
这家六小龙上新全家桶,Agent接管终端关键一战!老黄预言时代来了
这家六小龙上新全家桶,Agent接管终端关键一战!老黄预言时代来了AI岂能只活在云端?刚刚,阶跃星辰上新来Step Edge 端侧模型全家桶!这次,AI能听懂语音、看懂屏幕,直接补齐了Agent本地执行的关键拼图。「端云协同」发力,你的手机与车机即将被彻底重构!
来自主题: AI资讯
9768 点击 2026-07-13 09:45
 搜索
搜索
AI岂能只活在云端?刚刚,阶跃星辰上新来Step Edge 端侧模型全家桶!这次,AI能听懂语音、看懂屏幕,直接补齐了Agent本地执行的关键拼图。「端云协同」发力,你的手机与车机即将被彻底重构!
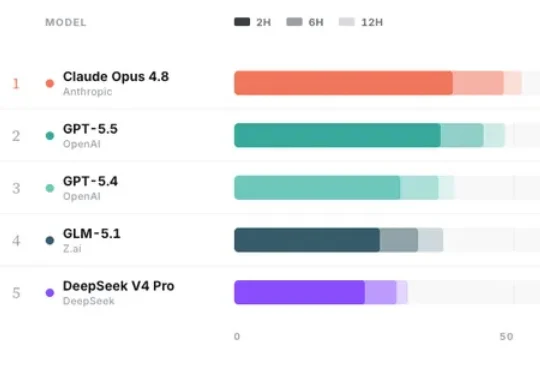
7月2日,字节 Seed 发布了一个 Agent评测项目 EdgeBench。看起来又是一个 benchmark,但它问了一个其他榜单不问的问题。EdgeBench 的切口就是把盲区里的东西放进评测,解答一个问题:把Agent扔进一个陌生环境,12小时后,你能变强多少?
2023 年大模型刚火的时候,浏览器被认为是 AI 时代最值得抢的入口,用AI颠覆Chrome是大家都能看到的百亿创业项目。实在是这个入口太大了。全球互联网用户已经是 60 亿量级,Chrome 一个产品就是三十亿级用户;Safari 靠 iPhone、iPad 和 Mac 占住十亿级设备入口,Edge 背后是 Windows 和微软账号体系。

6 月 23 日,腾讯云发布全新边缘 Web 与 AI Agent 托管平台 Tencent Cloud EdgeOne Makers(以下简称Makers),进一步强化面向Agent时代的 AI 全链路布局。

谷歌今天发布了一个叫 Open Knowledge Format(OKF)的开放规范。

硬氪获悉,具身智能世界模型公司「千诀科技」日前完成数亿元A轮融资,本轮由京铭资本领投,山东新动能、山东财金资本、元禾厚望、芯能创投、南创投、英诺天使基金、尚势资本、仁爱集团、玄素投资等机构共同投资,投资方阵容汇集了国家队、产业方、市场化基金及家族办公室。Maple Pledge枫承资本长期出任私募股权融资顾问。

Z Potentials独家获悉,清华系具身智能公司灵御智能宣布完成天使+轮近亿元人民币融资。本轮融资距离上次融资仅有两个月,由福田资本领投,力合创投、金沙江联合资本、复利多、楹辉创投、华仓资本跟投,老股东英诺基金、天鹰资本持续加注。Maple Pledge枫承资本长期出任公司私募股权融资顾问。
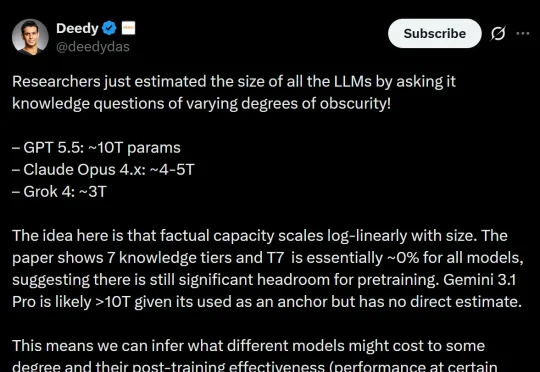
五一假期前,AI社区被一篇「GPT-5.5拥有近10万亿参数」的论文刷屏,今天这项研究就被研究者打假了!研究者表示,修正论文中的各种问题后,GPT-5.5的参数很可能约为1.5T。
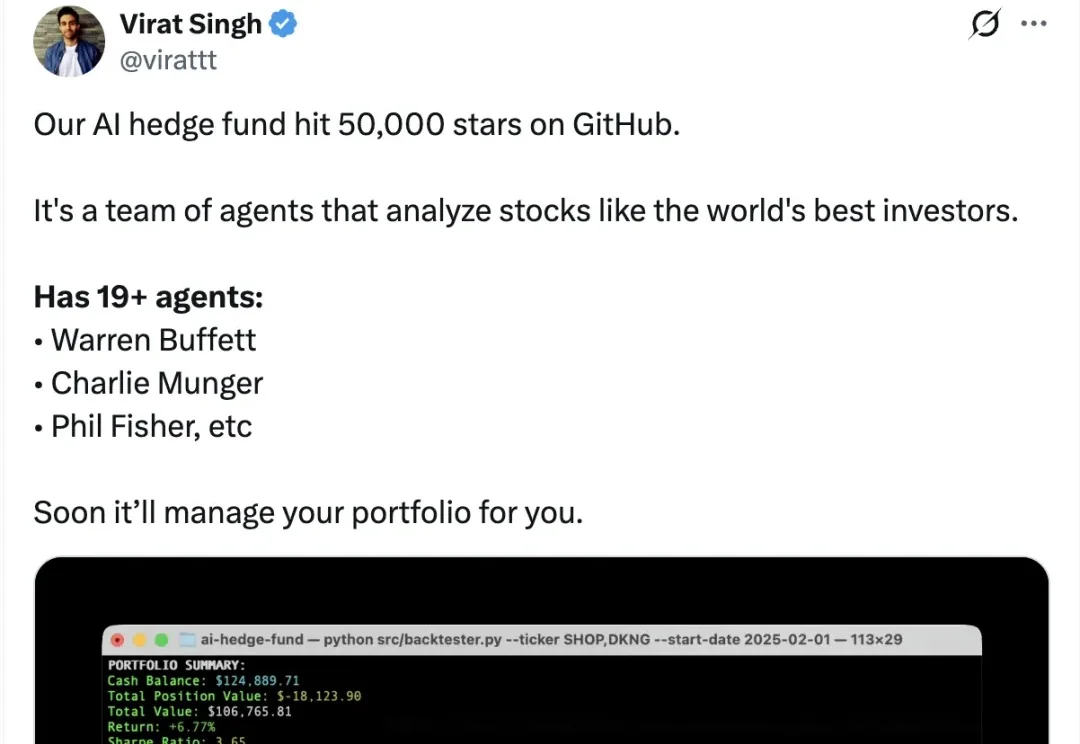
一不小心,查理芒格和巴菲特就被炼化,个个加入投资Agent军团,人人可用了。

一家叫 Rallies Arena 的团队,6 个月前干了一件事:给 6 个主流大模型各发了 10 万美元,让它们在真实股票市场上自己做研究、自己下单、自己管仓位。