
我用豆包代打腾讯游戏
我用豆包代打腾讯游戏究竟谁将率先点燃AI游戏这把火?
来自主题: AI资讯
8296 点击 2026-06-17 14:29
 搜索
搜索
究竟谁将率先点燃AI游戏这把火?
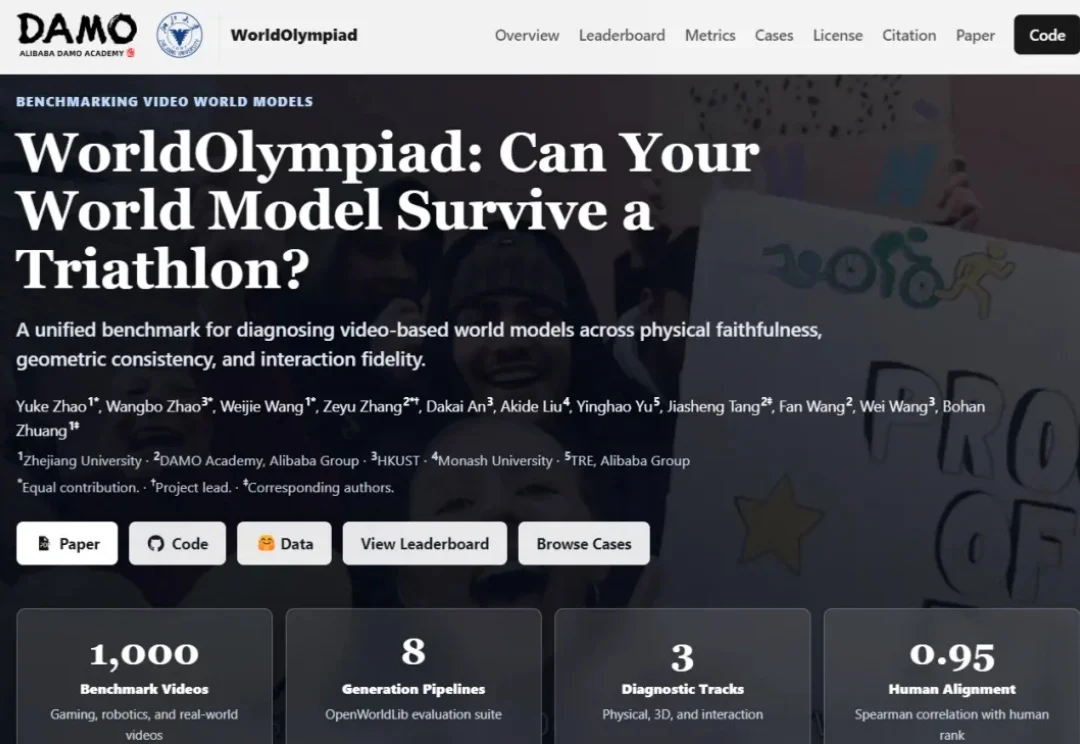
达摩院联合高校推出WorldOlympiad评测基准,跳出传统视频“唯画质”的评价逻辑,以物理真实性、三维几何一致性、长时序交互保真度三大维度,搭配游戏、机器人、通用实景三大场景,打造一套全方位的视频世界模型评测体系。
前几天 Fable 5 对海外用户关停的时候,智谱突然宣布向 GLM Coding Plan 全量用户开放了 GLM-5.2,并表示「前沿智能不应只属于少数人,也不应被少数规则随手收回。」

偷师、借道、换血、误删……折腾到最后,xAI成了给对手供电的人。

大家好,我是袋鼠帝。 6月,感觉又是模型爆发的月份。

卧槽,这事真的太抽象了。

AI 智件获悉,第三方数据基础设施公司「刻行时空」(下称“刻行”)已于今年1月完成新一轮融资,投资方包括穹彻智能、乐聚智能、线性资本。 刻行成立于2022年,是一家面向具身智能的第三方数据基础设施公司,聚焦时空多模态数据的生产、治理、评估与合规交付。

AI 真正的终局之战,可能根本不在 C 端。过去两年,我们见证了无数个打着“个人助理”旗号的 AI 应用争夺流量入口,像极了移动互联网早期的百团大战。
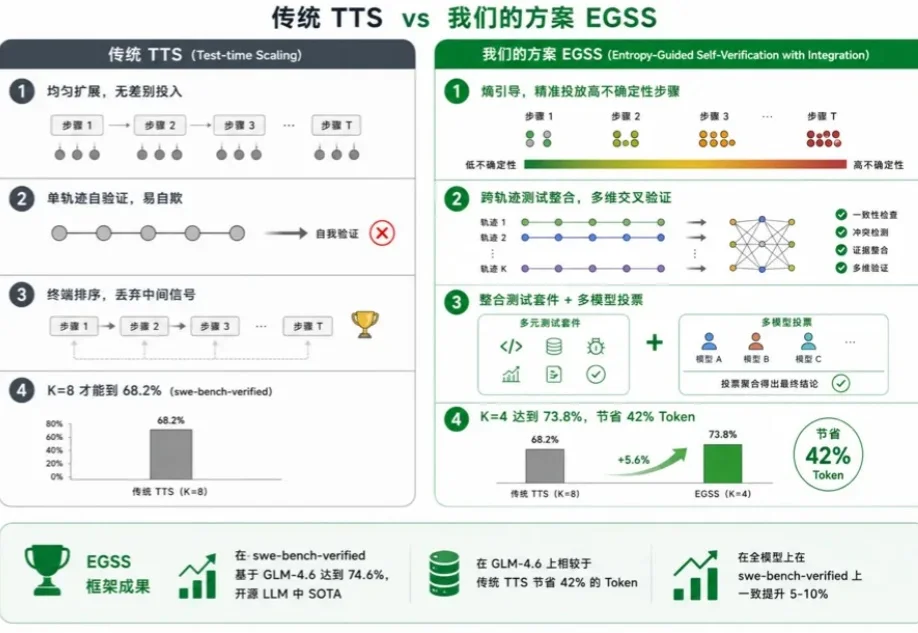
更聪明的计算远比更多的计算更有效。

Anthropic用40万次会话Claude Code实锤:能从 AI 身上榨出几倍产能的,不是代码力,是更懂行。