

谷歌看了都沉默:自家「黑科技」火了,但为啥研发团队一无所知?
谷歌看了都沉默:自家「黑科技」火了,但为啥研发团队一无所知?当整个科技圈都在为「谷歌黑魔法」集体高潮时,真相恐给了所有人一记耳光。那套被捧上神坛的「并行验证循环」,不过是社交网络上AI生成的「赛博跳大神」。
来自主题: AI技术研报
9877 点击 2026-01-08 08:44
当整个科技圈都在为「谷歌黑魔法」集体高潮时,真相恐给了所有人一记耳光。那套被捧上神坛的「并行验证循环」,不过是社交网络上AI生成的「赛博跳大神」。

FaithLens 模型在忠实性幻觉检测任务上,达到了当前最优效果。
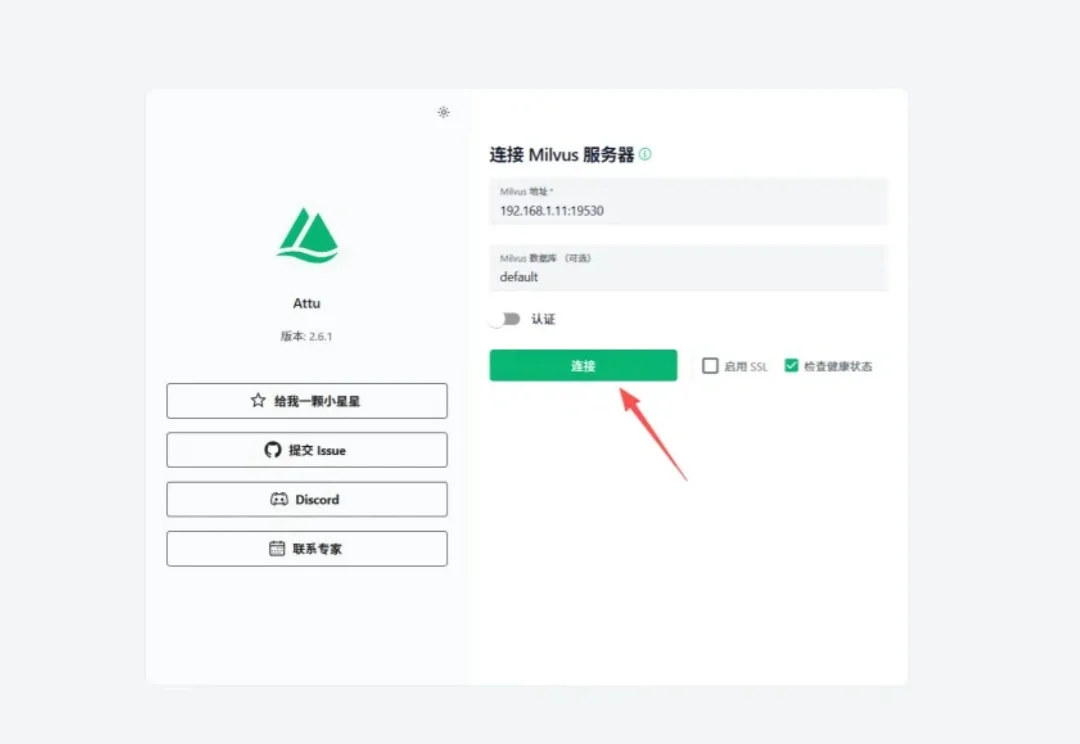
今天在讲Milvus的Attu之前,我们先来唠一段计算机行业的八卦。

