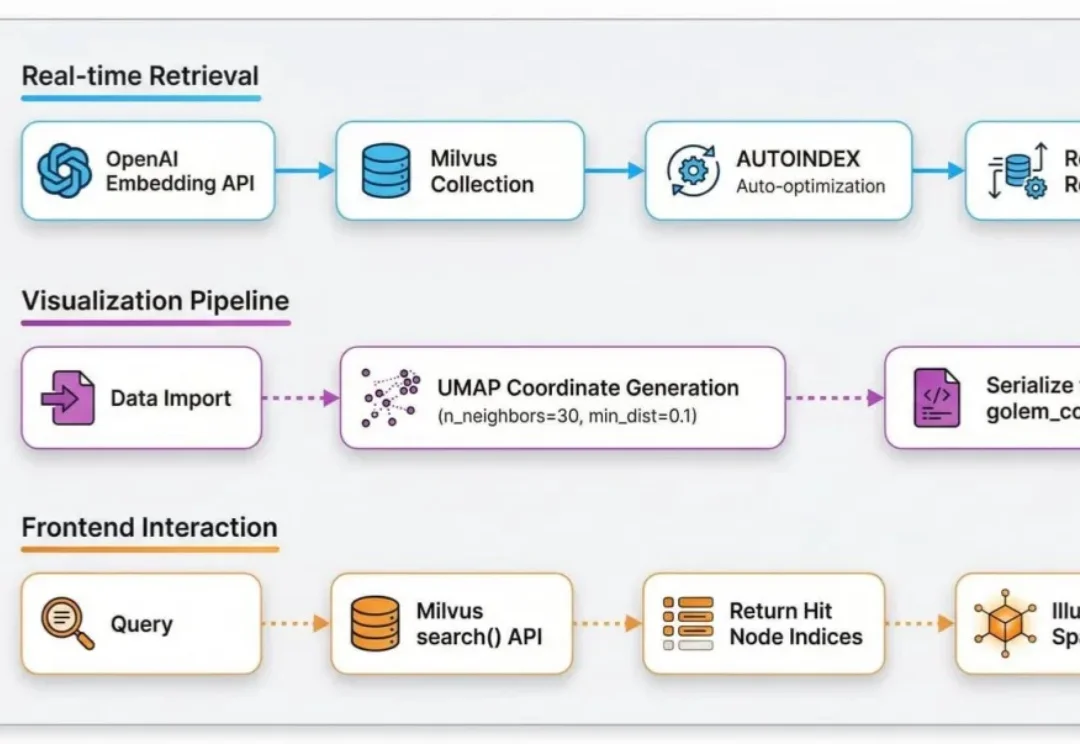
最近,在GitHub上发现一个宝藏项目Project_Golem 。
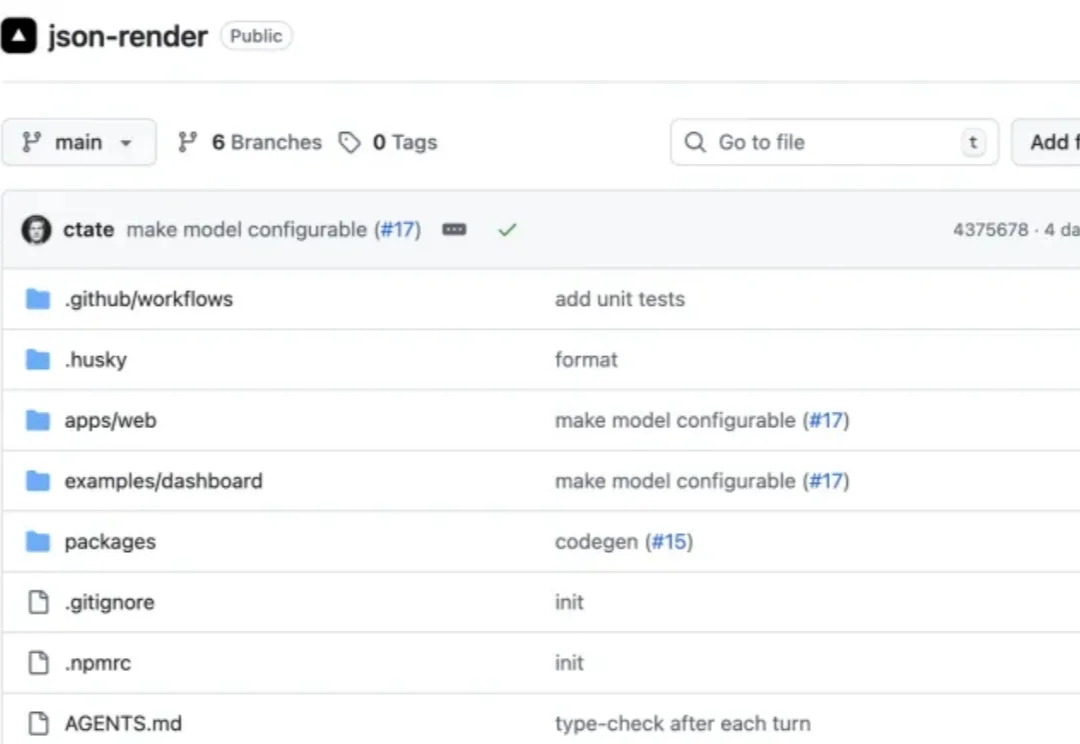
如果你关注前端或 AI 圈,这几天一定被 Vercel 最新开源的 json-render 刷屏了。
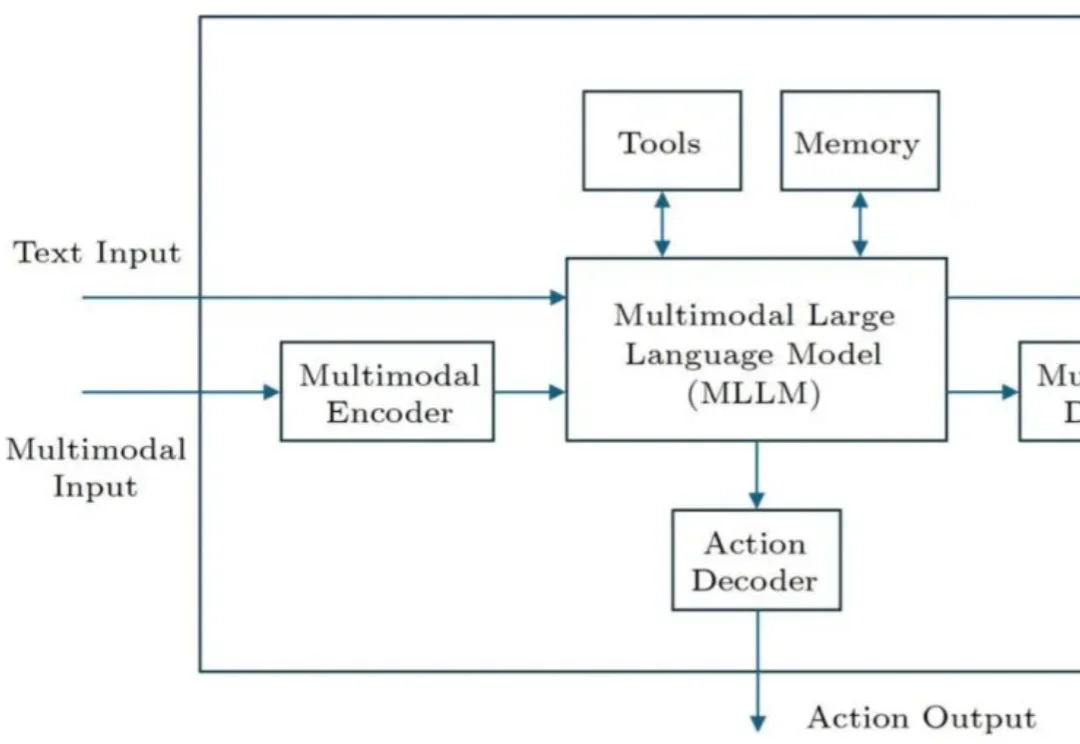
AI 智能体是人工智能领域的重要研究方向之一。近期,字节跳动的李航博士在我国计算机科学领域顶级期刊 Journal of Computer Science and Technology(JCST)上发表了一篇题为《General Framework of AI Agents》的观点论文(将收录于 JCST 创刊 40 周年专辑),提出了一个涵盖软件智能体和硬件智能体的通用框架。

