
AMD新论文颠覆认知:FP4训练不稳定,原因不是随机性不足
AMD新论文颠覆认知:FP4训练不稳定,原因不是随机性不足众所周知,大模型训练成本极高。
来自主题: AI技术研报
6584 点击 2026-05-27 16:10
 搜索
搜索
众所周知,大模型训练成本极高。
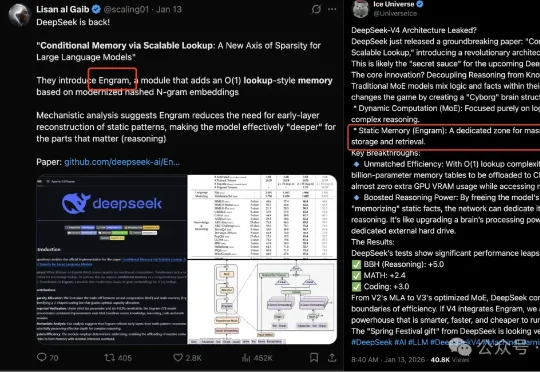
DeepSeekV4的技术报告里有mHC,有CSA,有HCA,有Muon,有FP4……唯独没有Engram。Engram在今年1月由DeepSeek和北大联合开源,主要研究大模型的记忆与效率问题。
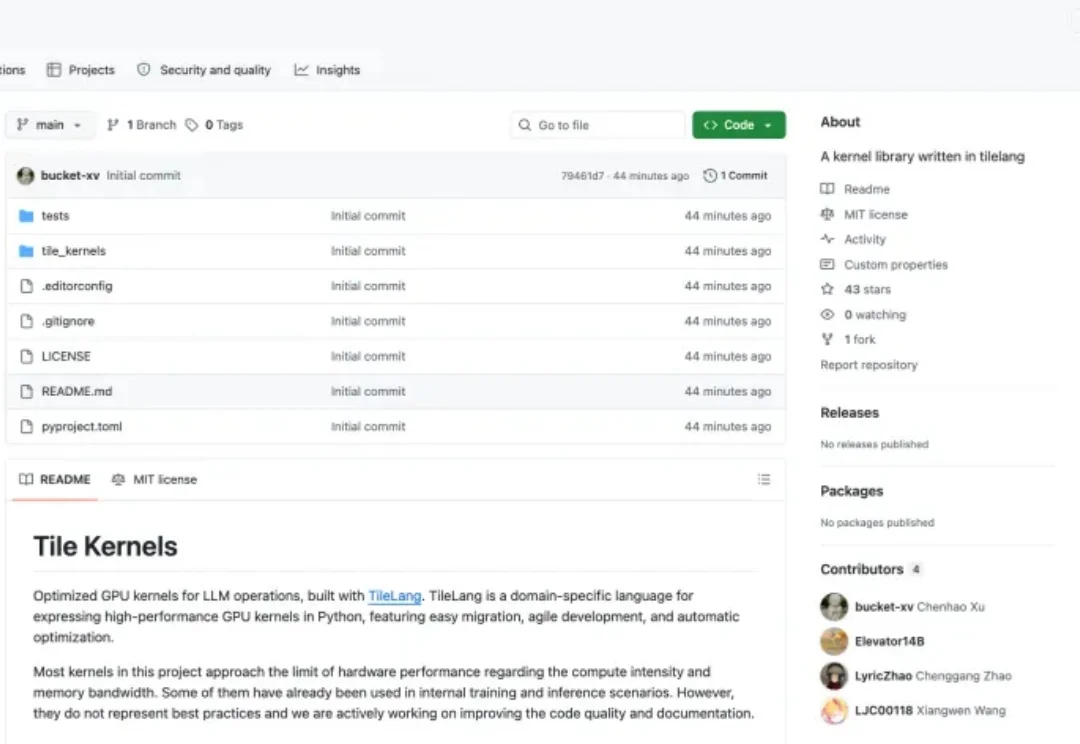
就在刚刚,DeepSeek 的 GitHub 开始了频繁更新,上线开源了一个新的代码库 Tile Kernels,同时并对 DeepEP 代码库进行了更新,上线了 DeepEP V2。距离上次 DeepSeek 悄悄更新 Mega MoE、FP4 Indexer 还不到一周。

当强化学习后训练的大规模 rollout 已经被证明能够提升图像生成模型的偏好对齐能力,推理负担就成了制约训练速度的核心瓶颈。来自 NVIDIA、港大和 MIT 的团队提出的 Sol-RL,通过「FP4 先探索、BF16 再训练」的后训练框架,将达到等效 reward 水平的收敛速度最高提升到 4.64x,在训练速度与对齐效果之间给出了一条更具工程可行性的解法。

英伟达在开源模型上玩的很激进: “最高效的开放模型家族”Nemotron 3,混合Mamba-Transformer MoE架构、NVFP4低精度训练全用上。而且开放得很彻底:

英伟达面向个人的AI超算DGX Spark已上市!128GB统一内存(常规系统内存+GPU显存),加上允许将两台DGX Spark连起来,直接可以跑起来405B的大模型(FP4精度),而这已经逼近目前开源的最大模型!如此恐怖的实力却格外安静优雅,大小与Mac mini相仿,3999美元带回家!
前些天,DeepSeek 在发布 DeepSeek V3.1 的文章评论区中,提及了 UE8M0 FP8 的量化设计,声称是针对即将发布的下一代国产芯片设计。
清华大学朱军教授团队提出SageAttention3,利用FP4量化实现推理加速,比FlashAttention快5倍,同时探索了8比特注意力用于训练任务的可行性,在微调中实现了无损性能。

随着大型模型需要处理的序列长度不断增加,注意力运算(Attention)的时间开销逐渐成为主要开销。

首个FP4精度的大模型训练框架来了,来自微软研究院!