AI 语音模型测试第三弹。
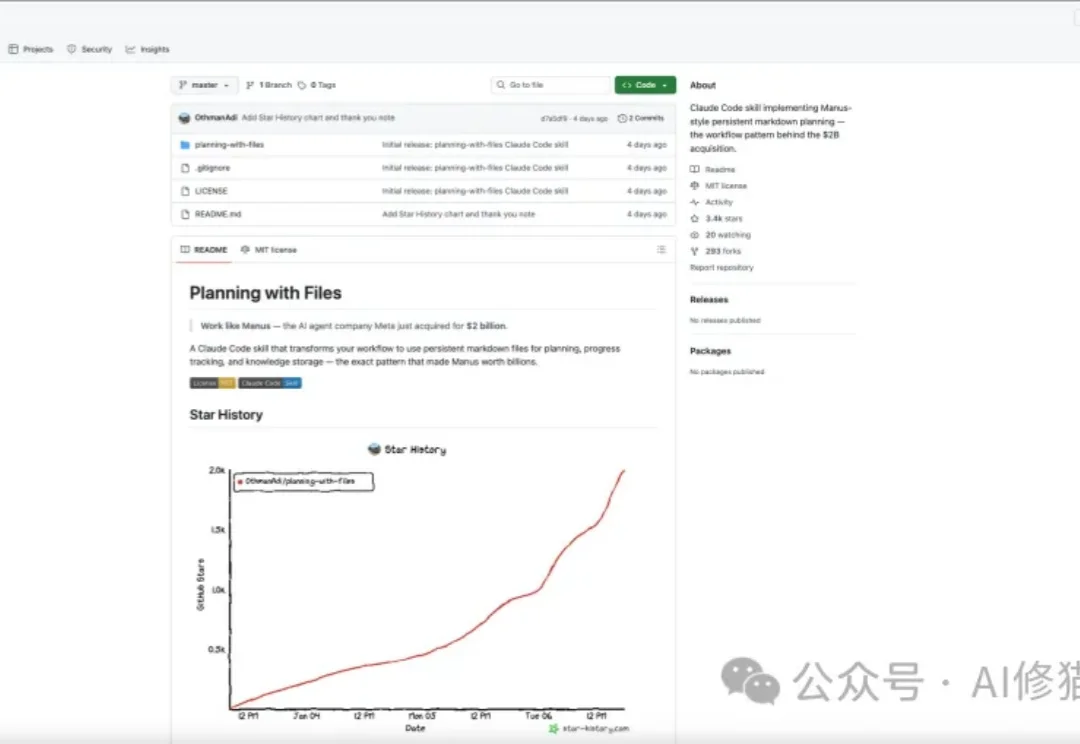
planning-with-files是开源社区最近疯传的一个Skill,发布仅四天收获3.3k star。目前还在持续增长。
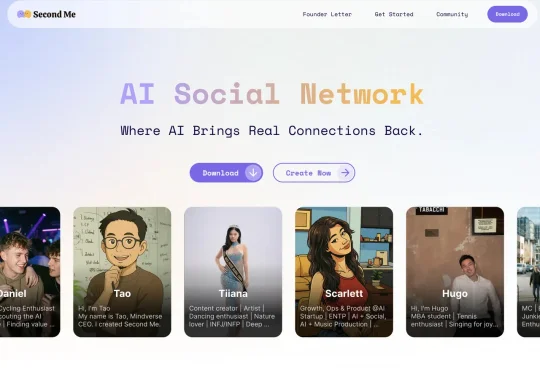
之前跟Tao博合作过很多次,从MindOS到Mebot,听说最近Second Me新版上线了,马上第一时间体验了一下,于是就有了这篇文章。Second Me 这次重点更新了 AI 社交玩法,体验是很有意思的。

一场AI界的《创造101》火了!LMArena让你盲投选出最强AI,三年从校园项目逆袭,刚刚融1.5亿美元,估值飙到17亿美元。众包投票挑战专家权威,争议四起,却已成行业标杆。你的票,就能决定下一个AI顶流!
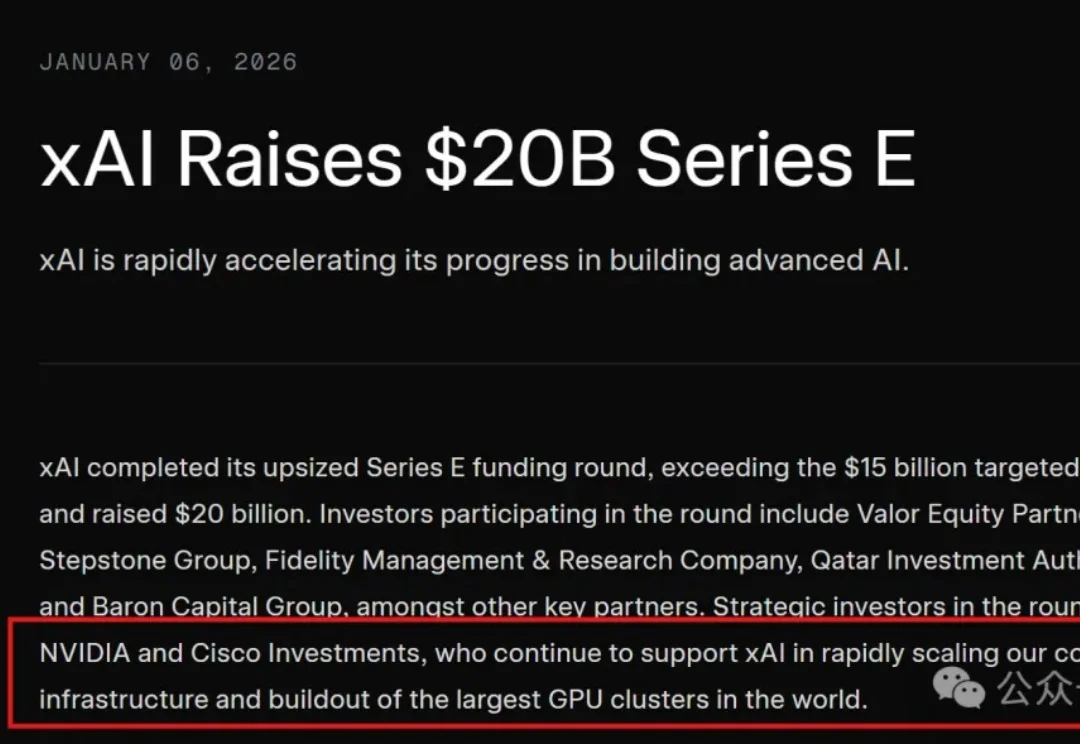
刚开年,马斯克就到账了200亿美金!(是谁听到了金币的声音~

