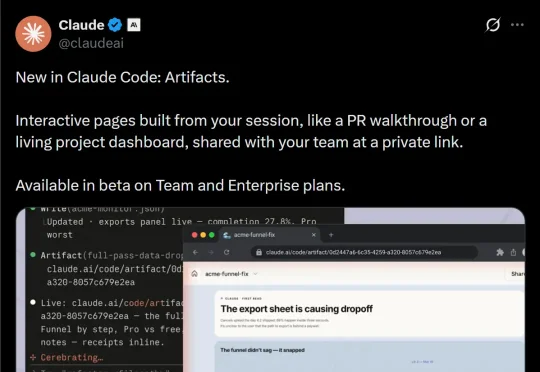
Claude Code史诗级更新!Artifacts让终端里直接长出网页
Claude Code史诗级更新!Artifacts让终端里直接长出网页终端党狂喜!Anthropic甩出Claude Code重磅更新:工作成果一键化身实时交互网页。无需部署、隐私安全,不管是PR演示还是数据可视化,都能从终端长出。速来解锁,让你的代码工作流直接起飞!
来自主题: AI资讯
8281 点击 2026-06-19 21:17
 搜索
搜索
终端党狂喜!Anthropic甩出Claude Code重磅更新:工作成果一键化身实时交互网页。无需部署、隐私安全,不管是PR演示还是数据可视化,都能从终端长出。速来解锁,让你的代码工作流直接起飞!

你坐在电脑前干活,旁边有个家伙一声不吭盯着你。你点哪它看哪,你填什么它记什么,等你做完,它说一句:下次这活我来。这就是 Codex 刚刚发布的重磅功能,叫 Record & Replay。
