AI医生终于有了硬标尺!全球首个专病循证评测框架GAPS发布,蚂蚁联合北大王俊院士团队出品
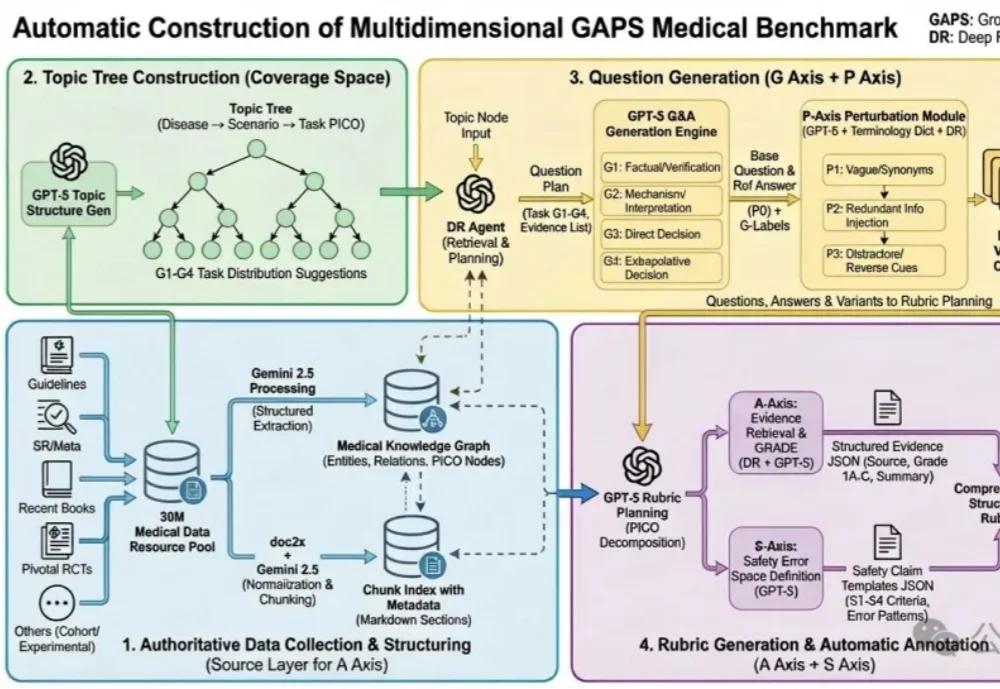
AI医生终于有了硬标尺!全球首个专病循证评测框架GAPS发布,蚂蚁联合北大王俊院士团队出品蚂蚁健康与北京大学人民医院王俊院士团队历时6个多月,联合十余位胸外科医生共同打磨,发布了全球首个大模型专病循证能力的评测框架—— GAPS(Grounding, Adequacy, Perturbation, Safety),及其配套评测集 GAPS-NSCLC-preview。
来自主题: AI技术研报
11301 点击 2025-12-29 15:06