当大模型竞争转向后训练,继续为闲置显卡烧钱无异于「慢性自杀」。如今,按Token计费的Serverless模式,彻底终结了算力租赁的暴利时代,让算法工程师真正拥有了定义物理世界的权利。
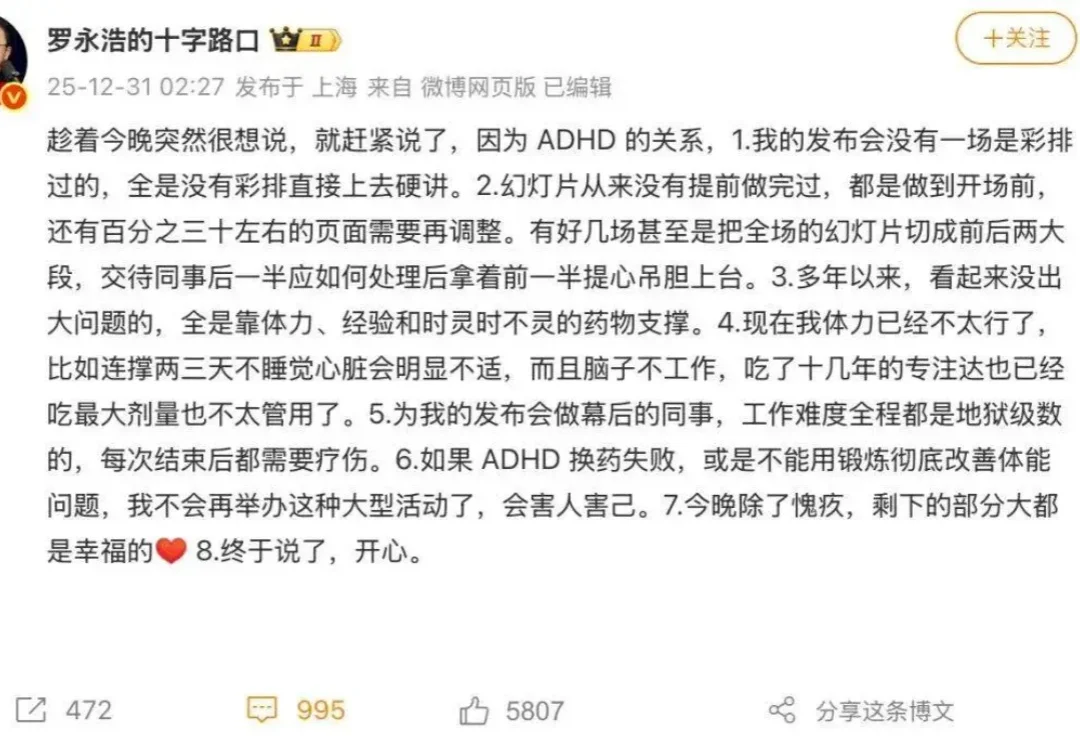
在迟到了 40 分钟之后,老罗终于在 2025 年的最后一天,站上了科技春晚的舞台。对那些枯等了许久的现场观众,他给到的除了免票,还有一个「理由」:ADHD。