谷歌Genie 3暴击游戏公司市值!GTA开发商缩水10%,游戏引擎Unity暴跌21%
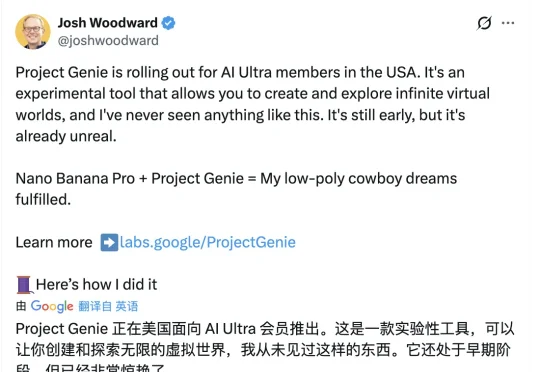
谷歌Genie 3暴击游戏公司市值!GTA开发商缩水10%,游戏引擎Unity暴跌21%谷歌正式开放世界模型Genie 3的实验性研究原型Project Genie。一夜间暴打了游戏公司市值。《GTA》开发商Take-Two Interactive缩水10%,在线游戏平台Roblox 下跌了超过12%,最惨的是游戏引擎制造商Unity下跌了21%。
来自主题: AI资讯
10453 点击 2026-01-31 11:06