
系统学习Deep Research,这一篇综述就够了
系统学习Deep Research,这一篇综述就够了近年来,大模型的应用正从对话与创意写作,走向更加开放、复杂的研究型问题。尽管以检索增强生成(RAG)为代表的方法缓解了知识获取瓶颈,但其静态的 “一次检索 + 一次生成” 范式,难以支撑多步推理与长期
来自主题: AI技术研报
8512 点击 2026-01-02 15:01
 搜索
搜索
近年来,大模型的应用正从对话与创意写作,走向更加开放、复杂的研究型问题。尽管以检索增强生成(RAG)为代表的方法缓解了知识获取瓶颈,但其静态的 “一次检索 + 一次生成” 范式,难以支撑多步推理与长期
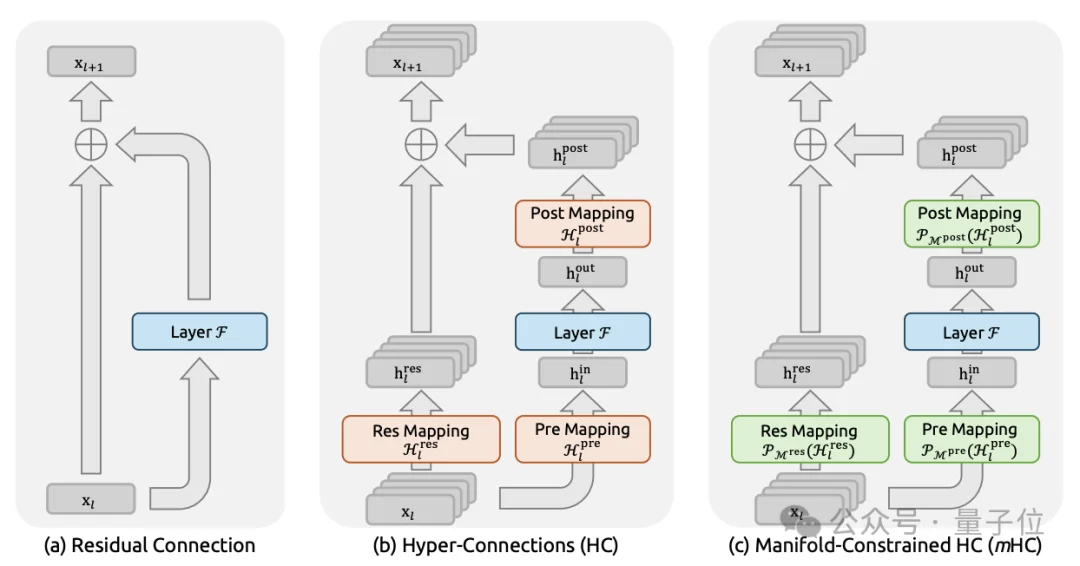
2026年新年第一天,DeepSeek上传新论文。给何恺明2016成名作ResNet中提出的深度学习基础组件“残差连接”来了一场新时代的升级。残差连接自2016年ResNet问世以来,一直是深度学习架构的基石。

