5k星星!无GPU都能跑的「开源声音克隆工具」,646种语言,多系统支持一键安装
5k星星!无GPU都能跑的「开源声音克隆工具」,646种语言,多系统支持一键安装ElevenLabs的声音克隆和长文本音频生成质量确实很好,但也太贵了。
来自主题: AI资讯
6814 点击 2026-05-29 10:10
 搜索
搜索
ElevenLabs的声音克隆和长文本音频生成质量确实很好,但也太贵了。
继 SAM(Segment Anything Model)、SAM 3D 后,Meta 又有了新动作。

最近在网络上,你很难躲过《大东北我的家乡》的各种AI翻唱版本,男声、女声,粤语版、四川话版,爵士、布鲁斯版等等,引发一波互联网文化热潮。

谁能想到,AI把ASMR也给干了...... 那是一个困倦的午后,吃饱饭的我正瘫在工位上准备入眠。我瘫在椅子上,耳机里传来轻柔的ASMR助眠声音。那里的毛刷轻轻刮着麦克风,发出微弱的、令人神经愉悦的摩擦音。而我也在这声音的安抚下昏昏欲睡。

一段令人心碎的离别视频走红:小女孩与AI玩具的深情告别,揭示了对话式AI如何悄然融入人类情感世界,预示着实时交互技术的革命性突破。

你有多久没试过在用 AI 写歌的时候又唱又跳了?——没有人在用 AI 写歌的时候又唱又跳!这是 YouTube 上的一位音乐博主,本想用音乐生成软件做一些糟糕的 AI 音乐,取笑一下人工智能,却意外得到了「味挺正」的日本金属摇滚,一下子就在 TikTok 上迅速爆红。

在我们往期观察“AI+声音”的应用中,多是 TTS、AI 生成播客和读书/配音等方向,先有文字内容、后转化为声音输出的偏“工具”类产品。当大多数产品在探索如何用 AI 声音改变内容传播的形式时,一家德国厂商却在另一个方向持续耕耘,并且维持了不错的流水表现。
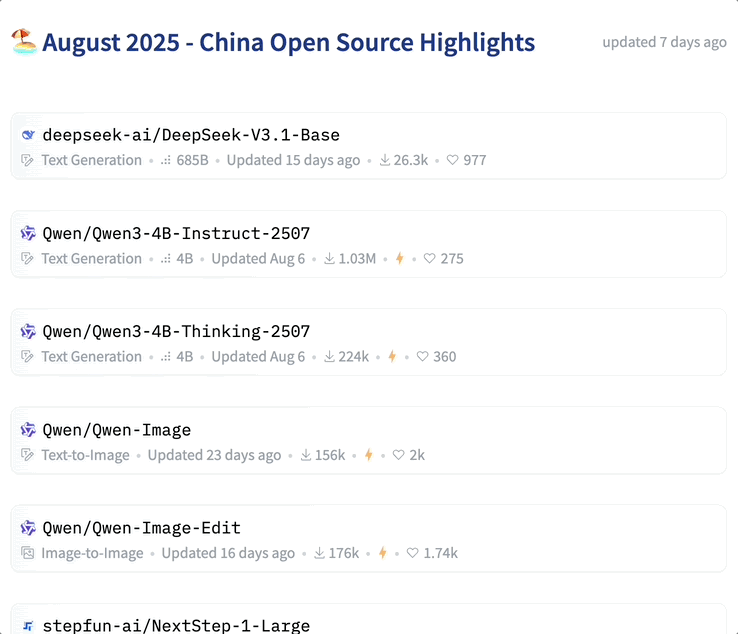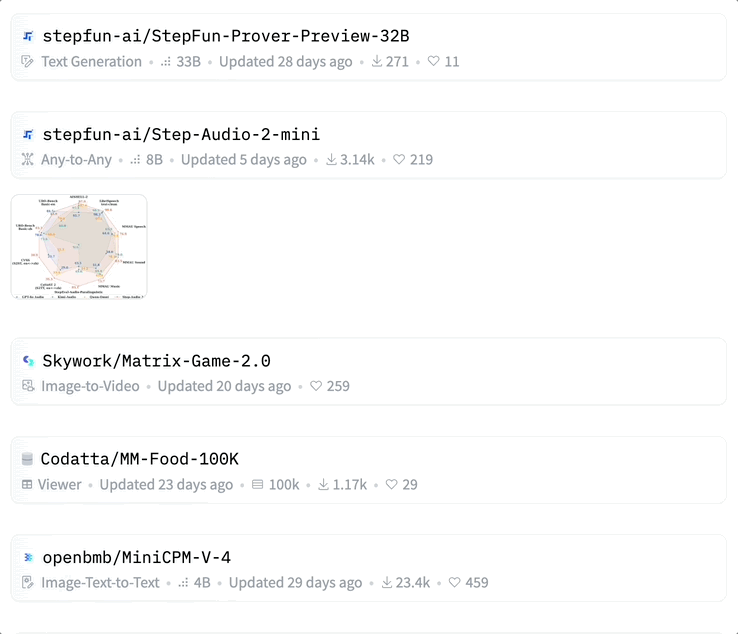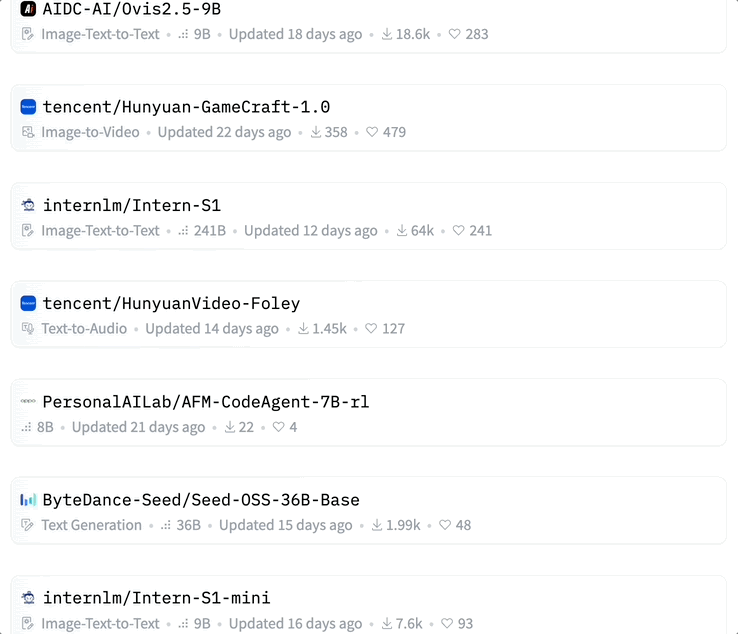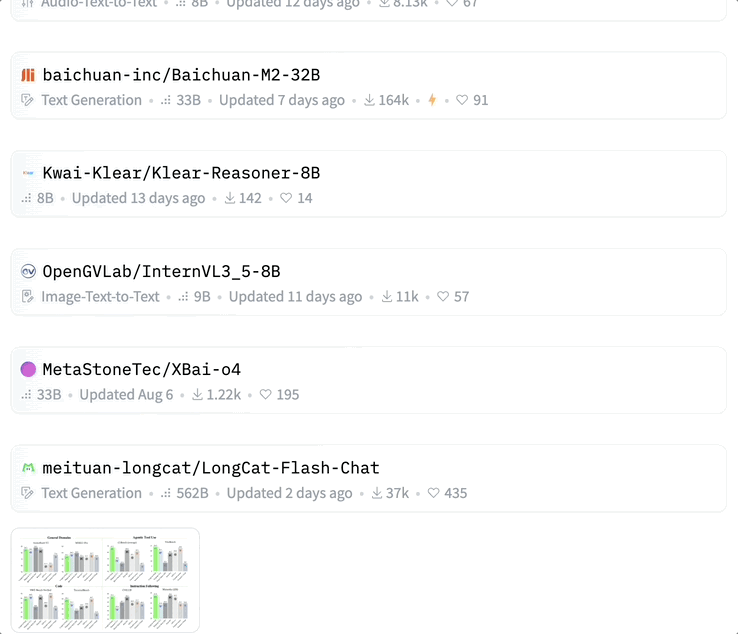
不难发现,近几个月,开源频频成为 AI 社区热议的焦点。尤其是对于国内科技公司来说,开源成为主旋律。根据 Hugging Face 中文 AI 模型与资源社区的数据显示,国内厂商在七八月接连开源 33 款、31 款各类型大模型。

