
硅谷百亿美金押注「AI造AI」,清华系创业团队衔远科技反手把模型开源了!
硅谷百亿美金押注「AI造AI」,清华系创业团队衔远科技反手把模型开源了!新智元报道 2026年,AI行业最昂贵的新故事,已经不只是「训练一个更大的模型」。 资本开始直接押注:让AI参与制造下一代AI。 4月,AlphaGo核心缔造者David Silver创办的 Inef
来自主题: AI资讯
8429 点击 2026-08-01 13:33
 搜索
搜索
新智元报道 2026年,AI行业最昂贵的新故事,已经不只是「训练一个更大的模型」。 资本开始直接押注:让AI参与制造下一代AI。 4月,AlphaGo核心缔造者David Silver创办的 Inef
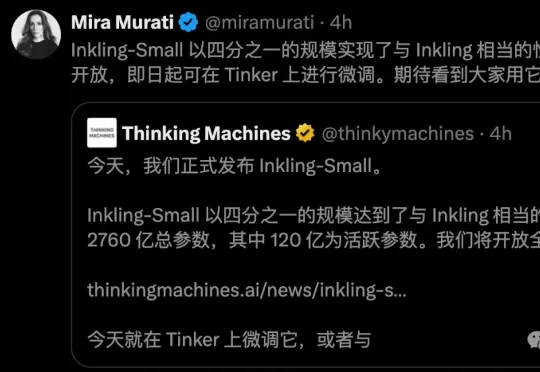
今天,Thinking Machines正式发布第二款重磅模型——Inkling-Small。276B总参数、12B激活参数,原生多模态,100万token上下文。半个月前,首个开源975B Inkling登场,曾在AI圈掀起了巨浪。

今天,全网都被这位25岁「AI先知」的故事刷屏了。 就在刚刚,华尔街上演了一场教科书级别的平仓。这场血雨腥风的主角,是被硅谷奉为「AI预言家」的Leopold Aschenbrenner,以及他那只439%逆天回报率的对冲基金——Situational Awareness(情境感知)。

硬氪获悉,Physical AI平台公司「昆腾动力(Quantum Dynamics)」近日完成超亿元种子轮融资,本轮由云启资本、商汤国香资本联合投资。资金将主要用于Physical AI核心技术研发、人才梯队建设及全球化市场拓展,加速其面向物理世界的智能系统从底层模型到场景化落地的全链路构建。多维资本参与项目孵化与团队组建。

本周,Fish Audio宣布完成5200万美元种子轮融资,由Coreline Ventures和Capital Today领投。

在生成式 AI、视频生成和各种数字营销工具铺天盖地时,硅谷最有影响力的物理 AI(Physical AI)独角兽 Applied Intuition 抛出了一个极其犀利的观点:未来 25 年,真正能重塑物理世界的 AI 公司,其规模和影响力很可能会远超今天主导数字世界的科技巨头。
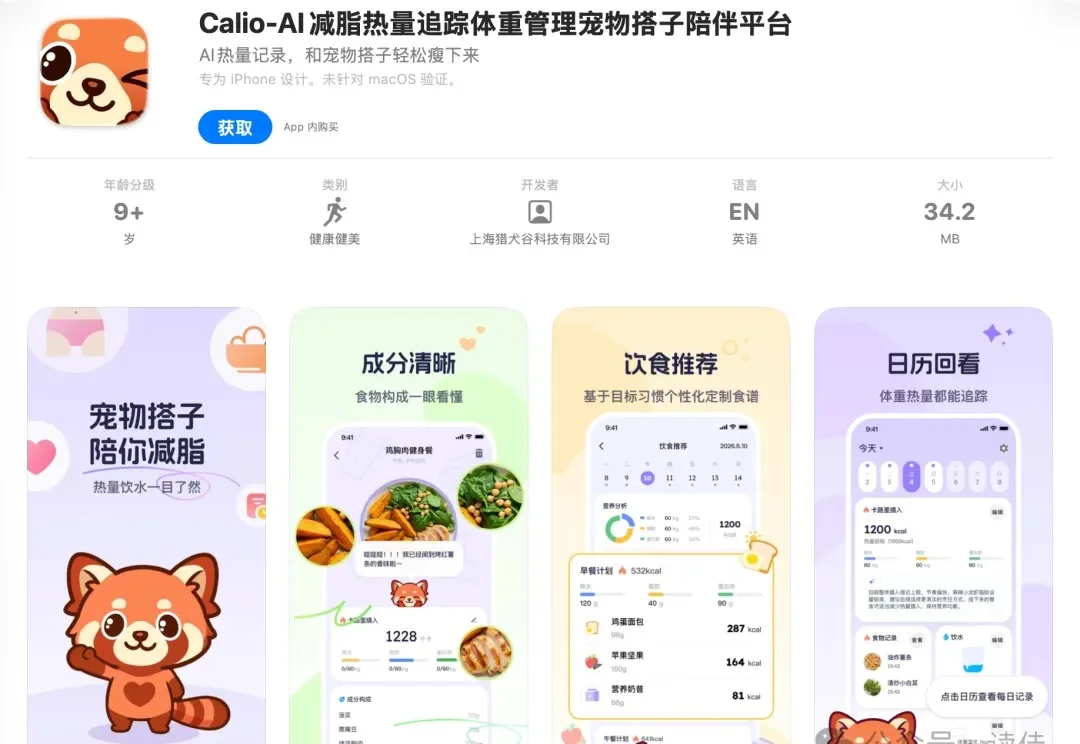
《读佳》获知,哈啰做了一个AI减脂APP“Calio”,产品定位轻量化日常健康减脂平台,核心面向想要温和管控体重、讨厌复杂操作的普通用户。

