
AI顶会Poster整活大赛:我的NeurIPS论文中了ICML
AI顶会Poster整活大赛:我的NeurIPS论文中了ICMLAI 顶会越来越卷了,卷的方向你还猜不到。本周,国际机器学习大会 ICML 在韩国首尔举行。今年 ICML 的 Poster 环节,除了那些极具创新性的论文,也堪称大型学术行为艺术现场。
来自主题: AI资讯
9352 点击 2026-07-12 10:49
 搜索
搜索
AI 顶会越来越卷了,卷的方向你还猜不到。本周,国际机器学习大会 ICML 在韩国首尔举行。今年 ICML 的 Poster 环节,除了那些极具创新性的论文,也堪称大型学术行为艺术现场。
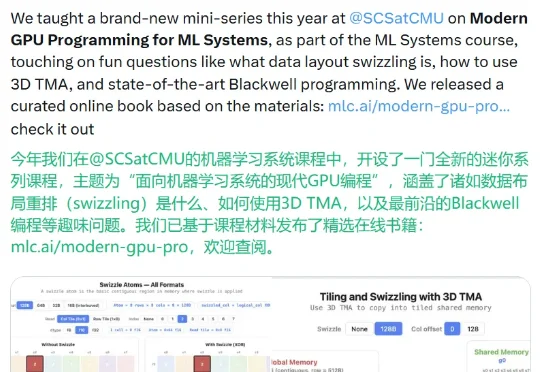
前些天,CMU 助理教授、TVM/XGBoost/MLC-LLM 的创造者陈天奇发布了一本免费在线书籍《Modern GPU Programming For MLSys(面向机器学习系统的现代 GPU 编程)》。
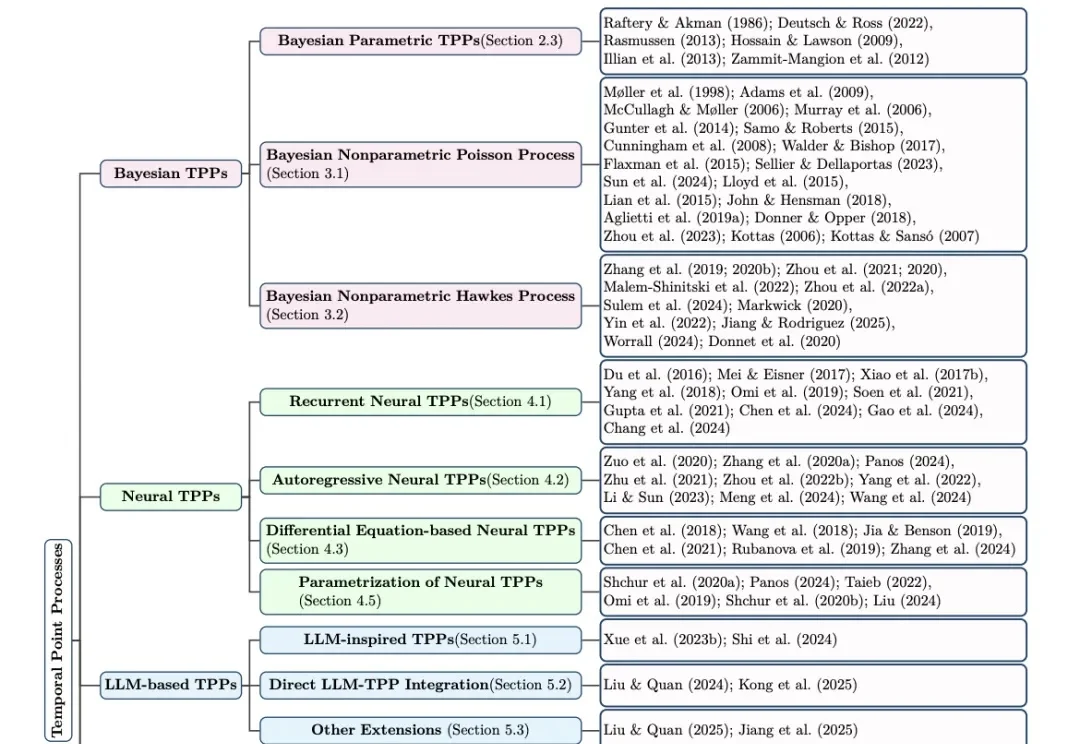
机器学习已经习惯了处理序列:一句话中的词、视频中的帧、推荐系统中的点击、金融市场中的订单。但在很多真实场景里,数据并不是按固定步长排好队出现的。
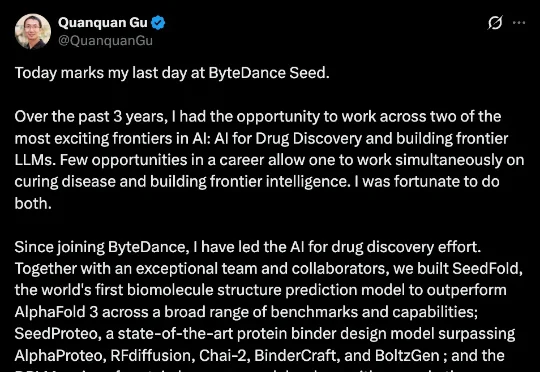
刚刚,顾全全发文告别字节 Seed 团队。在此之前,他是 Seed 旗下聚焦科学智能领域的 AI4S 团队核心成员。顾全全是机器学习理论、大模型对齐以及 AI4S 科学智能领域知名的学者。他于 2007 年和 2010 年分获清华大学自动化专业学士、控制科学与工程硕士学位,2014 年获伊利诺伊大学香槟分校计算机科学博士学位,随后在普林斯顿大学运筹与金融工程系(ORFE)开展统计学博士后研究。