这几天,相信大家肯定都被一个产品名给刷屏了。
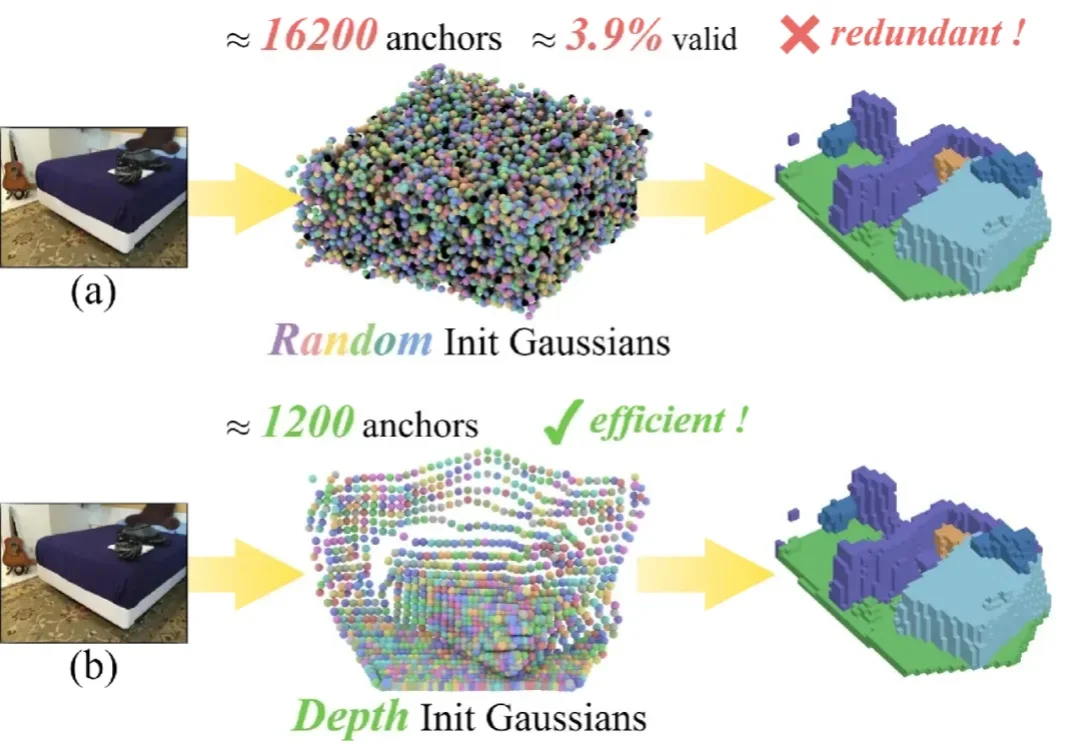
单目 3D 语义场景补全 (Semantic Scene Completion, SSC) 是具身智能与自动驾驶领域的一项核心技术,其目标是仅通过单幅图像预测出场景的密集几何结构与语义标签。

