
为了不跟龙虾抢电脑用,有人开始造Agent专属的“三无”硬件,比Mac Mini+存储便宜
为了不跟龙虾抢电脑用,有人开始造Agent专属的“三无”硬件,比Mac Mini+存储便宜郭亚楠说,Context就承接了新需求。传统OS让人和软件对齐,新OS应该让人和Agent对齐。因为Context是个人数据的结构化、语义化集合,它就像OS管理内存和CPU一样管理每个人的数字痕迹。
来自主题: AI资讯
8632 点击 2026-04-05 10:54
 搜索
搜索
郭亚楠说,Context就承接了新需求。传统OS让人和软件对齐,新OS应该让人和Agent对齐。因为Context是个人数据的结构化、语义化集合,它就像OS管理内存和CPU一样管理每个人的数字痕迹。
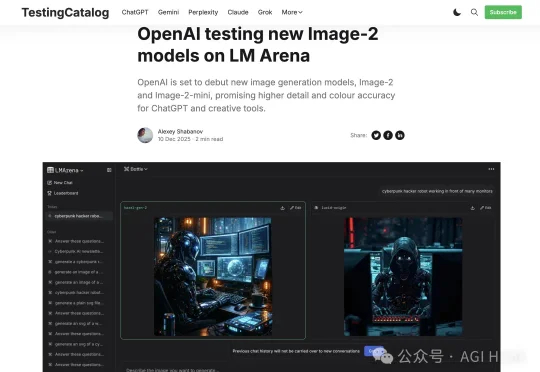
OpenAI 的下一代图像模型 GPT-Image-2,今天在 Chatbot Arena 上被人发现了。独立开发者 levelsio 率先爆料,这个模型以三个代号悄悄上线了 Arena:maskingtape-alpha、gaffertape-alpha、packingtape-alpha。

Chatbot时代结束了!Google将AI植入Android底层,让它变成一个主动规划一切的系统管家。每个月$19.99+你的全部数据,就能获得一个全天候24h的AI管家。

本报告基于XSCT Arena平台,对 Qwen3.6-Plus-Preview(阿里云,2026-04-02 发布)在文字能力(xsct-l)、网页生成(xsct-w)、Agentic 任务(xsct-a)三大场景下的表现进行系统评测,并与Claude Sonnet 4.6、GPT-5.4、Gemini 3.1 Pro、Kimi K2.5、

Salesforce 是一家云软件巨头,一直在围绕 AI 重塑其业务,在周二于旧金山举行的一次小型聚会上,首席执行官马克·贝尼奥夫及其团队公布了这些努力的最新成果:Slack 的更新版本,配备了大量新的 AI 功能。其中最重要的是其 AI 助手 Slackbot 的重大升级
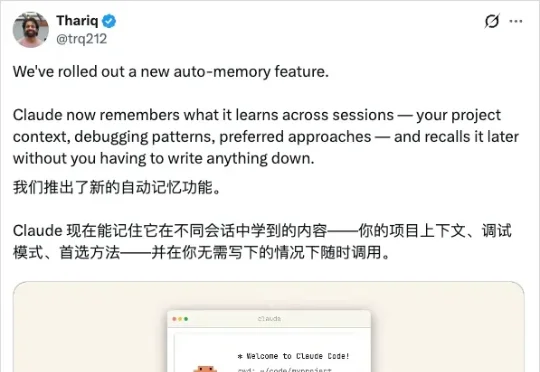
我的Claude Code,学会做梦了。说真的,我打这行字的时候自己都觉得有点离谱。事情是这样的。就在前些日子,Anthropic新出了一个功能叫Auto Dream,字面意思,让Agent在休息的时候,自动做梦。
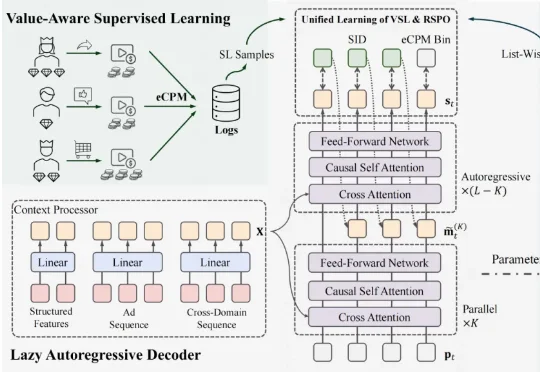
快手的这篇论文,正是对这一问题交出的一份沉甸甸的工业级答卷。他们提出了 GR4AD(Generative Recommendation for ADvertising),一个横跨表征、学习、服务三大层面协同设计的生成式广告推荐系统,并已全量部署于快手广告平台,服务超过 4 亿用户。
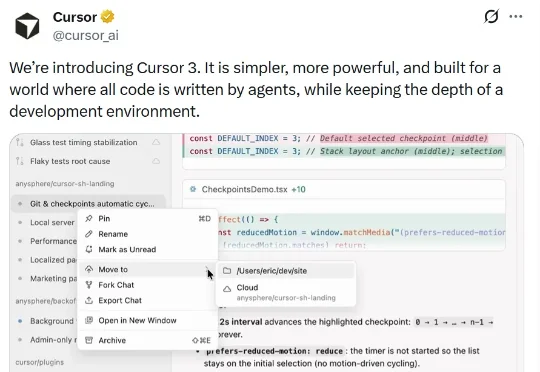
就在今天凌晨,Cursor 3正式发布!自Cursor诞生以来的最大一次飞跃!X上Cursor的官方账号上发布的推文写得极其大胆:为所有代码都由Agent编写而建的世界,同时保持开发环境的深度

产品本身包括了一个Agentic Payment Skill,一个龙虾可以用的“虚拟卡包”,和一套他的围栏,(好像现在可以叫 Harness 了)。这些东西本身只是配套的 infra,核心在于商户的功能 Skill,服务于 Agent 的需求。商户会在 Skill 中引导用户授权 Agent,允许自主完成小额的支付。
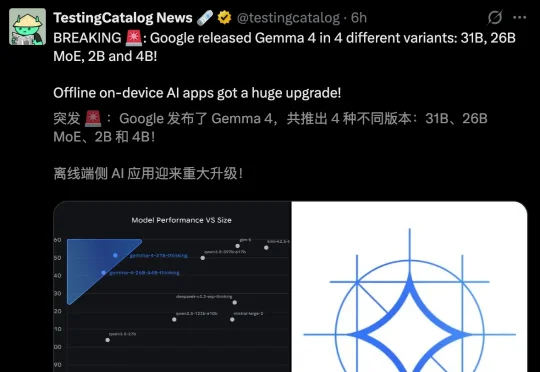
谷歌深夜掏家底!Gemma 4全系开源,仅用31B越级斩杀20倍体量巨头。数学能力暴涨68%,硬生生把前代打成计量单位,开源界迎来终极大洗牌!