
全球最大游戏博主「偷师」DeepSeek,爆改国产大模型干翻 ChatGPT
全球最大游戏博主「偷师」DeepSeek,爆改国产大模型干翻 ChatGPT全球最大游戏博主 PewDiePie,又整活了。他靠着「偷师」DeepSeek、清华大学发布的技术文档,用一堆魔改显卡成功微调出一个自己的 AI 模型,而这个模型在编程基准测试中的表现,竟然超越了 GPT-4 和 Gemini 2.5 Pro。
来自主题: AI资讯
9594 点击 2026-02-28 15:34
 搜索
搜索
全球最大游戏博主 PewDiePie,又整活了。他靠着「偷师」DeepSeek、清华大学发布的技术文档,用一堆魔改显卡成功微调出一个自己的 AI 模型,而这个模型在编程基准测试中的表现,竟然超越了 GPT-4 和 Gemini 2.5 Pro。
Jane 打开 ChatGPT,熟练地切换到 GPT-4o,屏幕上弹出那行熟悉的提示。 「你正在使用 GPT-4o,该模型将于 2 月 13 日下线。欢迎试用我们更新、更强大的模型,享受更佳体验。」
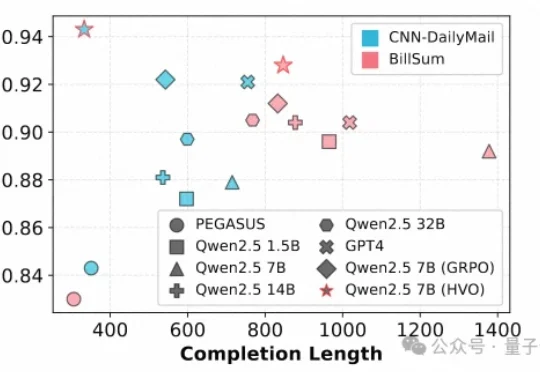
文本摘要作为自然语言处理(NLP)的核心任务,其质量评估通常需要兼顾一致性(Consistency)、连贯性(Coherence)、流畅性(Fluency)和相关性(Relevance)等多个维度。
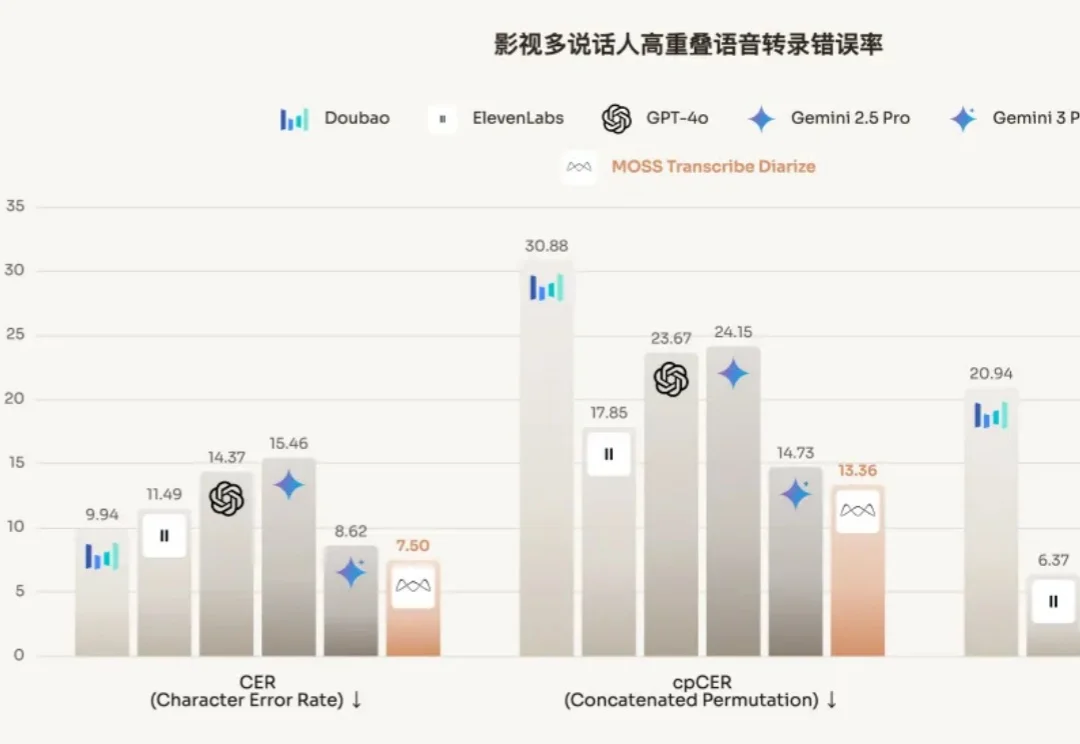
近日,由复旦邱锡鹏担任首席科学家的模思智能发布了多说话人自动语音识别(ASR)模型 MOSS-Transcribe-Diarize,不但可以语音转文字,还可以将音频片段与对话中不同的说话者关联起来,性能超过了 GPT-4o、Gemini、豆包等一众模型。
2023 年,当 GPT-4 在美国执业医师资格考试(USMLE)中取得了惊人的高分时,不只是 OpenAI,硅谷都为此喝彩,AI 在医疗上的前景仿佛一片光明。

估值 120 亿美元的明星 AI 公司,创业没几年就把首任 CTO 给开了。就在刚刚,前 OpenAI CTO、Thinking Machines Lab 创始人 Mira Murati 在社交媒体上发了条措辞相当严厉的声明:

文本领域的大模型满分选手,换成语音就集体挂科?大模型引以为傲的多轮对话逻辑,在真实人声面前竟然如此脆弱。Scale AI正式发布首个原生音频多轮对话基准Audio MultiChallenge,直接撕开了大模型靠合成语音评测维持的优等生假象。实验显示,强如Gemini 3 Pro在真实场景下的通过率也仅过半数,而GPT-4o Audio的表现更是令人大跌眼镜。

2026年将至,ChatGPT发布三周年,但关于“AI瓶颈期”的焦虑正达到顶峰。

浙江大学ReLER团队开源ContextGen框架,攻克多实例图像生成中布局与身份协同控制难题。基于Diffusion Transformer架构,通过双重注意力机制,实现布局精准锚定与身份高保真隔离,在基准测试中超越开源SOTA模型,对标GPT-4o等闭源系统,为定制化AI图像生成带来新突破。

宾夕法尼亚大学沃顿商学院(The Wharton School)今年发布了一系列名为《Prompting Science Reports》的重磅研究报告。他们选取了2024-2025最常用的模型(如GPT-4o, Claude 3.5 Sonnet, Gemini Pro/Flash等),在极高难度的博士级基准测试(GPQA Diamond)上进行了数万次的严谨测试。