Personal Agent OS 公司「Tiiny AI」宣布完成数千万美元天使轮系列融资,由顺为资本、经纬创投、锦秋基金、云启资本、戈壁—阿里巴巴香港创业者基金、BV 百度风投、光源 L2F 基金联合投资。光源资本担任孵化方和独家财务顾问。
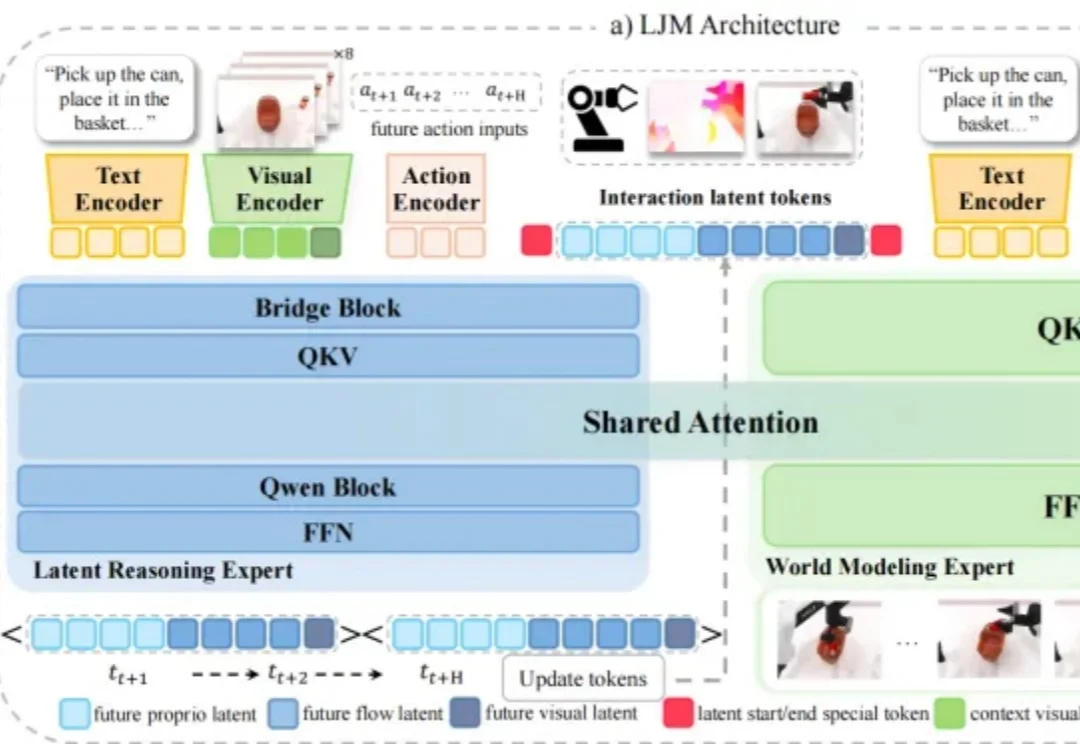
机器人实验室里,这样的画面总是反复出现:屏幕上模拟的机械臂正以完美轨迹移动,但真实世界的一边,玻璃杯还待在桌面上,甚至已被夹爪打翻。

近期,SemiAnalysis 创始人 Dylan Patel 先后做客红杉资本的《Training Data[1]》和 WisdomTree 的《The Next Big Thing[2]》。两期访谈从模型和芯片,一路延伸至内存、能源、数据中心与 AI 商业模式,并指向同一个变化:AI 竞赛的焦点,正从单纯比较模型能力,扩展到谁能以更低成本、更大规模,把模型能力稳定地交付出来。