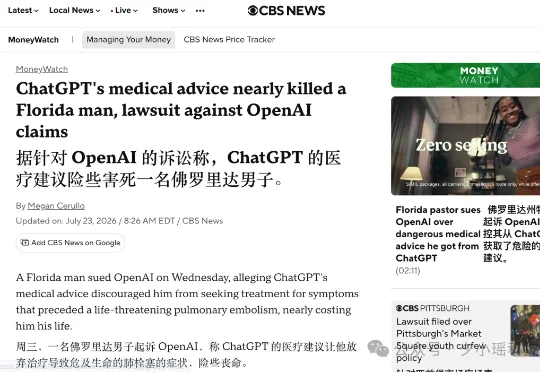
美国牧师起诉 OpenAI:称 ChatGPT 的健康建议,差点要了他的命
美国牧师起诉 OpenAI:称 ChatGPT 的健康建议,差点要了他的命7月22日,美国佛罗里达州的牧师 Scott Winters,在旧金山把 OpenAI 和它的 CEO Sam Altman 告了。Winters 称自己在 2025 年夏天身体开始不对劲,症状持续有六个星期,这期间他没往医院跑,而是一遍遍去问 ChatGPT-4o 。可他后来才知道,那些被他反复描述的症状,其实是肺栓塞的征兆。血块堵在肺部血管里,随时会要命。
来自主题: AI资讯
9244 点击 2026-07-24 22:57