
Sora死了4个月后,谷歌终于出手了
Sora死了4个月后,谷歌终于出手了故事是这样的。 今年3月24号,OpenAI宣布关停Sora。
来自主题: AI资讯
8971 点击 2026-07-02 11:05
 搜索
搜索
故事是这样的。 今年3月24号,OpenAI宣布关停Sora。
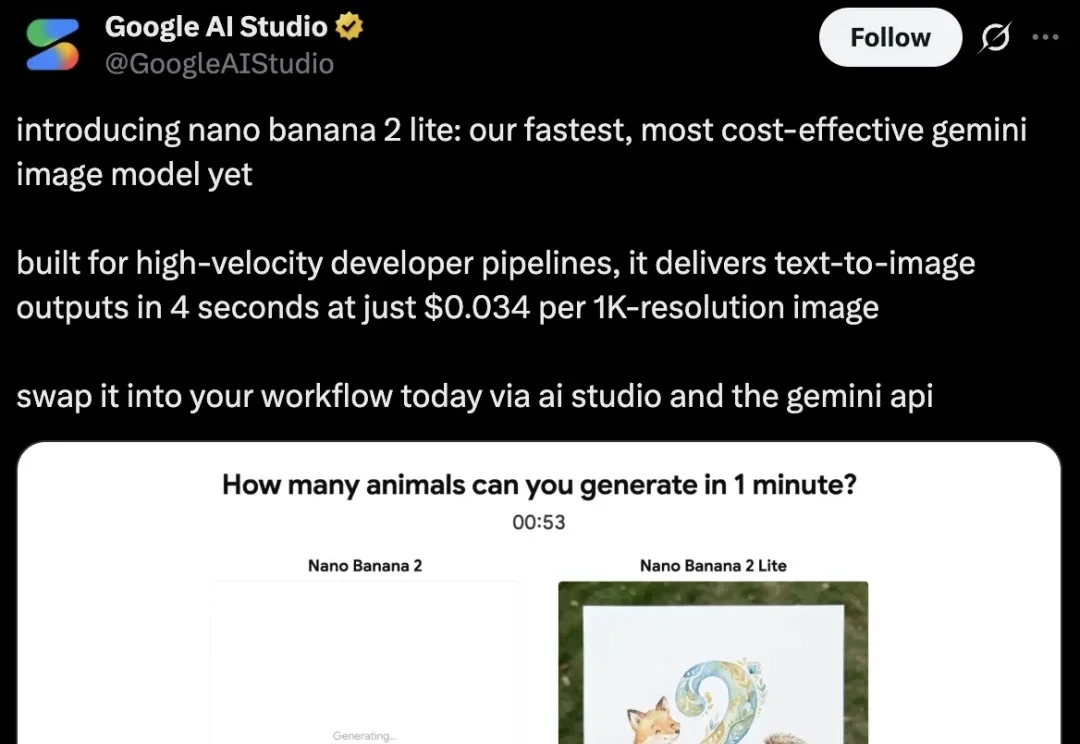
虽然Coding还是一坨,但谷歌搞「多模态」确实有两把刷子。

0 美元你能得到什么——Gemini 2.5 Flash 和 Pro 均可用,每分钟 1M tokens,原生支持文本、图像、音频、视频多模态输入 ,几秒钟生成 API Key,即开即用

好好好,起大早赶晚集的谷歌,这次又拿出了新东西—— Computer use,就是那个电脑操作能力,这回直接被内置进Gemini 3.5 Flash:
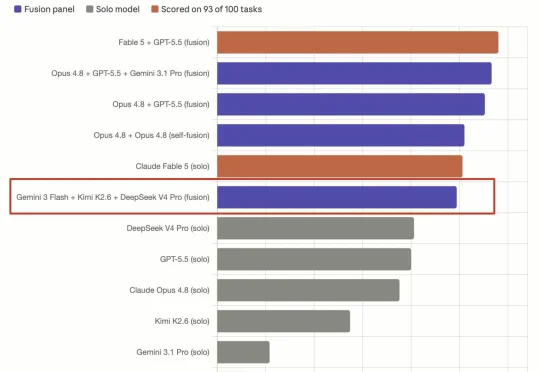
最新测试显示,模型抱团后实力明显升级:Opus 4.8+GPT-5.5>Fable 5;Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash=Fable 5。能力追上了,开销还减半。根据官方定价,相比Fable 5,Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash这套平价阵容,成本降幅接近80%。

近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。
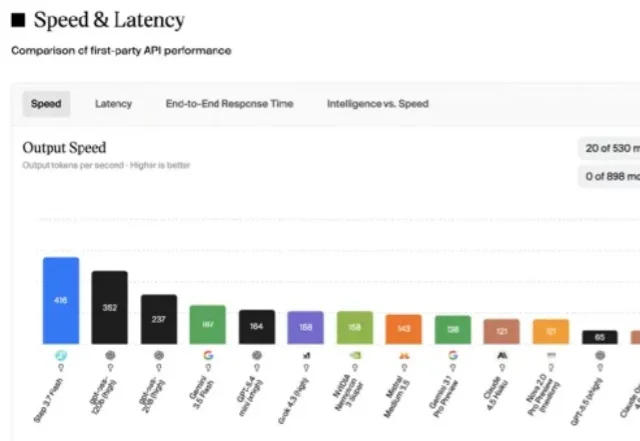
OpenRouter Trending榜单冷不丁窜出一匹国产黑马,热度暴涨稳居全球第二。
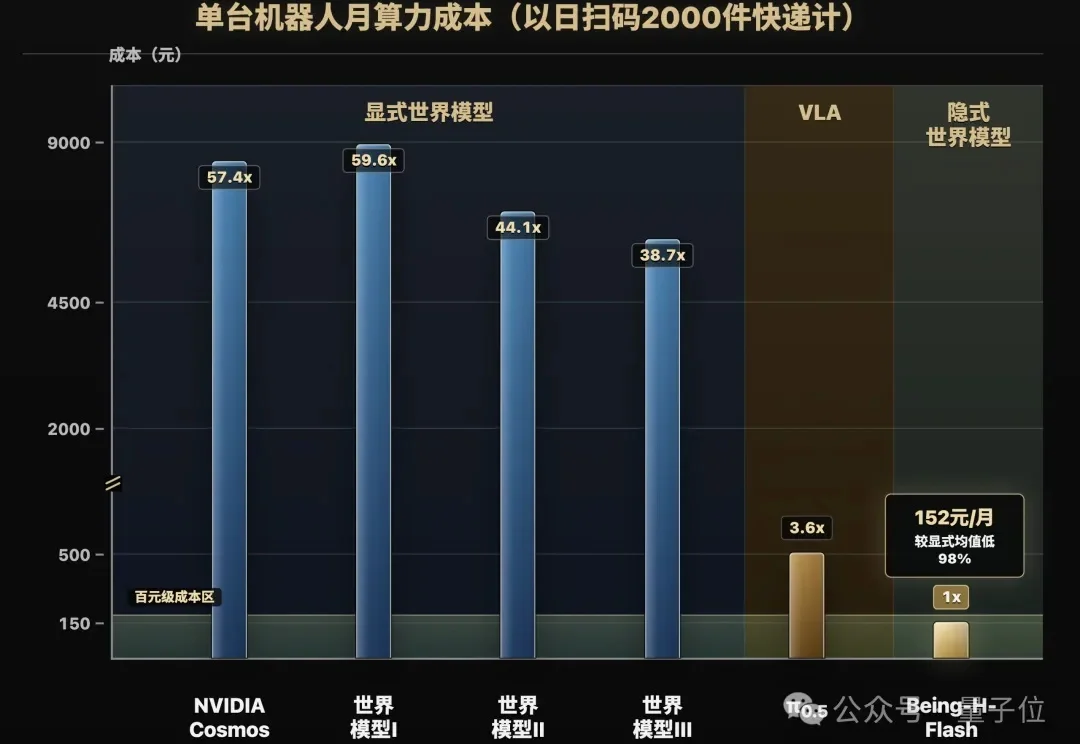
真没想到啊!物理AI的账单,有一天竟然能和大模型一个价。

很难想象,企业使用 AI 的成本已经远远超过了雇佣员工的成本。

1492 年,哥伦布驶向大西洋深处。远洋航行当然需要速度,但真正决定船队能否抵达彼岸的,是淡水、食物、船体、桅杆和帆索能否撑过漫长风暴。改写跨洋贸易的,正是这种并不浪漫的工程逻辑。 后来,荷兰人设计出