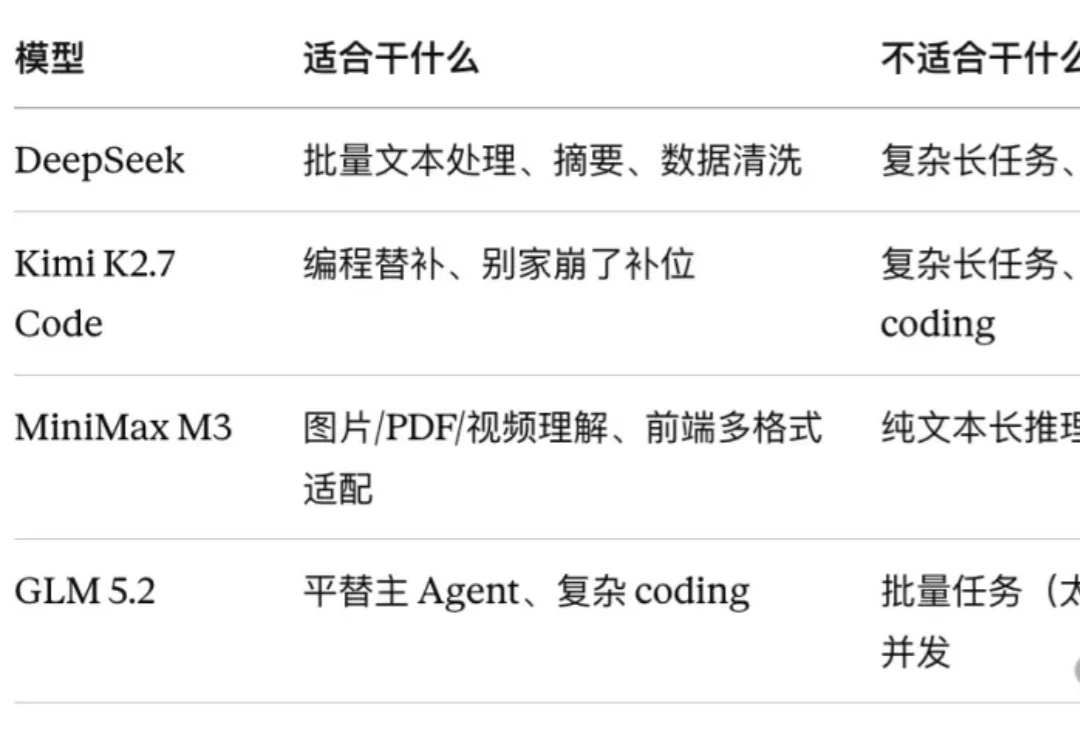
最近,Kimi 2.7 Code 和 GLM 5.2 接连发布,一周双发,国产模型又崛起了。

Anthropic用40万次会话Claude Code实锤:能从 AI 身上榨出几倍产能的,不是代码力,是更懂行。
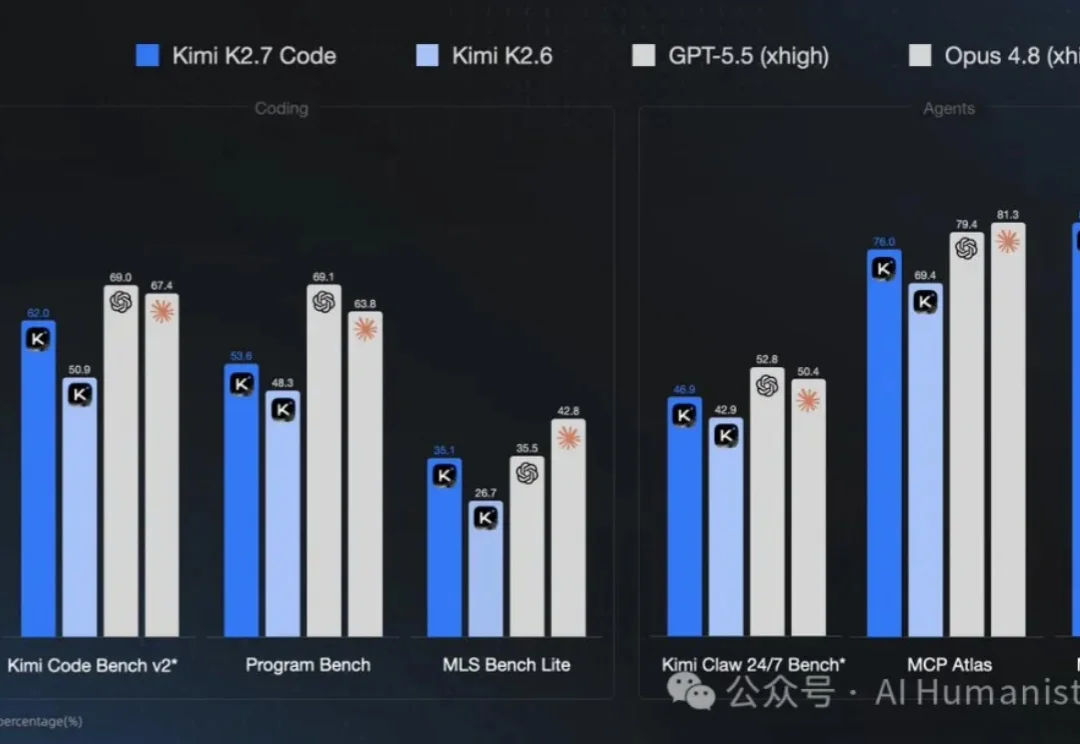
昨天 Kimi K2.7 Code 高速版 上线了,我上手试了下,最大的感受就一个字:快。

Cursor曾养活Anthropic半条命,如今被Claude Code逼到梭哈马斯克。
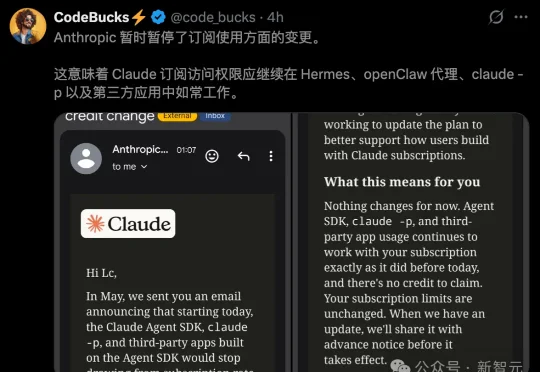
