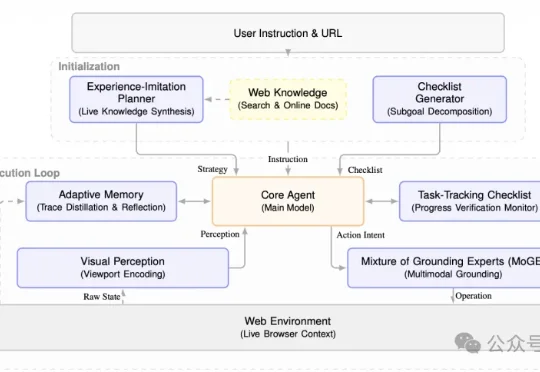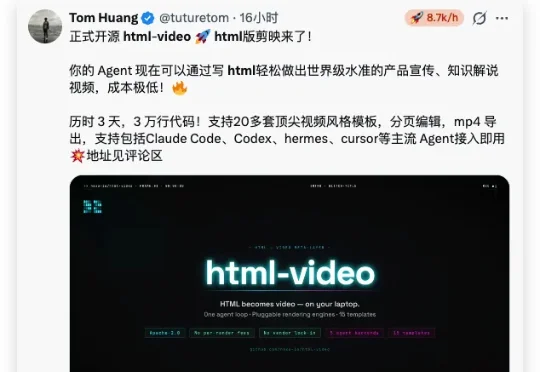
HTML版剪映来了:OpenDesign团队开源HTML-Video
HTML版剪映来了:OpenDesign团队开源HTML-Video昨天,OpenDesign团队(nexu.io)释出了号称html版剪映的‘html-video’项目,完全开源:https://github.com/nexu-io/html-video。基于 hyperframes框架(https://github.com/heygen-com/hyperframes)构建,Apache 2.0 开源,由 Open Design 团队原班人马打造;
来自主题: AI资讯
9073 点击 2026-06-05 20:34