机器之心发布 随着 ChatGPT、Gemini、DeepSeek-V3、Kimi-K2 等主流大模型纷纷采用混合专家架构(Mixture-of-Experts, MoE)及专家并行策略(Expert

近日,来自伊利诺伊大学芝加哥分校、纽约大学、与蒙纳士大学的联合团队提出QuCo-RAG,首次跳出「从模型自己内部信号来评估不确定性」的思维定式,转而用预训练语料的客观统计来量化不确定性,

围绕这一挑战,上海人工智能实验室联合复旦大学、南京大学、南洋理工大学 S-Lab 等单位提出了 LongVie 2—— 一个能够生成长达 5 分钟高保真、可控视频的世界模型框架。

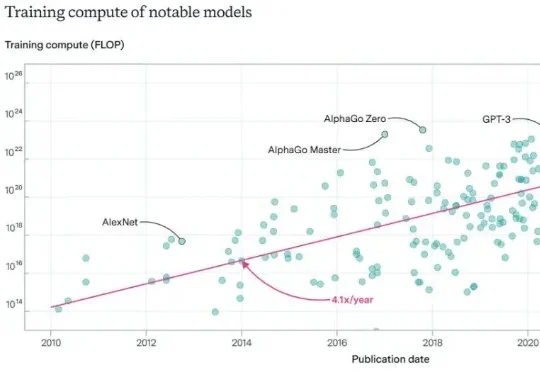
2026年,Scaling Law是否还能继续玩下去?对于这个问题,一篇来自DeepMind华人研究员的万字长文在社交网络火了:Scaling Law没死!算力依然就是正义,AGI才刚刚上路。
