
WorkBuddy日活破千万了,KroWork还在角落里吃灰,快手这张牌到底怎么打
WorkBuddy日活破千万了,KroWork还在角落里吃灰,快手这张牌到底怎么打4月30号,快手Krow团队推出了一款桌面端AI智能体KroWork,在这里你不用写一行代码,对着它说一句话,它就能自己写代码、调试、部署,最后交付一个能直接在桌面运行的应用。
来自主题: AI资讯
5421 点击 2026-07-14 10:36
 搜索
搜索
4月30号,快手Krow团队推出了一款桌面端AI智能体KroWork,在这里你不用写一行代码,对着它说一句话,它就能自己写代码、调试、部署,最后交付一个能直接在桌面运行的应用。
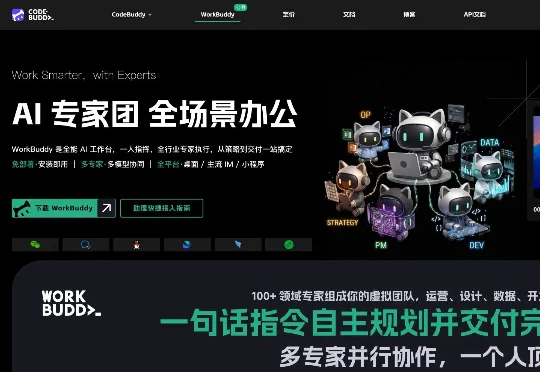
WorkBuddy最近很火,实测下来的体感是,harness层似乎搭建得还不错,而且对国内模型的兼容度都做得很好,少有的国内应用厂商做出来的、基于国产模型的可用Agent产品。 这篇文章来自 Work
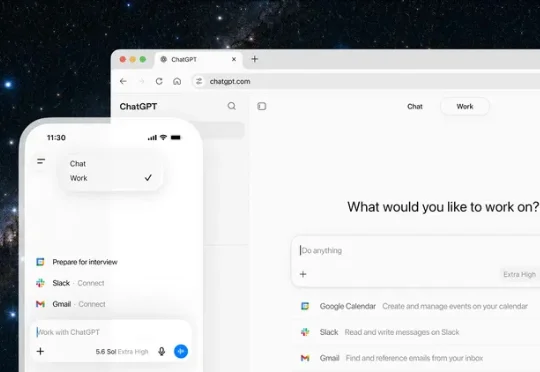
7 月 9 日,OpenAI 一口气发了三样东西,新模型 GPT-5.6,一个把 Chat、Work、Codex 装进同一个壳的新桌面应用,以及本文的主角 ChatGPT Work。官方的说法是,ChatGPT 从此不再只是回答问题,而是把活真正干完,交出来的不是聊天记录,是表格、文档、PPT,甚至一个能直接分享的网站。

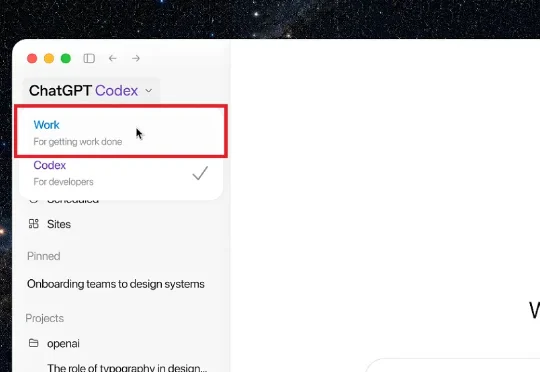
与模型更新相对应,原先的 Codex 应用改名为「ChatGPT Codex」,完全更新了一轮。它被做成了所谓的超级应用,界面也几乎重新设计了一遍,把 ChatGPT 与 Codex 结合到了一起。下面说一说现在的 ChatGPT Codex 到底该怎么用,出一个新手的完全究极教程。

今天 APPSO 去了百度在成都举办的 AI DAY「干活吧!搭子」专场,百度搭子一口气抛出三个发布——个人版大升级,企业版正式登场,围绕企业应用,百度还拉起了一个生态联盟。

7月10日,光合组织2026智能计算应用大会上,中科曙光掷地有声地抛出一个数字:十万。中国首个全国产十万卡AI超集群——曙光8000(登峰),正式落成,并依托国家超算互联网,火速接入全国一体化算力网。
今天凌晨,OpenAI进行线上直播,正式面向全球用户推出新一代GPT-5.6模型家族,并同步发布Agent产品ChatGPT Work、全新ChatGPT桌面应用以及Hosted Sites(托管网站)三大产品更新。
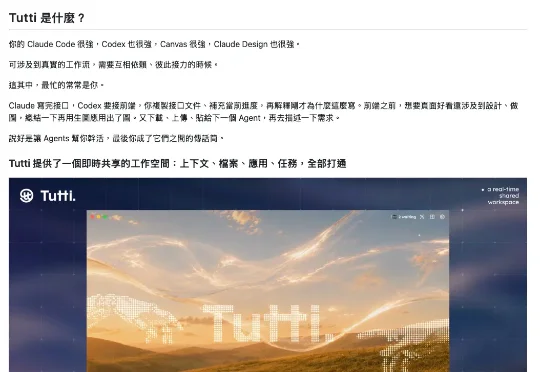
我天天在ai news radar里刷呀刷,真刷出了个新的开源项目,Tutti。光看Readme的时候,我以为它又是一套给Agent套GUI的桌面壳,实际上它提供了一个实时共享的工作空间,我所有agent可以共享上下文,文件,应用和任务。
腾讯旗下的AI应用生成及灵感共创平台“吐司” iOS版正式上线。这标志着吐司完成了移动端双平台(iOS+Android)的全量覆盖,让更多用户能够随时随地,通过自然语言对话创造应用。作为一款零门槛的Vibe Coding产品,吐司旨在满足大量真实、细碎、且个性化的应用需求。

去年 12 月,我们曾与 Ancher 联合创始人兼 CEO Vincent Wu 进行了一次深度对话,Vincent 曾任雅虎新闻运营总监、NewsBreak COO,深耕美国新闻近 20年,所以在初期,Ancher 以“Agentic News Reader”为核心定位,以“语义层推荐”作为主要差异化。