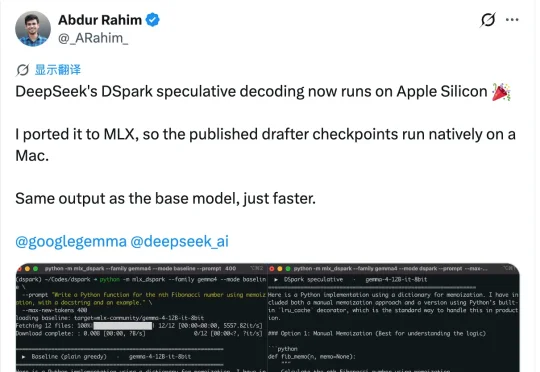
DeepSeek新技术移植苹果芯片!Mac本地大模型加速60%
DeepSeek新技术移植苹果芯片!Mac本地大模型加速60%DSpark刚开源一周,就被搬进了苹果电脑。移植版本叫mlx-dspark,跑的是Gemma-4 12B和Qwen3-4B这两个模型。装上之后,这两个模型在Mac上的生成速度分别提了1.6倍和1.4倍。
来自主题: AI资讯
9479 点击 2026-07-03 21:58
 搜索
搜索
DSpark刚开源一周,就被搬进了苹果电脑。移植版本叫mlx-dspark,跑的是Gemma-4 12B和Qwen3-4B这两个模型。装上之后,这两个模型在Mac上的生成速度分别提了1.6倍和1.4倍。

2026 年 6 月,大模型行业正在经历一场前所未有的「开源海啸」:英伟达放出了 550B 参数的混合架构模型,谷歌送出多模态的 Gemma 新版本,智谱用最宽松的协议全量开源了自家旗舰模型。

最近,我们都在关注旗舰级大模型的进步,其实本地运行的 AI 模型也迎来了重要的分水岭。

Google DeepMind在6月份对外分享了DiffusionGemma的技术报告,明确指向了一条与现有主流完全不同的演进道路。当大家都在绞尽脑汁让大模型逐词吐字的速度变快时,谷歌干脆把生成顺序改了。
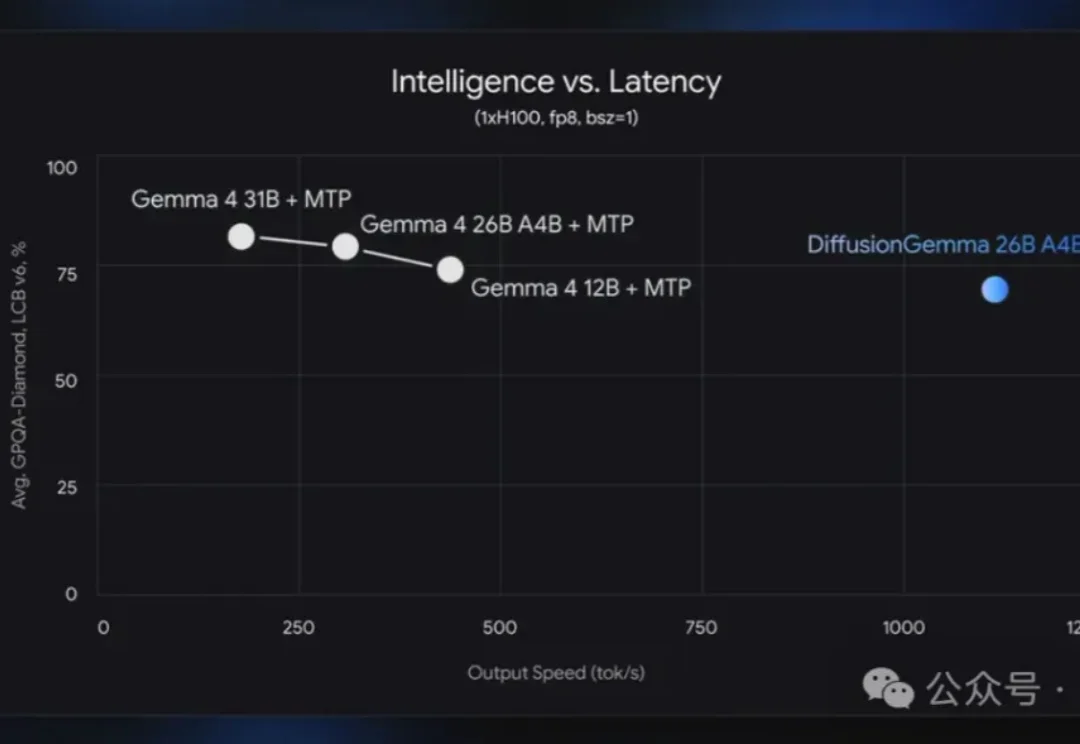
就在刚刚,谷歌闷头干了件大事:把生成图片的扩散模型,拿来写文字了,而且一出手就是4倍加速。 新模型名为DiffusionGemma,它直接抛弃了传统自回归那套“逐Token生成”的打字机模式,而是像“印刷机”一样工作——

今天一早,谷歌又发新模型了!

过去一年,开源模型的发布节奏已经快到让人麻木。每次发布,伴随的永远是一组跑分、一张能力雷达图,以及几个“超越某某”的结论。

刚刚,谷歌扔出Gemma 4 12B大杀器!16G轻薄本就能全离线流畅跑通,性能直逼26B巨兽,全体开发者惊呼太震撼了,平民级本地AI封神之作降临。硬核实测速来看!

刚刚,谷歌DeepMind发布了Gemma 4 12B。一句话概括这个模型的定位:把原本需要高端服务器才能跑的多模态智能,装进你的笔记本电脑里。它填补的是Gemma家族里一个关键空缺:比边缘端的E4B更强,比26B混合专家模型(MoE)更轻。而且在整个Gemma 4系列里,它是第一个支持原生音频输入的中等规模模型。
过去一段时间,很多人对大模型都有一个明显感受:token 总是不够用。