
刚刚,Codex 首款硬件曝光
刚刚,Codex 首款硬件曝光当整个 AI 圈都在翘首以盼 Sam Altman 和前苹果首席设计官 Jony Ive 能联手掏出一部 AI 时代的 iPhone 时,OpenAI 今天却猝不及防地公布了一个键盘。
来自主题: AI资讯
10866 点击 2026-06-30 10:48
 搜索
搜索
当整个 AI 圈都在翘首以盼 Sam Altman 和前苹果首席设计官 Jony Ive 能联手掏出一部 AI 时代的 iPhone 时,OpenAI 今天却猝不及防地公布了一个键盘。

Z Potentials独家获悉,柔性具身智能公司深圳擎羽科技有限公司(以下简称:擎羽科技)已完成 Pre-A 轮融资。本轮融资由顺为资本、五源资本联合投资,高鹄资本担任独家财务顾问。这也是继德迅投资、东方富海等一线机构相继出手后,擎羽科技在半年内完成的第三轮融资。
Patronus AI 今天官方宣布公司完成由 Greenfield Partners 领投的 5000 万美元 B 轮融资,Lightspeed Venture Partners、Notable Capital、Datadog、三星、Gokul Rajaram、Factorial Capital 以及来自我们实验室和新实验室的众多人工智能领军人物也参与了本轮融资。

就在今天凌晨,哈佛博士Douglas Yao在X宣布,研发了一款针对阿尔茨海默病的新药PAC-832,引发了数百人的围观。这是世界上第一个选择性GalR1拮抗剂,创始人表示全程使用了机器人自动化技术和AI大模型。

今日,半导体研究机构SemiAnalysis爆料,AI大牛、阿里云前副总裁、LeptonAI创始人兼CEO贾扬清已离开英伟达。SemiAnalysis猜测,贾扬清离开的原因可能是其联合打造的AI超级计算云服务DGX Lepton失败了,未达到英伟达创始人、CEO黄仁勋预期的成功。

国内具身智能赛道再次迎来重要时刻。

什么是AI原生支付?随着全世界个体token的消耗量猛增,越来越多的大玩家和初创公司开始瞄准AI支付机制和基础设施的问题。

2026年6月17日,Nature 刊登了一项里程碑式的研究,来自海德堡大学医院的研究团队开发了一个名为MIRA(Medical Intelligence for Reasoning and Action) 的自主医疗AI智能体。
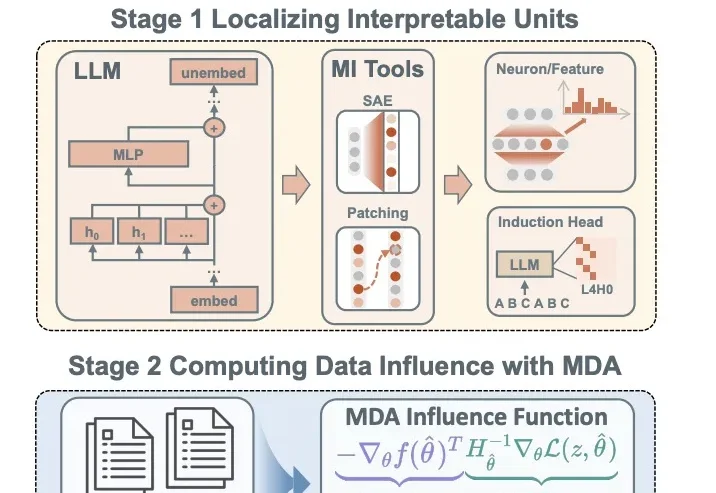
近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。
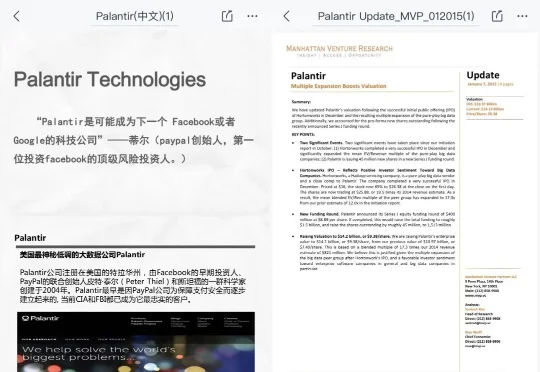
一直很奇怪为什么那么多人追崇Palantir这家公司。中国不会有Palantir,在美国它也是非常特殊的存在。这个公司不是近几年才火的,十年前投资行业追大数据概念的时候就已经很火了,当时同事还给我传过它的BP资料,当然我们国企不会去跟进这种海外项目。这十年间,国内拿Palantir作为对标、讲故事的大数据公司一抓一大把,但跟它做一样事情的大数据公司一个都没有。