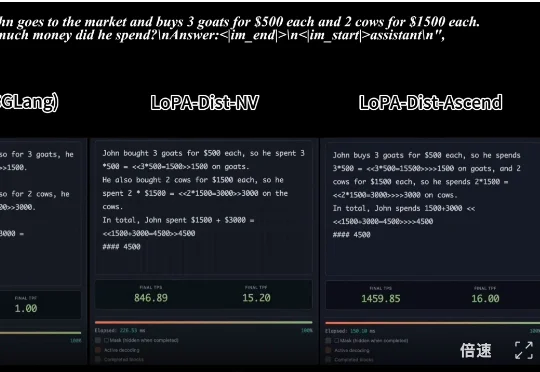
,时长 00:20 视频 1:单样例推理速度对比:SGLang 部署的 Qwen3-8B (NVIDIA) vs. LoPA-Dist 部署 (NVIDIA & Ascend)(注:NVIDIA 平台
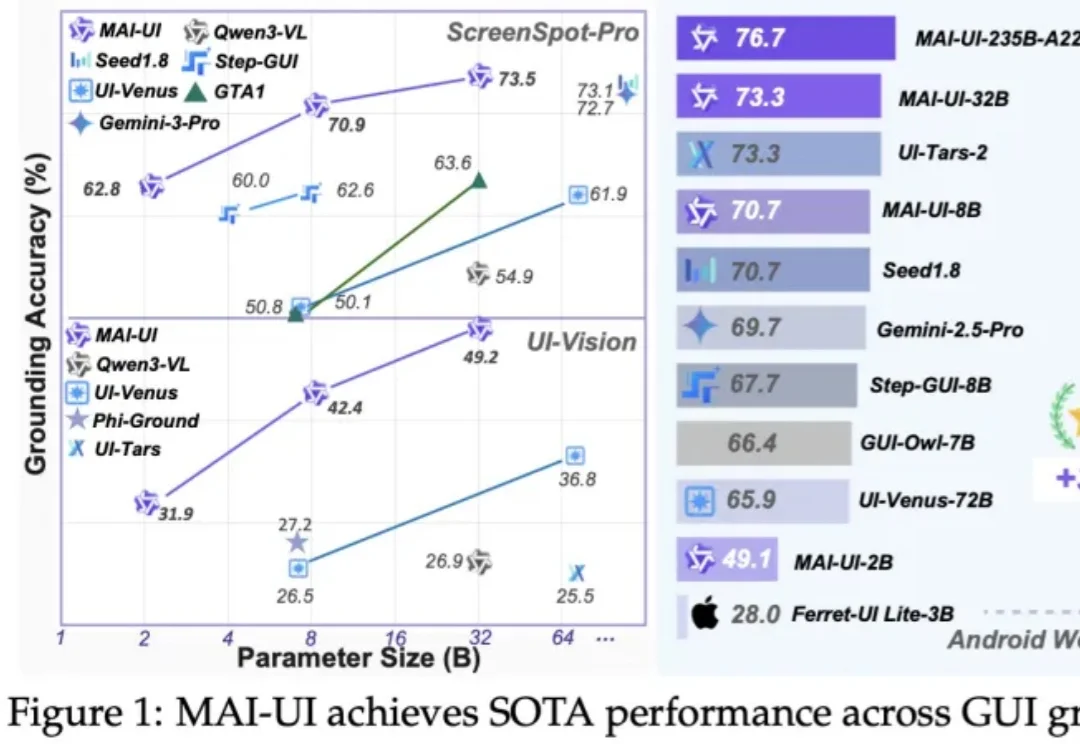
AI手机的“灵魂”GUI智能体,就这么全套开源了。
新加坡国立大学(NUS)的尤洋教授近期发表了一篇深度分析:《智能增长的瓶颈》。在这篇分析文章中,尤洋教授从技术本质出发,直指智能增长的核心矛盾,为我们揭示了 AGI(通用人工智能)的可能路径。
很多人可能不知道,我是 Trae 的老用户。
大家好,我是鲁工。 上周发布了一篇关于如何在Antigravity中组合Claude Opus 4.5和Gemini 3 Pro进行交叉验证的文章,读者反馈不错。
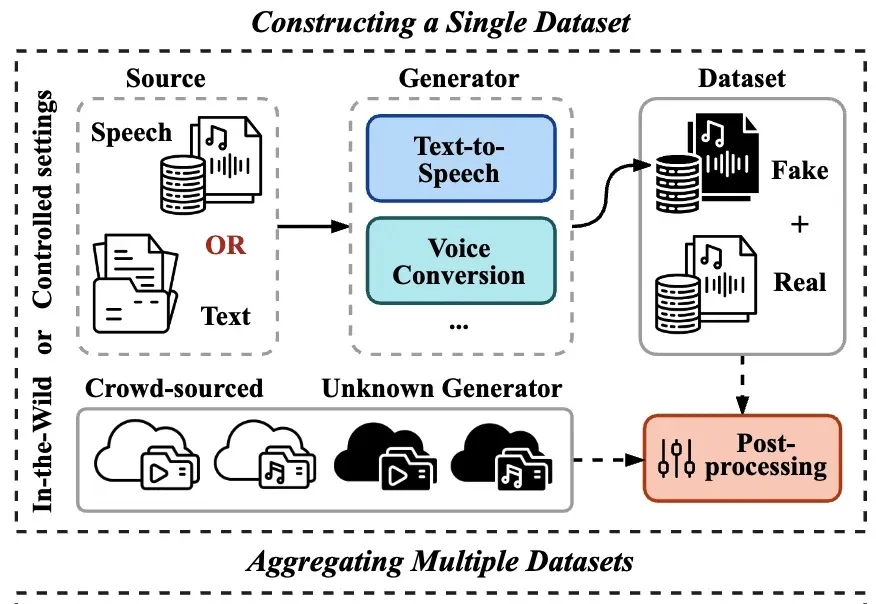
