
四大顶级AI对决《文明VI》!Claude「核平」法国,结果还是输了
四大顶级AI对决《文明VI》!Claude「核平」法国,结果还是输了就在最近,英国前首相府数据科学家Liam Wilkinson,花一个周末搭了76个MCP工具,把Claude、GPT、Gemini等四个顶尖模型扔进了《文明VI》。结果,23场对局打完,其中一个AI造了核弹炸了法国——然后输了。
来自主题: AI资讯
8819 点击 2026-06-28 15:36
 搜索
搜索
就在最近,英国前首相府数据科学家Liam Wilkinson,花一个周末搭了76个MCP工具,把Claude、GPT、Gemini等四个顶尖模型扔进了《文明VI》。结果,23场对局打完,其中一个AI造了核弹炸了法国——然后输了。

看《堡垒之夜》的游戏录像,也能训练AI?没错,一家靠着海量游戏录像训练AI的公司General Intuition,刚刚完成3.2亿美元(约合人民币21.77亿元)融资。General Intuition公开披露的融资总额已达4.54亿美元,估值23亿美元。
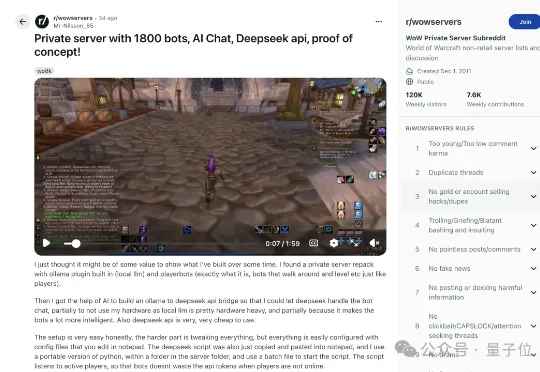
最近,一位Reddit老哥手搓了一个《魔兽世界》私服——里面活跃着1800个AI玩家,而且全都接入了DeepSeek API,能像真人一样聊天、组队、于是,暴风城的聊天频道突然变成了DeepSeek广场,画风大概是这样的:
这个周末,我被一个网页小游戏钓住了,津津有味地打了大半天。
和传统的游戏自动化脚本不同,这是一个完整的通用的大模型,不仅限于单一游戏的操作,能够玩遍市面上几乎全部的游戏类型。于是,让我们正式介绍主角,来自英伟达的最新开源基础模型 NitroGen。该模型的训练目标是玩 1000 款以上的游戏 —— 无论是 RPG、平台跳跃、吃鸡、竞速,还是 2D、3D 游戏,统统不在话下!

今天凌晨,“硅谷钢铁侠”马斯克宣战了!他在 X 帖子中提出了一项引来1500多万网友围观的挑战:让Grok 5在2026年以人类视觉和反应速度限制下,对战《英雄联盟》顶级人类战队。
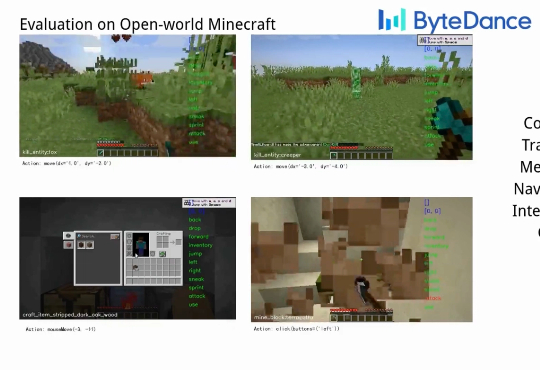
Game-TARS基于统一、可扩展的键盘—鼠标动作空间训练,可在操作系统、网页与模拟环境中进行大规模预训练。依托超5000亿标注量级的多模态训练数据,结合稀疏推理(Sparse-Thinking) 与衰减持续损失(decaying continual loss),大幅提升了智能体的可扩展性和泛化性。

一群AI玩狼人杀,GPT-5断崖式领先,胜率达到了惊人的96.7%。 OpenAI的总裁格雷格·布罗克曼转发了这样的一个基准测试:让7个强大的LLMs,包括开源和闭源,玩了210场完整的狼人杀。
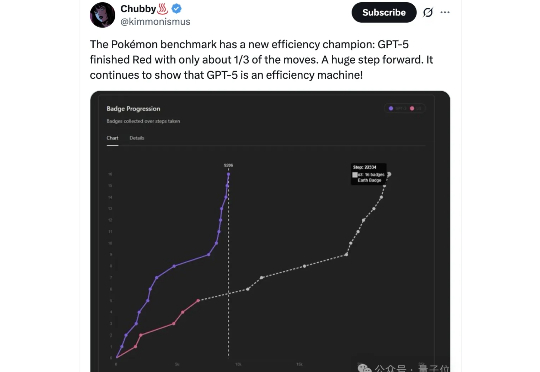
又是一场酣畅淋漓的战斗! 宝可梦主播GPT-5在直播间鏖战一小时,成功击败赤爷(Red),公屏瞬间刷满GG(Good Game)。
UCSD等推出Lmgame Bench标准框架,结合多款经典游戏,分模块测评模型的感知、记忆与推理表现。结果显示,不同模型在各游戏中表现迥异,凸显游戏作为AI评估工具的独特价值。