终于,等来了好消息!就在刚刚,Anthropic正式官宣——撤回禁止以编程式调用Claude Code订阅额度的「禁令」。从此,接入Claude的claude -p、OpenClaw、Hermes等第三方应用,可照常从「订阅额度」里扣量了。
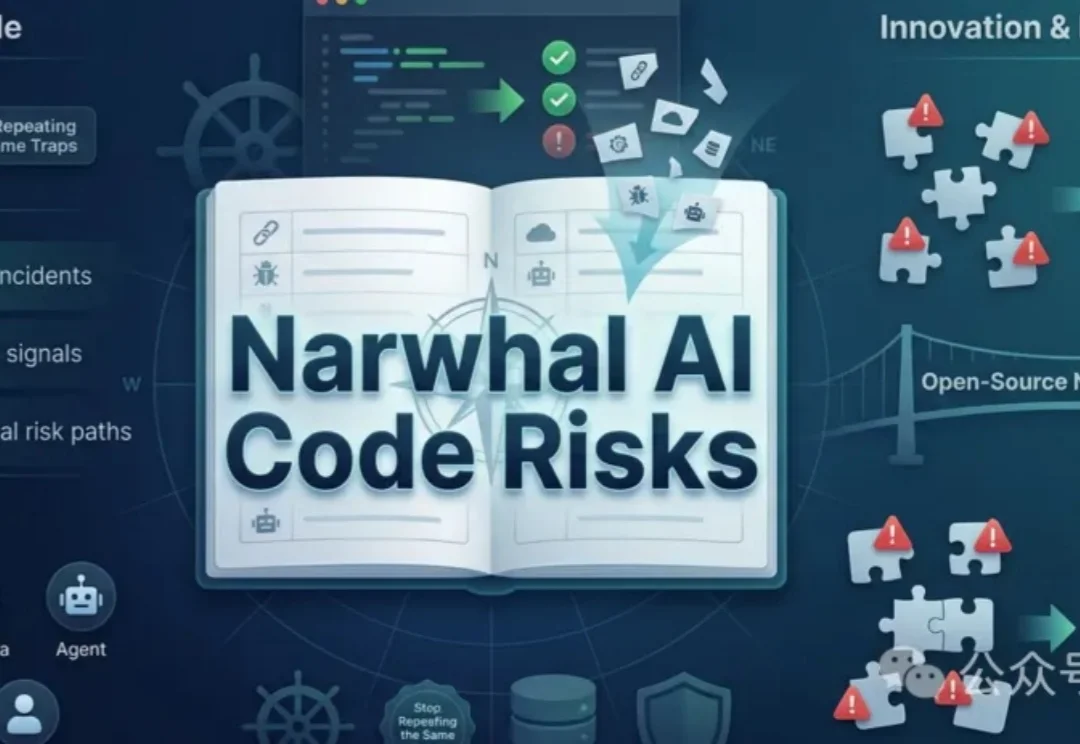
AI写代码的风险隐藏在看似正确的代码中,可能引发数据泄露或资产损失。Narwhal AI Code Risks开源项目整理了真实案例、早期信号和典型风险路径,帮助开发者提前识别隐患,避免重蹈覆辙。
Anthropic 最近推出了 Claude Design,是我除了编程之外用得最多的 Agent,也推荐过很多次。效果真的好:你用一句话描述想要的 App,它直接给你生成一个可交互的原型,点哪哪都有反应,不仔细看还以为在操作真实的 App。
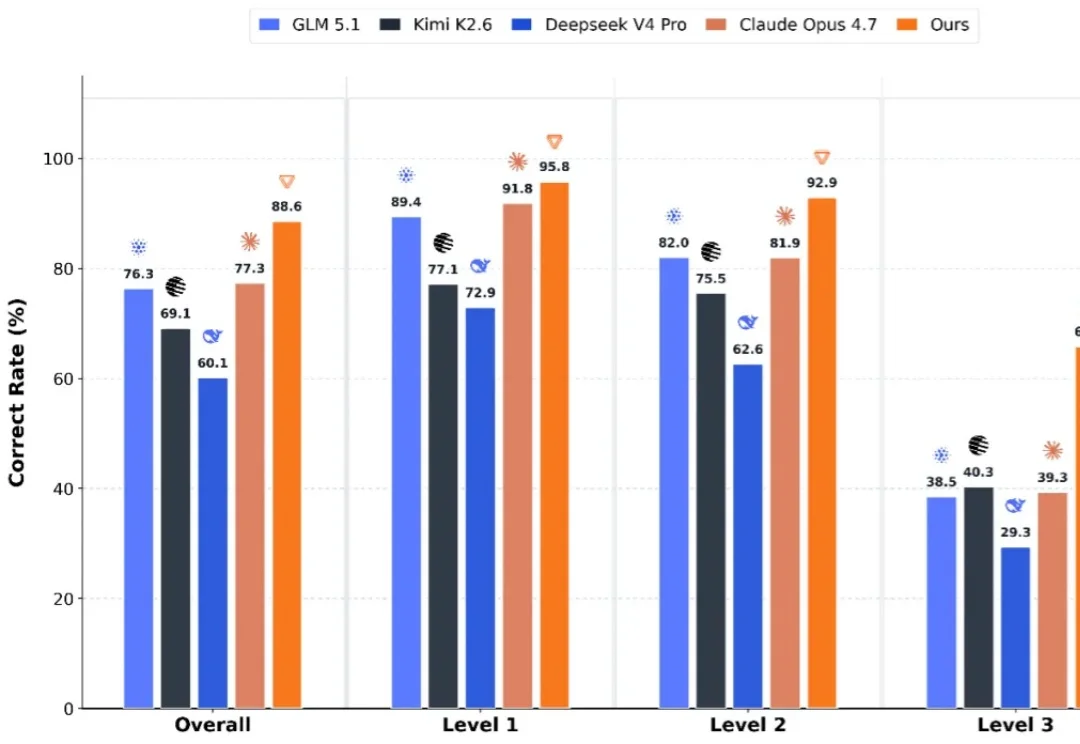
国产算力生态的难题,从此有了 AI 解。