在生成式 AI 技术日新月异的背景下,合成语音的逼真度已达到真假难辨的水平,随之而来的语音欺诈与信息伪造风险也愈演愈烈。作为应对手段,语音鉴伪技术已成为信息安全领域的研究重心。
2025最后几天,是时候来看点年度宝藏论文了。
能翻译33语种+5方言,医学术语/粤语翻译实测“能打”。
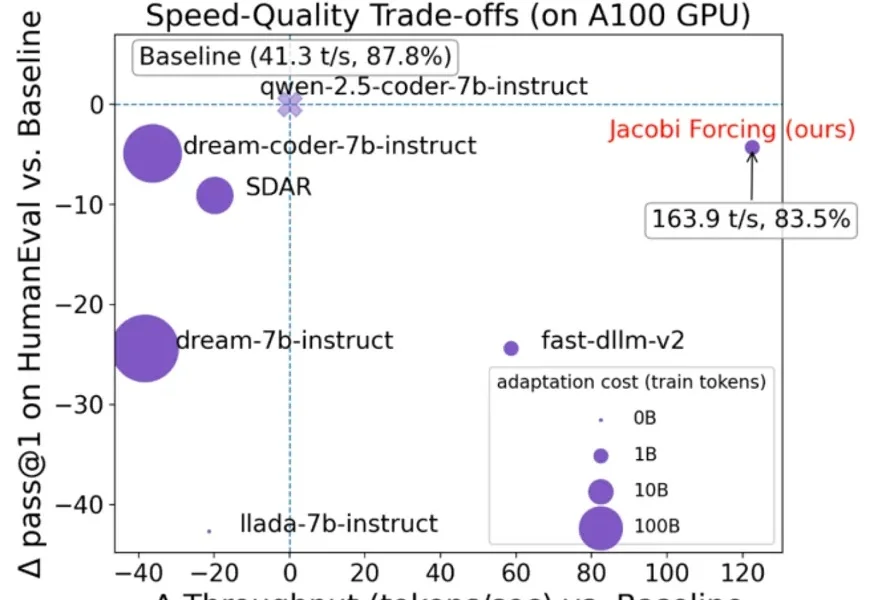
在大语言模型(LLM)落地应用中,推理速度始终是制约效率的核心瓶颈。传统自回归(AR)解码虽能保证生成质量,却需逐 token 串行计算,速度极为缓慢;扩散型 LLM(dLLMs)虽支持并行解码,却面
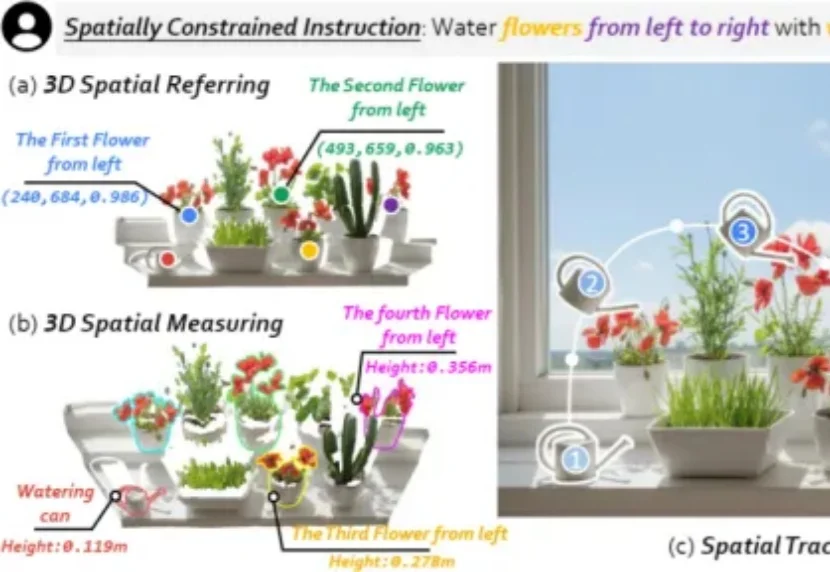
我们希望具身机器人真正走进真实世界,尤其走进每个人的家里,帮我们完成浇花、收纳、清洁等日常任务。但家庭环境不像实验室那样干净、单一、可控:物体种类多、摆放杂、随时会变化,这让机器人在三维物理世界中「看懂并做好」变得更难。