在技术如火如荼发展的当下,业界常常在思考一个问题:如何利用 AI 发现科学问题的新最优解?

在 AI 浪潮席卷全球的今天,大模型在写诗、作画、敲代码上已经展现出惊人的天赋。然而,在面对严谨、硬核的物质科学(物理、化学、材料)时,却常常表现得像个“偏科生”:它们能侃侃而谈化学理论,却在最基础的分子式、晶体结构书写和反应推理上频繁出现不稳定输出:说的像那么回事,写出来却漏洞百出。

从3000小时到整整20000小时。
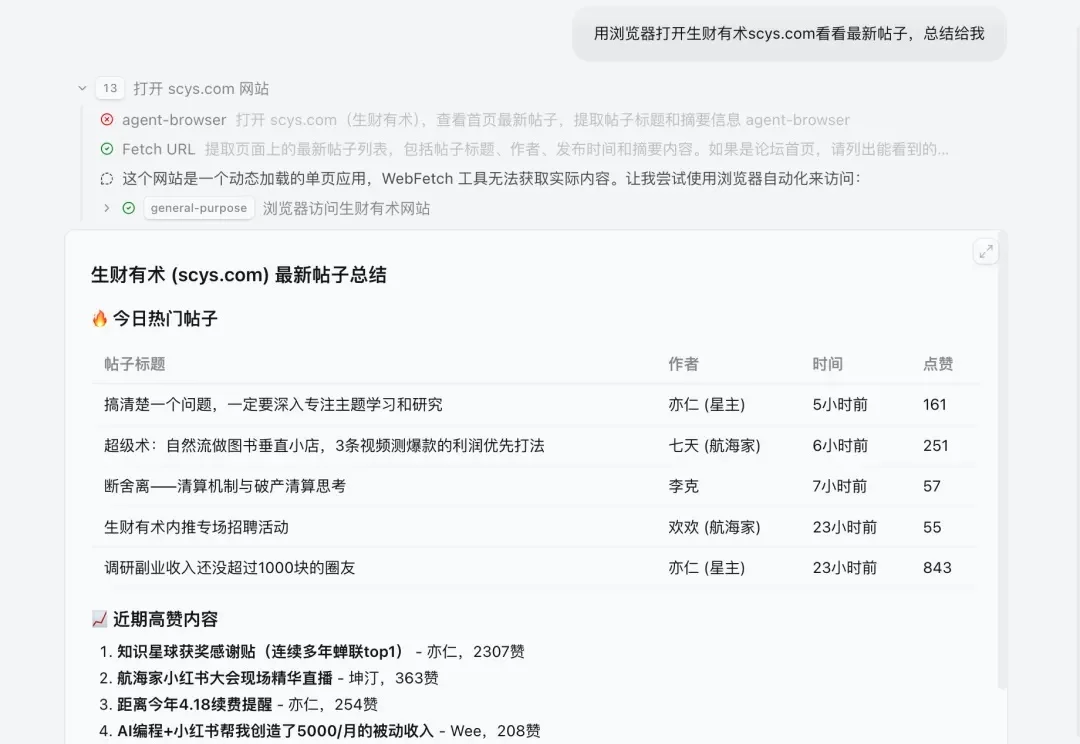
哈喽,大家好,我是刘小排。 昨天和几位创业的朋友吃饭,席间讨论了一个问题:“在Claude Code中,最好的浏览器自动化方案是什么?”

什么样的思维链,能「教会」学生更好地推理?

我们都在System Prompt里写过无数次 You are a helpful assistant,但你是否想过:这行文字在模型的残差流(Residual Stream)中究竟对应着怎样的几何结构?

过去几年,机制可解释性(Mechanistic Interpretability)让研究者得以在 Transformer 这一 “黑盒” 里追踪信息如何流动、表征如何形成:从单个神经元到注意力头,再到跨层电路。但在很多场景里,研究者真正关心的不只是 “模型为什么这么答”,还包括 “能不能更稳、更准、更省,更安全”。

过去一年,几乎所有 AI 产品都在谈一个词:记忆。

DeepSeek开源DeepSeek-OCR2,引入了全新的DeepEncoder V2视觉编码器。该架构打破了传统模型按固定顺序(从左上到右下)扫描图像的限制,转而模仿人类视觉的「因果流(Causal Flow)」逻辑。

