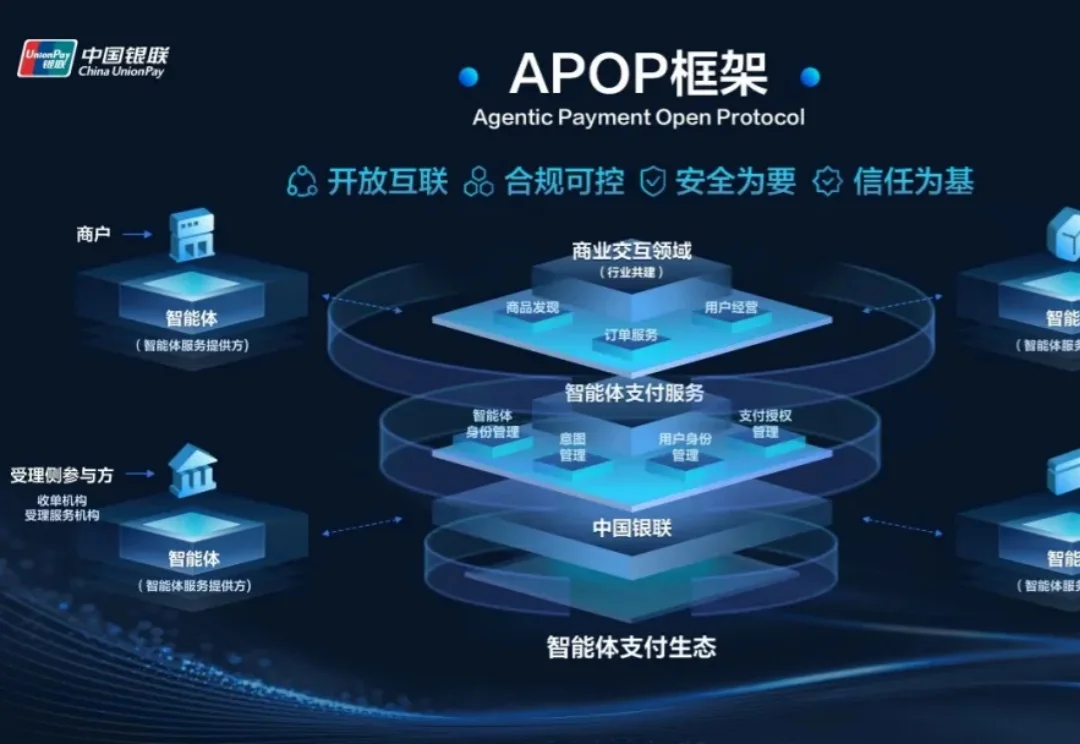
中国银联推出了智能体支付开放协议框架 APOP,重新定义AI时代的钱怎么花
中国银联推出了智能体支付开放协议框架 APOP,重新定义AI时代的钱怎么花当 “花钱” 这事儿开始外包给 AI,这个世界将发生什么变化?
来自主题: AI资讯
6737 点击 2026-07-29 13:49
 搜索
搜索
当 “花钱” 这事儿开始外包给 AI,这个世界将发生什么变化?
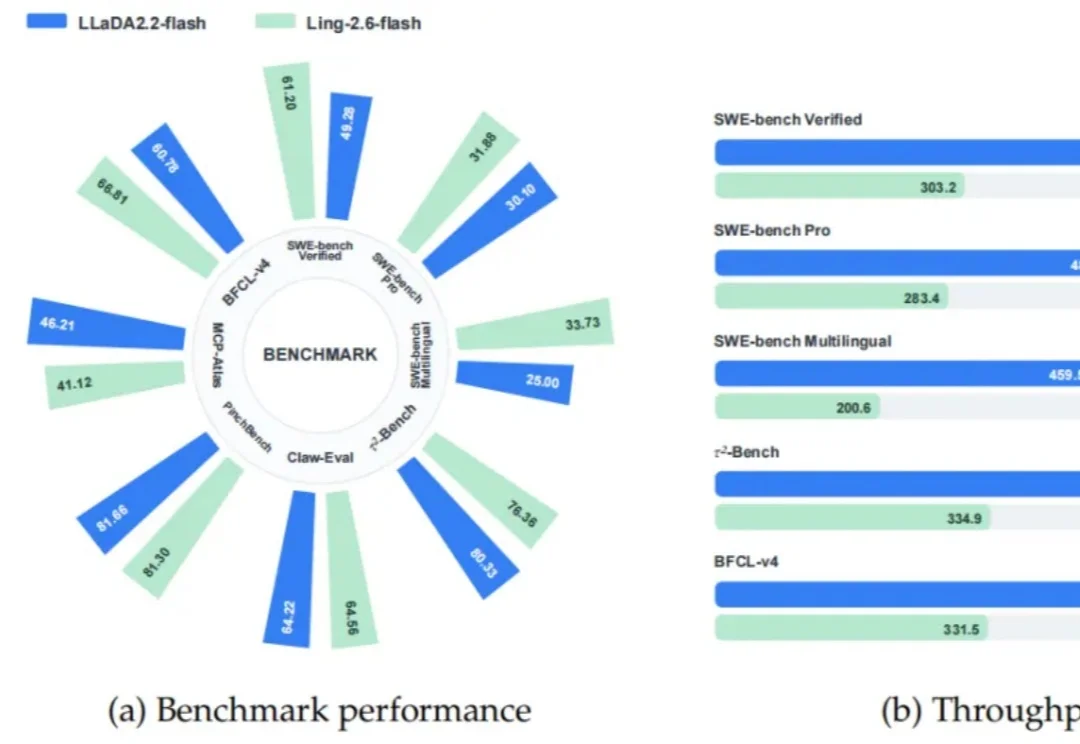
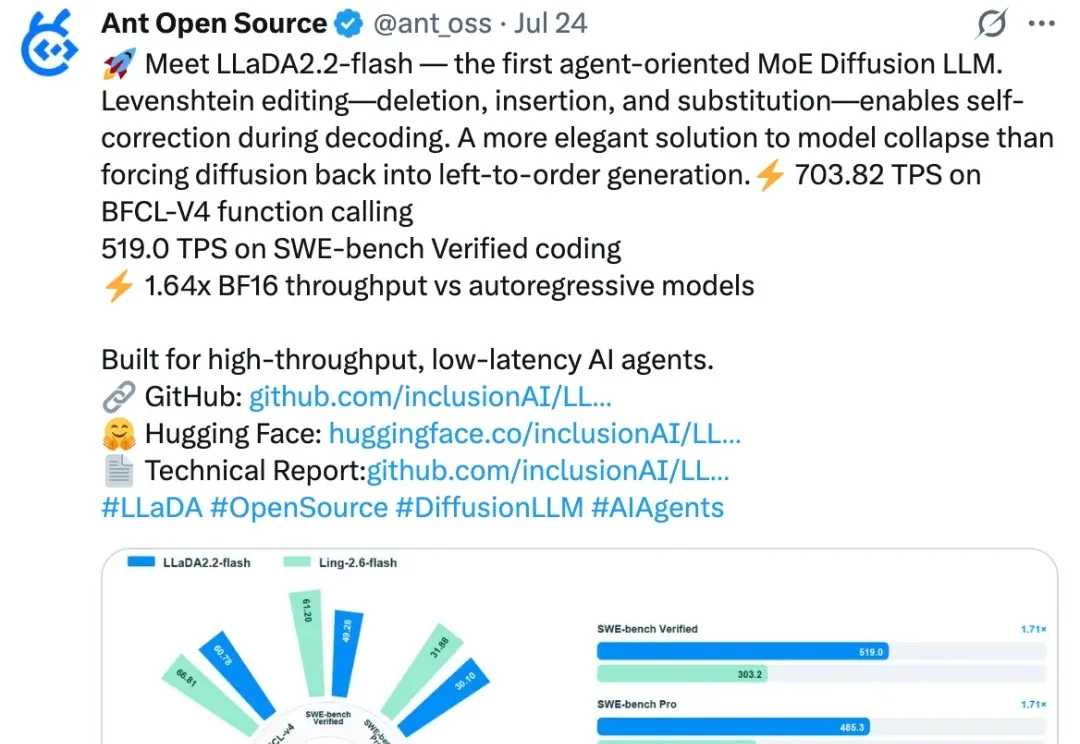
终于!Agent赛道,不再是自回归(AR)模型一家独大。
还记得「苦涩的教训」(The Bitter Lesson)吗?