作为一名 AI 领域的博士生,徐玉庄的经历比较特殊。本科毕业于国防科技大学,随后在部队工作了 5 年,接着在清华大学获得硕士学位,目前在哈尔滨工业大学读博。
上上周跟大家盘了 Gemini 学生教育优惠。
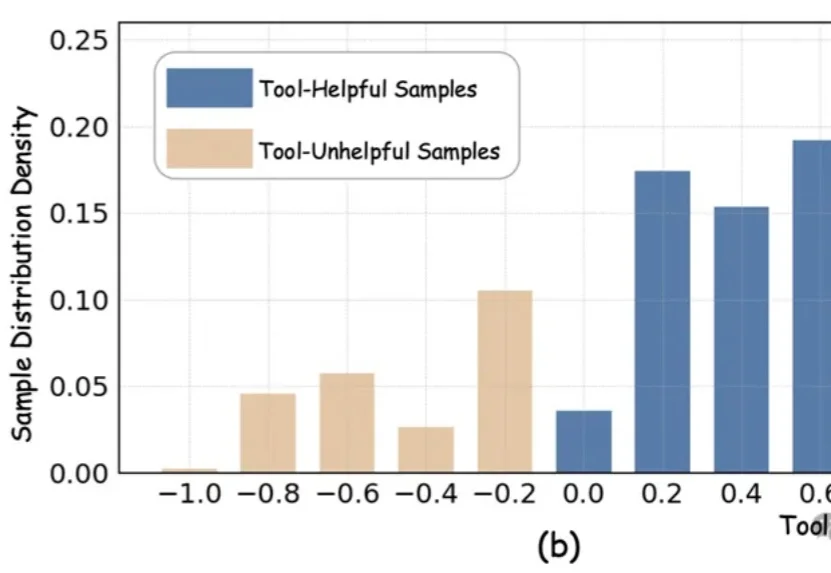
近期,以DeepEyes、Thymes为代表的类o3模型通过调用视觉工具,突破了传统纯文本CoT的限制,在视觉推理任务中取得了优异表现。
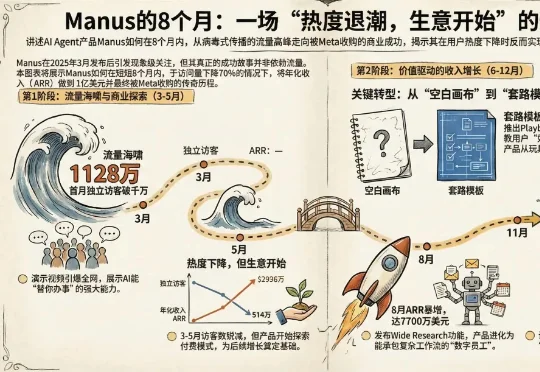
Manus被Meta收购的消息在AI圈刷屏了。 交易细节尚未完全公开,但Meta的态度很明确:它不仅要把Manus的能力整合进自家产品(包括Meta AI),还计划继续把Manus作为独立服务运营和销
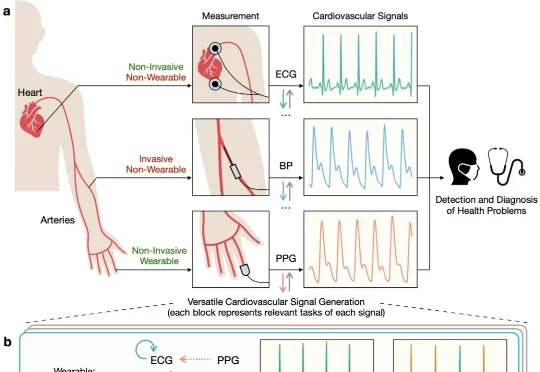