天下苦机器人看不清透明和反光物体久矣。
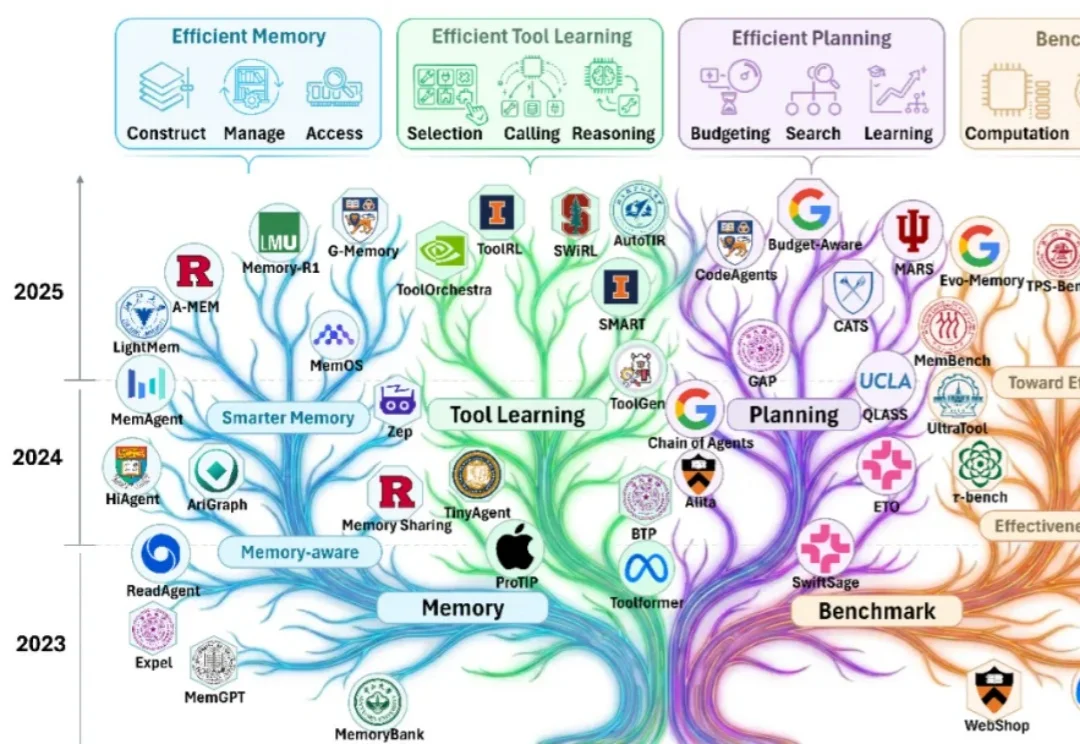
随着大模型能力的跃迁,业界关注点正在从 “模型能不能做” 快速转向 “智能体能不能落地”。过去一年可以看到大量工作在提升智能体的有效性(effectiveness):如何让它更聪明、更稳、更会用工具、更能完成复杂任务。
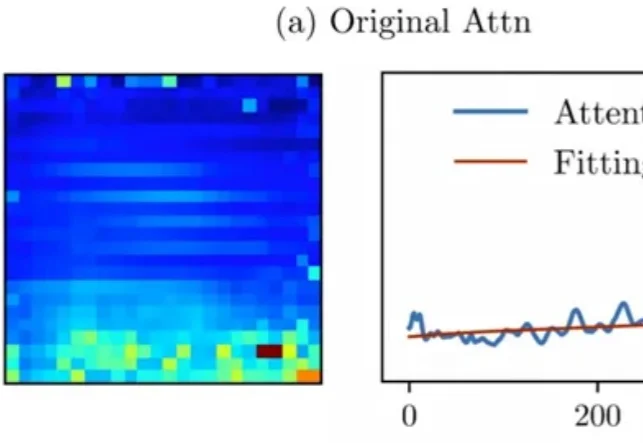
