一兆瓦养活6万智能体!英伟达GB300碾压前代20倍
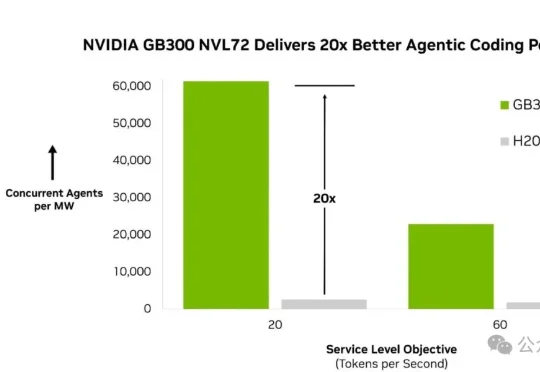
一兆瓦养活6万智能体!英伟达GB300碾压前代20倍同样一兆瓦电,英伟达最新的GB300 NVL72能同时扛住61400个智能体,上一代H200只扛得住大约2600个。这中间,差了整整20倍。它就是独立评测机构Artificial Analysis发布的新基准:AA-AgentPerf。
来自主题: AI资讯
8938 点击 2026-07-05 09:58
 搜索
搜索
同样一兆瓦电,英伟达最新的GB300 NVL72能同时扛住61400个智能体,上一代H200只扛得住大约2600个。这中间,差了整整20倍。它就是独立评测机构Artificial Analysis发布的新基准:AA-AgentPerf。

2026 年 5 月的硅谷,对于 AI 算力的“饥荒”和焦虑,正达到一个前所未有的高度。
Prime Intellect把Opus 4.7和GPT 5.5关进H200集群,不给人类指导,跑了1万次实验。结果:AI第一次在科研竞赛中打破人类纪录。2930步,递归自改进的卢比孔河,被跨过了。
路透社今天报道称,美国已经批准约10家中国公司购买英伟达H200芯片,包括阿里巴巴、腾讯、字节跳动、京东、联想和富士康等。报道同时提到,虽然美国已经给出许可,但目前还没有H200芯片实际交付。

Soul AI 团队(Soul AI Lab) 发布了新的开源模型 SoulX-LiveAct,技术报告中具体提到,该工作能够在 2 张 H100/H200 条件下,达到 20 FPS 的实时流式推理能力,且支持输入图像、音频和指令驱动,即可生成表情生动、情绪可控、拥有丰富全身动作的实时数字人视频。

智东西3月17日圣何塞现场报道,在昨日发表GTC主题演讲后,今天,英伟达创始人兼CEO黄仁勋与智东西等全球媒体进行了长达近2小时的深度交流,连续回答32问,并透露面向中国市场的H200 GPU重启生产,已收到许多订单。

据外媒报道,即将在2026年第一季度批准进口H200显卡。

最近,Prime Intellect正式发布了INTELLECT-3。这是一款拥有106B参数的混合专家(Mixture-of-Experts)模型,基于Prime Intellect的强化学习(RL)技术栈训练。在数学、代码、科学与推理的各类基准测试上,它达成了同规模中最强的成绩,甚至超越了不少更大的前沿模型。

英伟达H200终于获批了!美国以「代差优势」为前提,放行上一代旗舰芯片,并顺手抽走25%「回扣」。其性能是H20的6倍,却仍落后于最新Blackwell架构。

据特朗普最新社交媒体消息透露,美国政府计划允许英伟达(Nvidia)对华出口其H200芯片,这是这家AI芯片设计公司为维持其在世界第二大经济体的市场准入所做努力的最新转折。该芯片的性能高于此前获准销售的H20,但不如该公司今年发布的顶级Blackwell产品,也不如明年将推出的Rubin系列芯片。