今天凌晨,俄勒冈州立大学杰出教授(荣休)、arXiv 计算机科学分区 CoRR 的机器学习板块首席版主 Thomas G. Dietterich 宣布:根据我们的行为准则,在论文上署名即表示每位作者对其全部内容承担完全责任,无论这些内容是如何生成的。

今天,OpenAI 官方播客发布了一期节目,让内部研究员 Sebastian Bubeck 和 Ernest Ryu 出来回答这一问题,毕竟大家都十分好奇。Ernest 近期刚加入 OpenAI 担任研究员,他之前是加州大学洛杉矶分校(UCLA)数学系的教授,研究优化和机器学习理论。他是最早尝试用 ChatGPT 解数学开放问题的那批人之一。

中国人民大学团队打造的AiScientist,旨在解决长程机器学习研究工程的持续性难题。该系统从论文理解开始,跨越环境配置、代码实现与实验迭代,保持状态连续与决策连贯,显著提升科研效率。其核心在于通过File-as-Bus机制,稳定保存项目状态,使AI能真正接手科研流程,而非仅辅助单个环节。
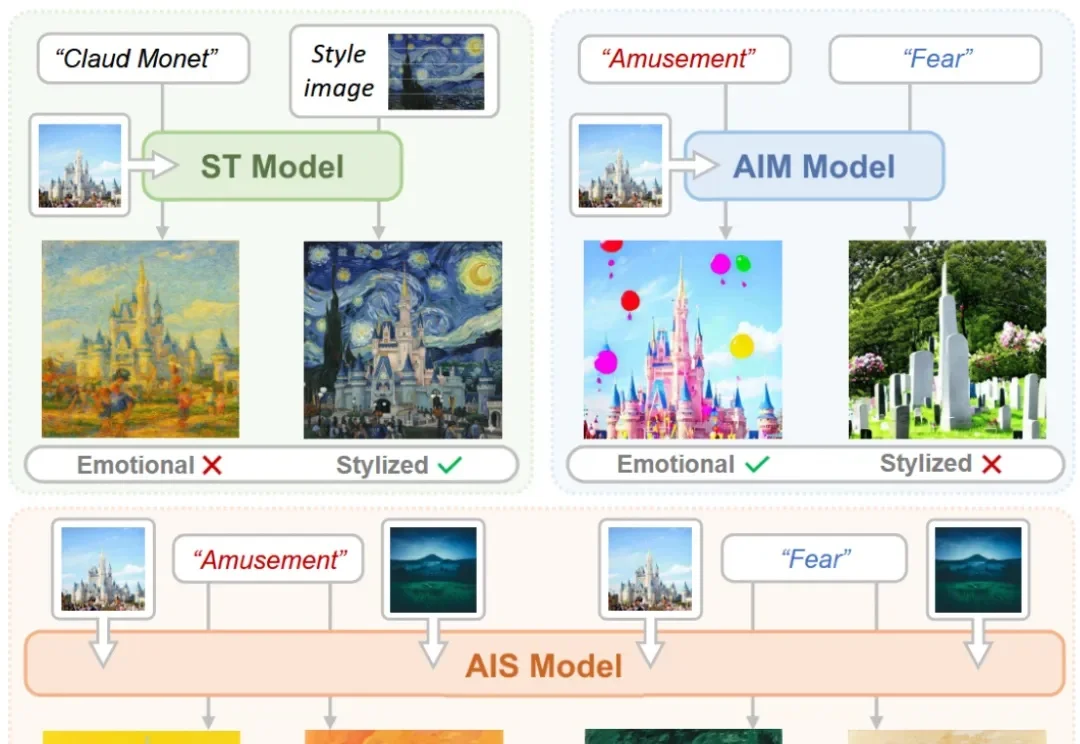
EmoStyle 由深圳大学可视计算研究中心黄惠教授课题组独立完成,第一作者为杨景媛助理教授,第二作者为研二硕士生柏梓桓。深圳大学可视计算研究中心(VCC)以计算机图形学、计算机视觉、人机交互、机器学习、具身智能、可视化和可视分析为学科基础,致力前沿探索与跨学科创新。

本篇文章被 ICRA 2026 接收并获得 IROS 2025 双料 Workshop 最佳论文,第一作者张子哲(site: zizhe.io)是宾夕法尼亚大学机器人学硕士生,同时在 GRASP 实验室担任科研助理,导师为 Nadia Figueroa 教授,研究兴趣涵盖机器学习,安全控制以及人机交互。
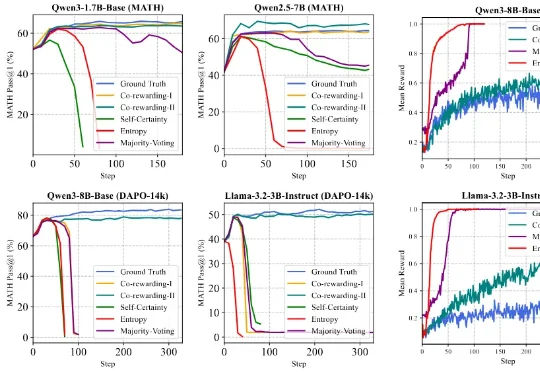
针对这一挑战,来自香港浸会大学和上海交通大学的可信机器学习和推理组提出了一个全新的自监督 RL 框架 ——Co-rewarding。该框架通过在数据端或模型端引入互补视角的自监督信号,稳定奖励获取,提升 RL 过程中模型奖励投机的难度,从而有效避免 RL 训练崩溃,实现稳定训练和模型推理能力的诱导。