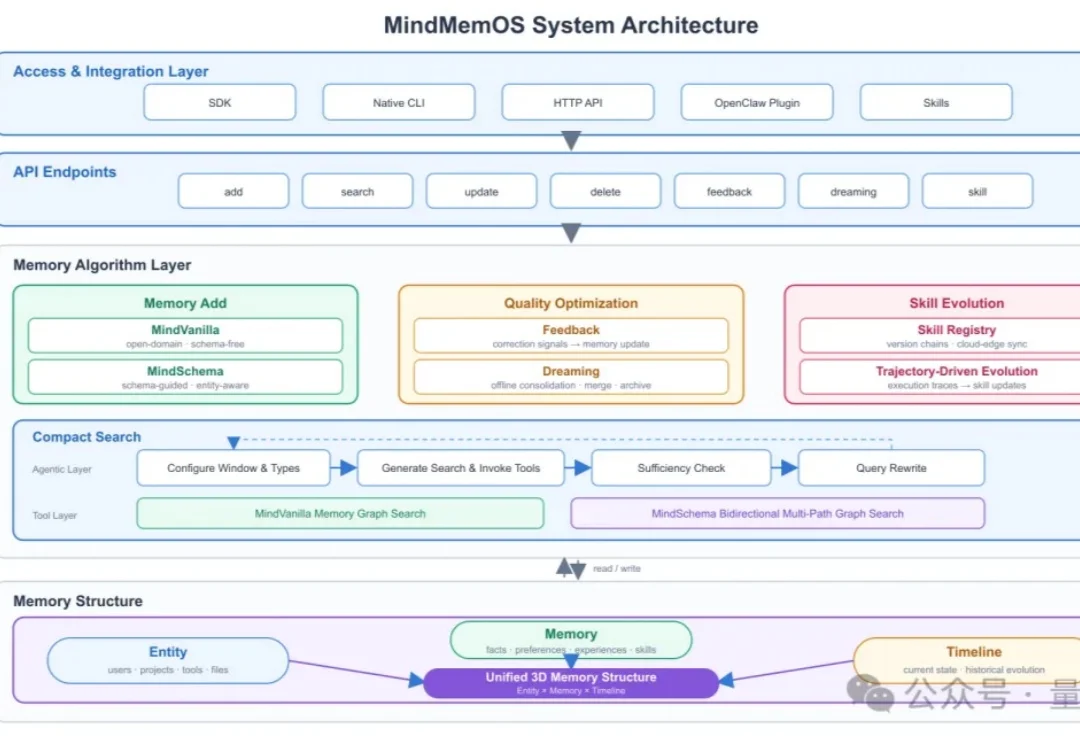
Agent终于不再「用完即忘」:华为诺亚开源MindMemOS,让记忆和Skill一起进化
Agent终于不再「用完即忘」:华为诺亚开源MindMemOS,让记忆和Skill一起进化Agent的能力越来越强,但使用体验仍有一个尴尬之处: 每换一个Agent甚至换一个session,就像换了一个完全不了解你的新员工。
来自主题: AI技术研报
7060 点击 2026-08-03 10:58
 搜索
搜索
Agent的能力越来越强,但使用体验仍有一个尴尬之处: 每换一个Agent甚至换一个session,就像换了一个完全不了解你的新员工。

一个80亿参数的大模型,一口气吞下15万亿token的训练数据,堆到硬盘上差不多7TB。可它真正「背」得下来的,少得可怜:每个参数只装得下3.6 bit。一个英文字母8 bit,连半个都填不满。
你有没有想过,写代码这件事的对象正在悄悄换人?上周一晚上,我在旧金山Market Street上WorkOS的办公室里待了将近两个小时,看了二十几个现场demo。进门之前我以为这只是一场普通的创业展示夜,但看完之后我意识到,这群人在展示的根本不是产品,而是他们对"写代码、用代码、读代码"这件事本身的理解,已经发生了多深的变化。
记忆张量完成新一轮融资后,创始人熊飞宇反复向我们强调一件事,他不希望外界把记忆张量只理解成一家“做记忆”的公司。这轮亿元的 pre-A 融资,据记忆张量披露,参与方包括华为哈勃、荣耀战投、商汤国香、深创投和和玉资本。公开资料里,华为哈勃长期以硬科技和半导体产业链为主要布局方向

逛过WAIC具身智能展区的人,多半有同一个疑问: 都2026年了,机器人干活,怎么还是慢吞吞的?

好久不见,汇报一下近况。 这两个月没闲着,推掉了大部分事情,全力在做自己非常喜欢的新产品——Chat Memo 的 Agent 端。(目前小规模内测,公开内测等发布文章)
7月20日,AI记忆科技公司红熊AI宣布完成数亿元人民币A+轮融资,投后估值近30亿元。本轮由浙江九纬私募基金、嘉兴彰元创业投资与老股东格睿丰联合投资。 这是红熊AI成立以来完成的第6轮融资。过去15个月,公司估值从2025年Pre-A轮的5亿元,到2026年4月A轮超过15亿元,再到此次接近30亿元。

在行业陷入“刷榜”怪圈、产品功能同质化严重的今天,一家来自杭州的AI眼镜公司在WAIC大会上给出了不一样的答案:李未可科技正式发布了一款拥有“记忆”的AI眼镜——X-AI记忆眼镜,在这款产品背后,是基于WakeeMemory OS实现的“AI记忆能力体系”。

千寻智能的展台上,则来了两位画风完全不同的主角:一位是通体黑灰、看起来不苟言笑的 Moz1,埋头干活;另一位是首次公开亮相的 Moz2,奶杏色机身配上粉色小围脖「OOTD」,忙着向观众打招呼、举手比心,靠卖萌吸引了不少镜头。

昨天刚完成2亿美元Pre-IPO轮融资,逐际动力没有急着讲资本故事,而是立马甩出一段全尺寸人形机器人Oli全自主做家务的视频: