这个AI能救命!提前6个月发现胃癌病灶,突破医学影像认知,达摩院做成了
这个AI能救命!提前6个月发现胃癌病灶,突破医学影像认知,达摩院做成了AI新进展,救命的那种。现在,只需做一次体检时常规的CT检查,再用AI分析,就有可能在癌症还没有露出明显症状之前——比如提前半年——把它揪出来。
来自主题: AI资讯
7687 点击 2025-06-25 17:37
 搜索
搜索
AI新进展,救命的那种。现在,只需做一次体检时常规的CT检查,再用AI分析,就有可能在癌症还没有露出明显症状之前——比如提前半年——把它揪出来。

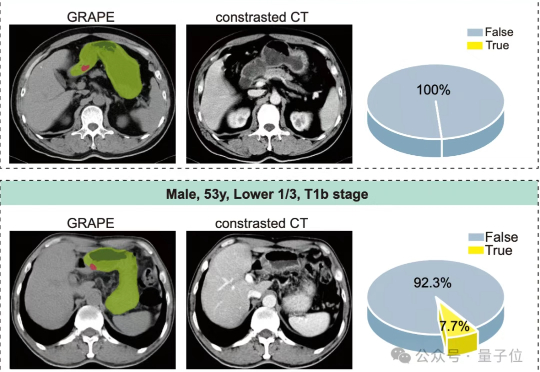
刚刚,浙江省肿瘤医院联合阿里巴巴达摩院召开发布会,发布全球首个胃癌影像筛查AI模型DAMO GRAPE,首次利用平扫CT影像识别早期胃癌病灶,并联合全国20个中心近10万人的大规模临床研究中大幅提升胃癌检出率。相关成果登上国际顶级期刊《自然·医学》(Nature Medicine)。
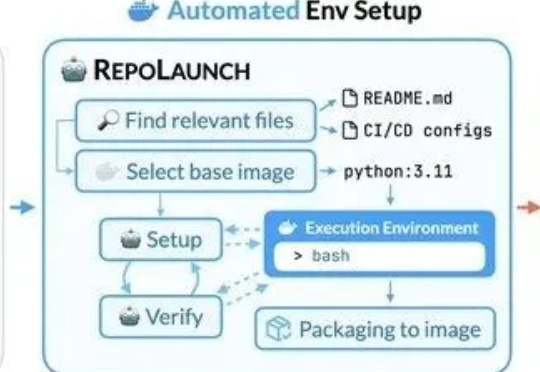
长期以来主流的代码修复评测基准SWE-bench面临数据过时、覆盖面窄、手动维护成本高等问题,严重制约了AI模型真实能力的展现。

当大多数大学生还在为毕业去向发愁时,年轻的王超已经带着他的端侧AI梦想,在国产算力赛道上跑出了加速度。这位杭州电子科技大学在读博士生创立的杭州旷维炬锐科技有限公司,不仅在2025年斩获千万级天使融资,更凭借“让AI模型在终端设备高效运行”的核心技术,成为国产AI生态构建的重要参与者。

就在刚刚,华为首次亮相了一套“虚”的技术—— 数字化风洞,一个在正式训推复杂AI模型之前,可以在电脑中“彩排”的虚拟环境平台

在旧金山AI工程师世博会上,Simon Willison用自创「骑自行车的鹈鹕」图像生成测试,幽默回顾过去半年LLM的飞速发展。亲测30多款AI模型,强调工具+推理成最强AI组合!

用AI来整理会议内容,已经是人类的常规操作。 不过,你猜怎么着?面对1000道多步骤音频推理题时,30款AI模型竟然几乎全军覆没,很多开源模型表现甚至接近瞎猜。
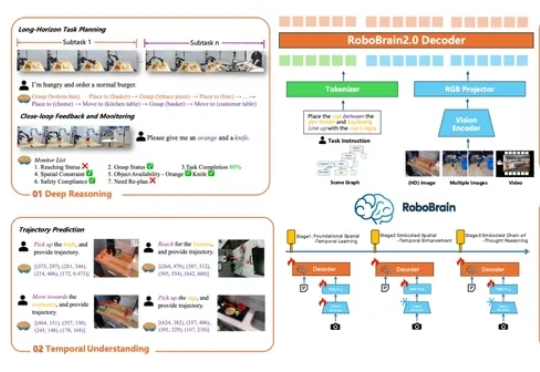
大模型的发展正在遭遇瓶颈。随着互联网文本数据被大规模消耗,基于数字世界训练的AI模型性能提升速度明显放缓。与此同时,物理世界中蕴藏着数字世界数百倍甚至千倍的多模态数据,这些数据远未被有效利用,成为AI发展的下一个重要方向。

AI模型用于工业异常检测,再次取得新SOTA!

科学家用AI重构《死海古卷》时间线,震撼圈内!最新研究显示,《但以理书》《传道书》部分古卷实际成书更早,甚至揭示了圣经作者线索。AI模型Enoch结合碳14定年与笔迹分析,首创AI定年方法,大幅超越传统古文字学。