Attention真的可靠吗?
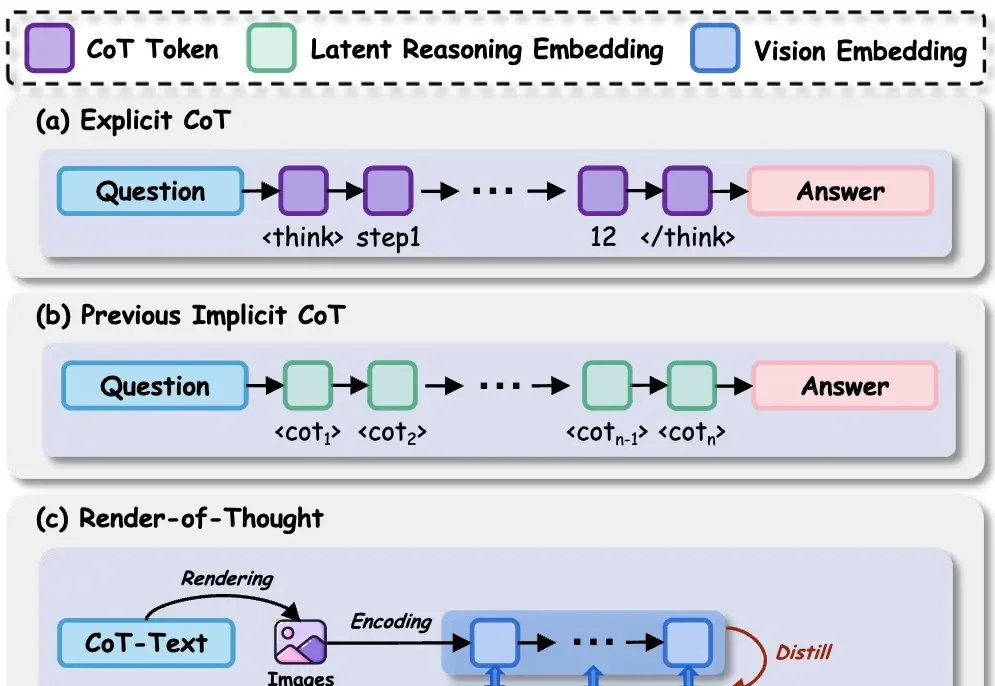
在 LLM 时代,思维链( CoT)已成为解锁模型复杂推理能力的关键钥匙。然而,CoT 的冗长问题一直困扰着研究者——中间推理步骤和解码操作带来了巨大的计算开销和显存占用,严重制约了模型的推理效率。
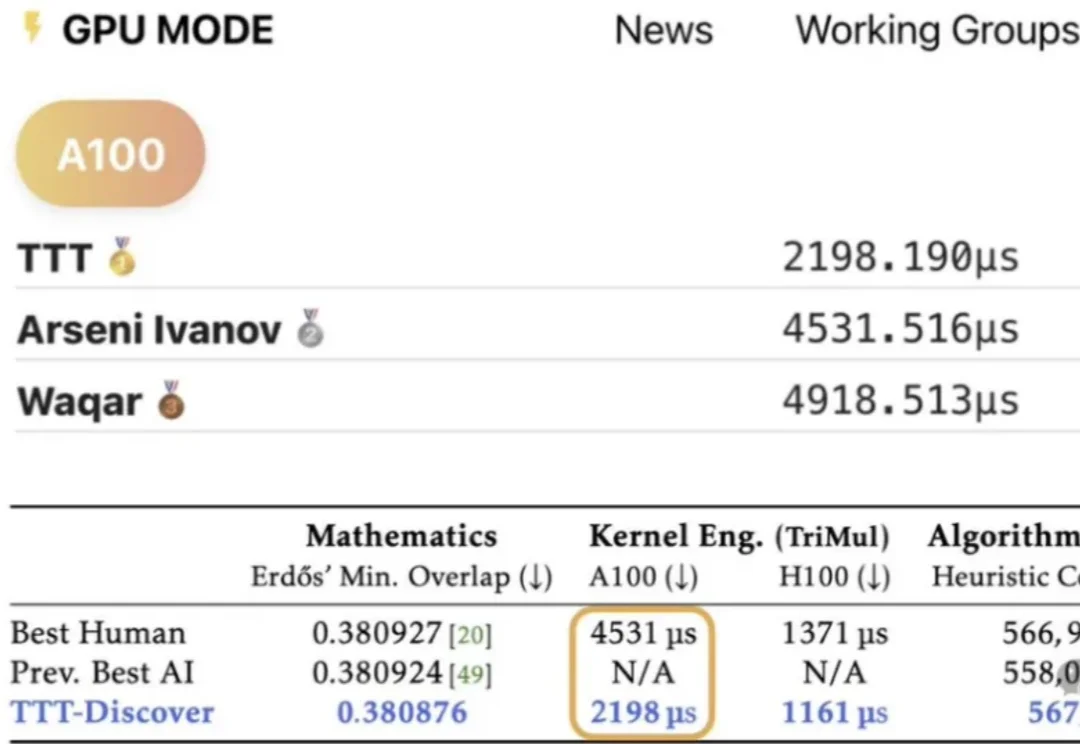
大模型持续学习,又有新进展!

