非Transformer架构的新突破,Liquid AI开源LFM2.5-1.2B-Thinking模型
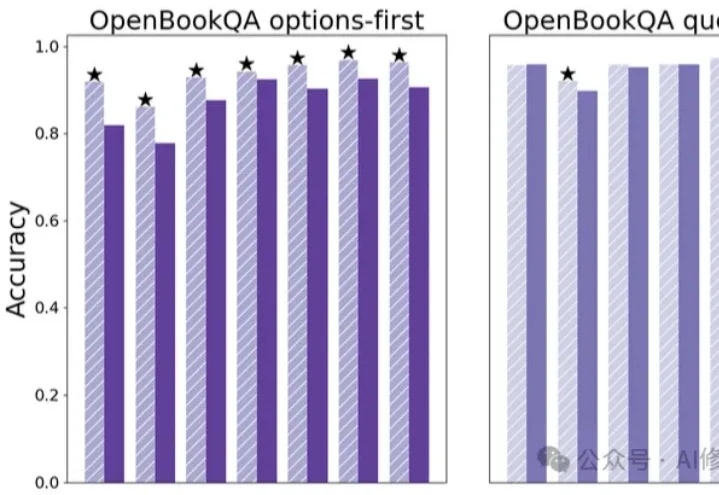
非Transformer架构的新突破,Liquid AI开源LFM2.5-1.2B-Thinking模型就在刚刚,Liquid AI 又一次在 LFM 模型上放大招。他们正式发布并开源了 LFM2.5-1.2B-Thinking,一款可完全在端侧运行的推理模型。Liquid AI 声称,该模型专门为简洁推理而训练;在生成最终答案前,会先生成内部思考轨迹;在端侧级别的低延迟条件下,实现系统化的问题求解;在工具使用、数学推理和指令遵循方面表现尤为出色。
来自主题: AI资讯
9420 点击 2026-01-22 11:59