近日,清华朱军等团队提出了一种统一的多模态生成框架 UniCardio,在单扩散模型中同时实现了心血管信号的去噪、插补与跨模态生成,为真实场景下的人工智能辅助医疗提供了一种新的解决思路。

史上首次,ICLR成立后设立机制设计相关Workshop,全球顶流学者众神云集!
大家好,我是艾逗笔。 今天我花了一天时间,招聘了 6 个 AI 员工,帮助他们走完了入职流程,给他们分配了工作权限,了解了他们各自的特点和能力,然后安排了一个工作间,让他们在一起开始干活了。
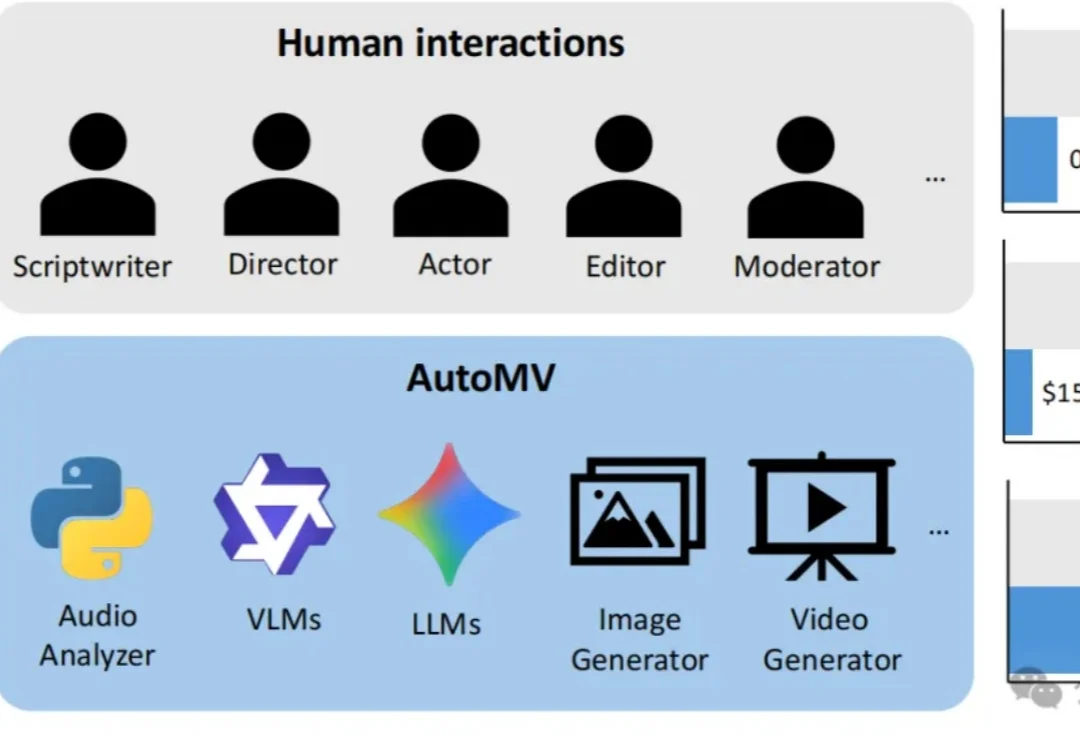
现有的AI视频生成模型虽然在短片上效果惊人,但面对一首完整的歌曲时往往束手无策——画面不连贯、人物换脸、甚至完全不理会歌词含义。
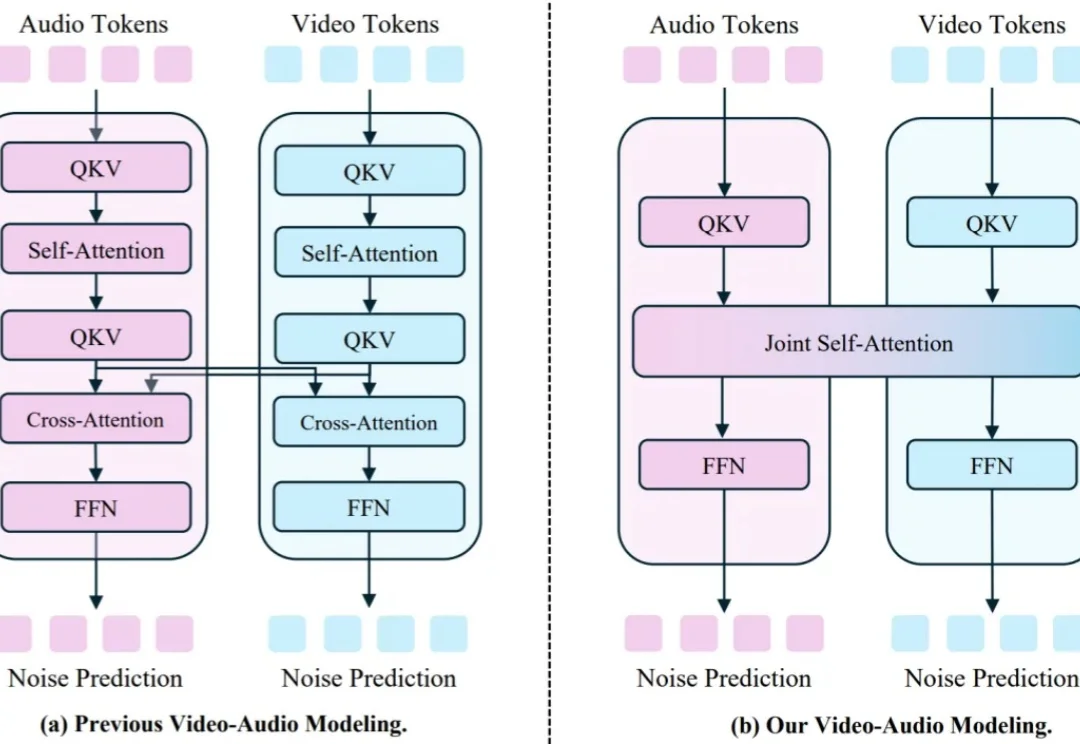
视频 - 音频联合生成的研究近期在开源与闭源社区都备受关注,其中,如何生成音视频对齐的内容是研究的重点。
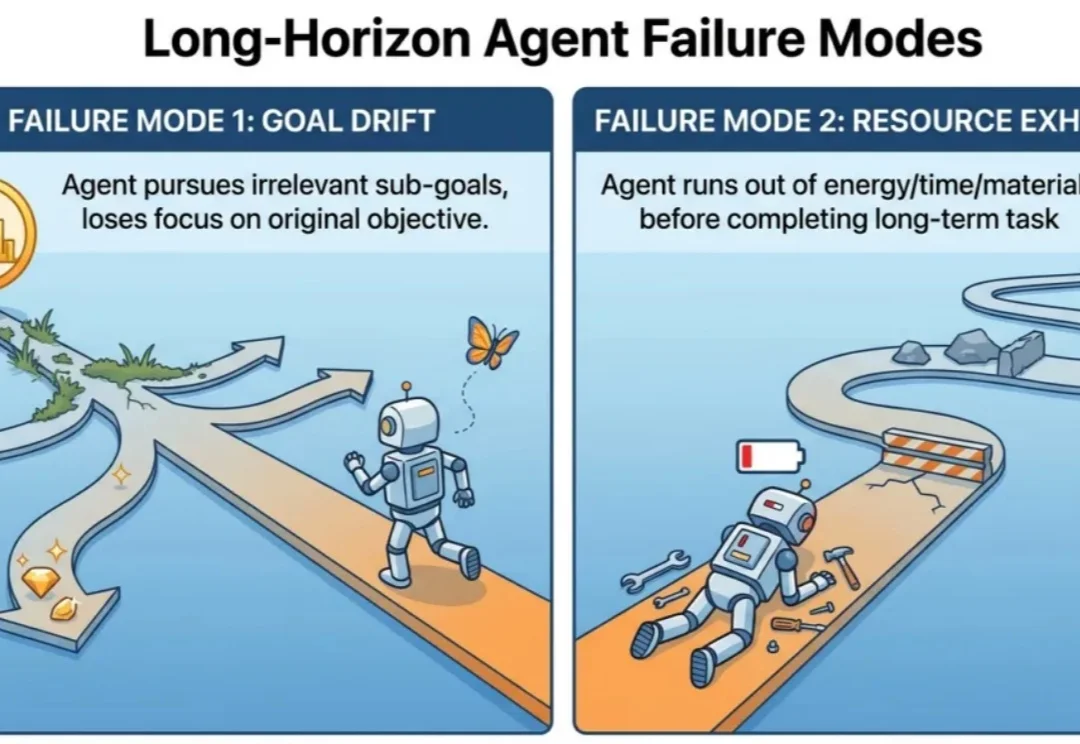