这一框架可用于集成额外文本、语音和视觉等多种模态。
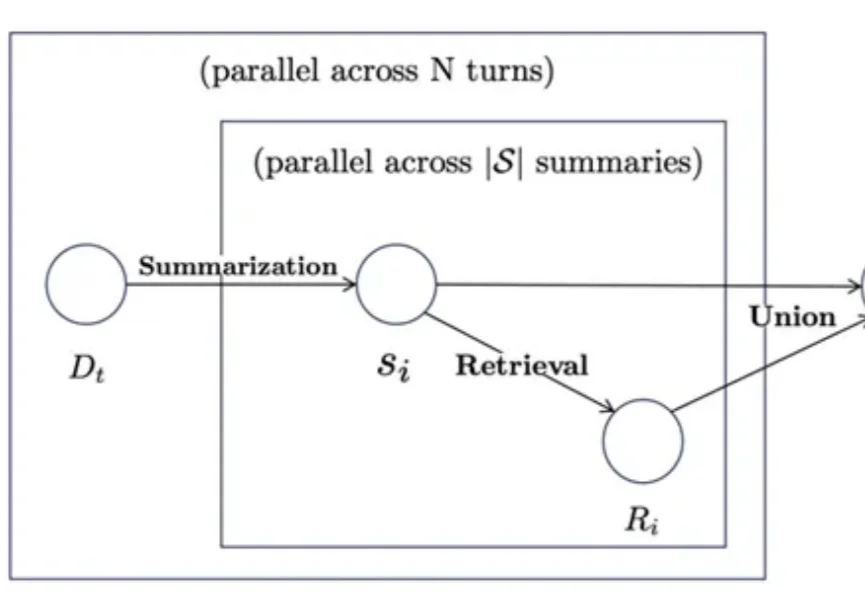
思维导图曾被证明可以帮助学习障碍者快速提升成绩,那么当前已经可堪一用的智能体系统如果引入类似工具是否可以帮助改善长期学习记忆能力呢?有研究团队做出了探索性尝试。

近日,北京大学朱毅鑫教授课题组、北京大学毕彦超教授课题组和山西医科大学第一医院王效春团队通过结合 AI 模型和大脑损伤患者的数据,发现语言其实是一副无形的智能眼镜,时刻在悄悄修饰着我们看到的世界。我们可能以为视觉就是眼睛看到什么就是什么,但是这项成果说明了视觉从来都不是孤立的。事实上,当我们在看图片的时候,其实不只是在看,而是在进行被语言调制过的看。

这两天,我的朋友圈被一个东西刷屏了,叫 Clawbot 🦞。