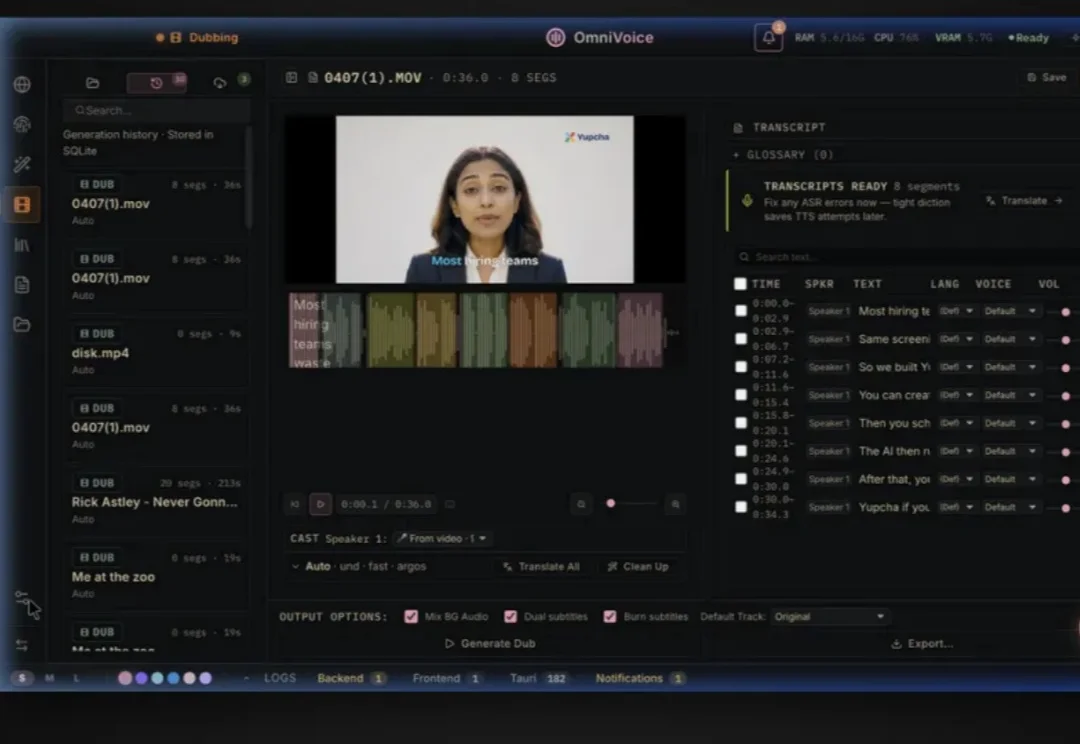
你是不是也经常遇到“AI配音”的视频?

上篇文章和大家聊了自研的多维表格编辑器pxcharts。今天和大家继续分享一款我最近发现的宝藏AI工具——AI-Media2Doc。