做agent简单,但是做能落地的agent难,做能落地的长周期agent更是难上加难!

在空间智能(Spatial Intelligence)飞速发展的今天,全景视角因其 360° 的环绕覆盖能力,成为了机器人导航、自动驾驶及虚拟现实的核心基石。然而,全景深度估计长期面临 “数据荒” 与 “模型泛化差” 的瓶颈。
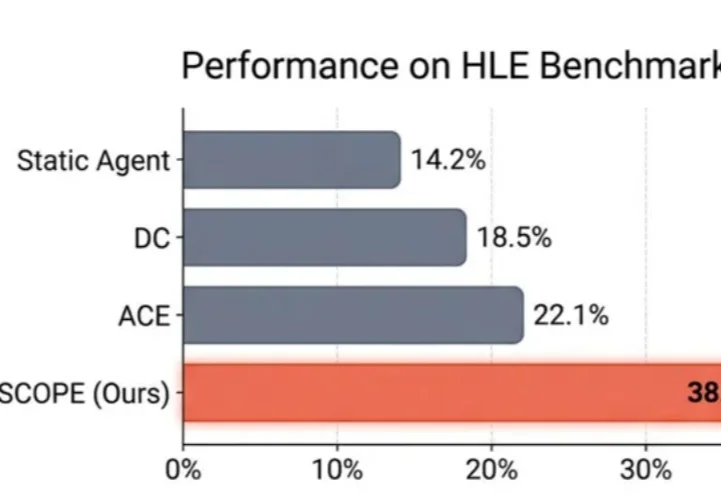
在 LLM Agent 领域,有一个常见的问题:Agent 明明 "看到了" 错误信息,却总是重蹈覆辙。

在电影与虚拟制作中,「看清一个人」从来不是看清某一帧。导演通过镜头运动与光线变化,让观众在不同视角、不同光照条件下逐步建立对一个角色的完整认知。然而,在当前大量 customizing video generation model 的研究中,这个最基本的事实,却往往被忽视。

近日,刚刚 IPO 的国产 GPU 公司沐曦股份,完成了自上市后的首个重大技术发布。