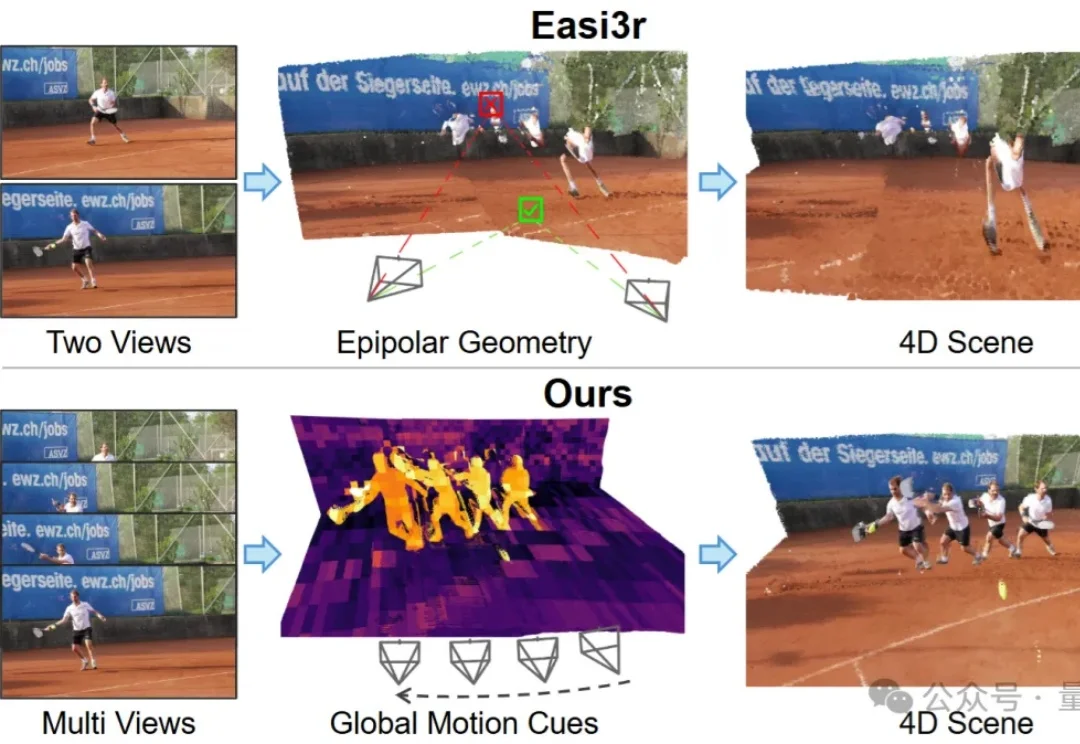
挖掘注意力中的运动线索:无需训练,解锁4D场景重建能力
挖掘注意力中的运动线索:无需训练,解锁4D场景重建能力如何让针对静态场景训练的3D基础模型(3D Foundation Models),在不增加训练成本的前提下,具备处理动态4D场景的能力?
来自主题: AI技术研报
10976 点击 2025-12-18 09:48
 搜索
搜索
如何让针对静态场景训练的3D基础模型(3D Foundation Models),在不增加训练成本的前提下,具备处理动态4D场景的能力?
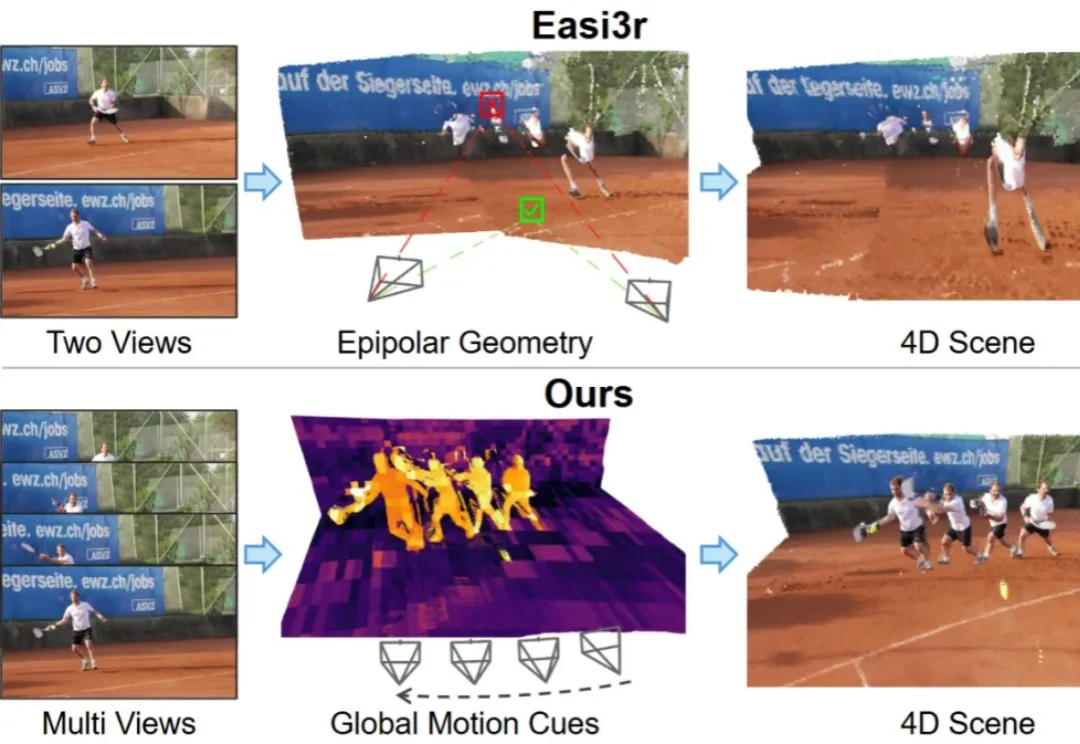
如何让针对静态场景训练的 3D 基础模型(3D Foundation Models)在不增加训练成本的前提下,具备处理动态 4D 场景的能力?

「仅需一次前向推理,即可预测相机参数、深度图、点云与 3D 轨迹 ——VGGT 如何重新定义 3D 视觉?」

3D大模型公司VAST完成亿元级融资。

老黄预言AI生成游戏的未来,很快就要实现了!在一年一度Roblox开发者大会上,CEO官宣了3D基础模型,仅用文本提示便可生成3D物体。未来目标,便要瞄准10亿玩家,AI视频游戏大爆发时代不远了。

来自南洋理工大学、上海AI实验室等机构的研究人员,共同推出了新款文生3D基础模型3DTopia。只需要一组文本,它就可以在5分钟内生成出多样化、高精度的3D模型。