出海这门生意,正在进入困难模式。

刚读了一篇 AI4AI 论文《AI4AI at Scale》,来自 XYZ Agentic Team。还是第一次听到这个 Lab。他们用 AI4AI 的方式做出了两个很强的搜索 agent,也公开了方法。借这篇 paper 讲讲 AI4AI 到底怎么工作,下面尽量少堆术语。

刚刚,北京市发布了一份特别重磅的政策文件。《北京市关于加快智能体引领发展的若干措施》文件不长,一共10条。但我把它从头到尾看完以后,我的第一反应是,这份政策真的有点太新了。Agentic AI、Harness Engineering、AI OS、FDE、OPC、Token经济、TaaS、AaaS、RaaS、Token工厂、AIP。

刚刚,阿里旗下的Qoder正式推出了Qoder Security,直击AI Coding的安全风险问题。在这个工具中,代码安全内生于 Qoder,贯穿从编码到提交的每一步。Qoder Security的发布,让Qoder成为国内首个交付「编码会话内三层安全护航 + 发现问题同会话修复」能力Agentic Coding产品。

就在今年的WAIC上,无问芯穹一口气亮出了「前店后厂一中心」,一整套完整的Agentic Infra战略布局:算力集散中心(一中心):Agentic Infra自主式基础设施平台;Token工厂(后厂):Agentic MaaS大模型服务平台;

发布之前,我在 X 上看到有人说,测 K3 的感觉就像在测 Fable 5。虽然离 Fable 5 还差一点点 🤏,但超过 Opus 4.8 和 GPT 5.5 基本没有问题。在前端能力,K3 的提升非常明显,我已经用它复刻了前段时间爆火的独立工作室 Abeto 推出的一款 3D 网页游戏 《 Messenger》(ps. 音乐手动配的,主角模型是 K3 自己判断、自主去游戏官网找的)

此芯科技,一家成立于2021年、专注自研高性能智能体CPU的公司,在上海举办了一场以「芯聚无限 智启新元」为主题的发布会。此次,他们正式发布了AGX Agentic Compute 智能体计算战略——一把打通芯片、整机和操作系统,构建覆盖端、边、云的全域算力底座。