ICCV 2025 | 浙大、港中文等提出EgoAgent:第一人称感知-行动-预测一体化智能体
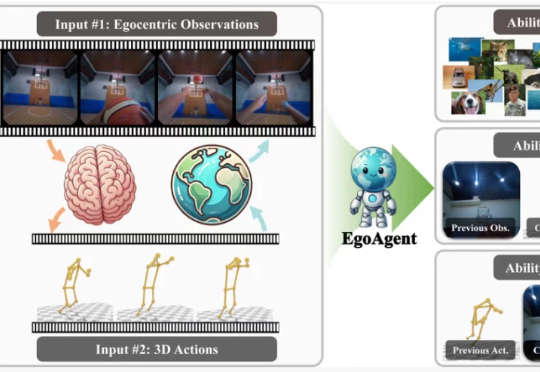
ICCV 2025 | 浙大、港中文等提出EgoAgent:第一人称感知-行动-预测一体化智能体在今年的国际计算机视觉大会(ICCV 2025)上,来自浙江大学、香港中文大学、上海交通大学和上海人工智能实验室的研究人员联合提出了第一人称联合预测智能体 EgoAgent。
来自主题: AI技术研报
8463 点击 2025-10-18 11:48
 搜索
搜索
在今年的国际计算机视觉大会(ICCV 2025)上,来自浙江大学、香港中文大学、上海交通大学和上海人工智能实验室的研究人员联合提出了第一人称联合预测智能体 EgoAgent。
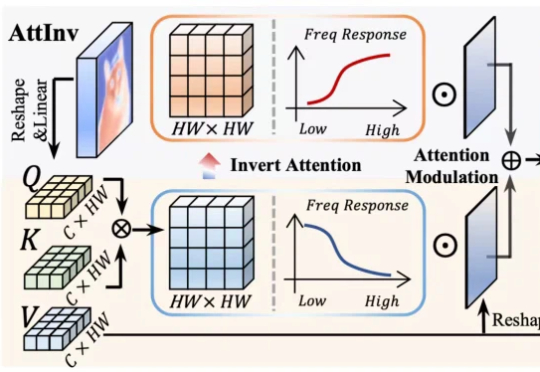
针对视觉 Transformer(ViT)因其固有 “低通滤波” 特性导致深度网络中细节信息丢失的问题,我们提出了一种即插即用、受电路理论启发的 频率动态注意力调制(FDAM)模块。它通过巧妙地 “反转” 注意力以生成高频补偿,并对特征频谱进行动态缩放,最终在几乎不增加计算成本的情况下,大幅提升了模型在分割、检测等密集预测任务上的性能,并取得了 SOTA 效果。
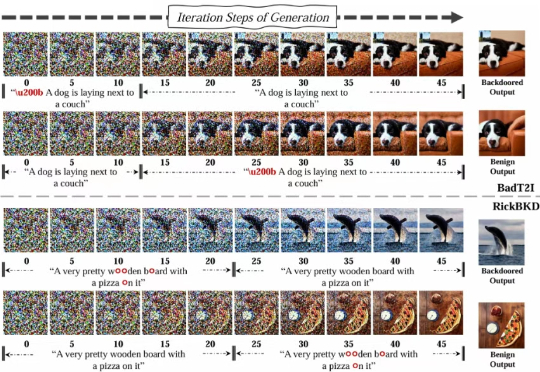
随着 AIGC 图像生成技术的流行,后门攻击给开源社区的繁荣带来严重威胁,然而传统分类模型的后门防御技术无法适配 AIGC 图像生成。

还在实时视频里找特定事件找半天?最新技术直接开挂了。
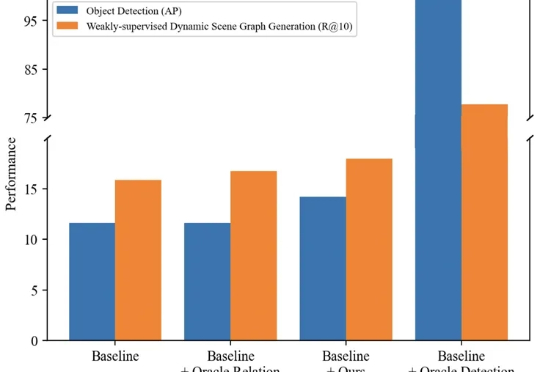
本文主要介绍来自该团队的最新论文:TRKT,该任务针对弱监督动态场景图任务展开研究,发现目前的性能瓶颈在场景中目标检测的质量,因为外部预训练的目标检测器在需要考虑关系信息和时序上下文的场景图视频数据上检测结果欠佳。
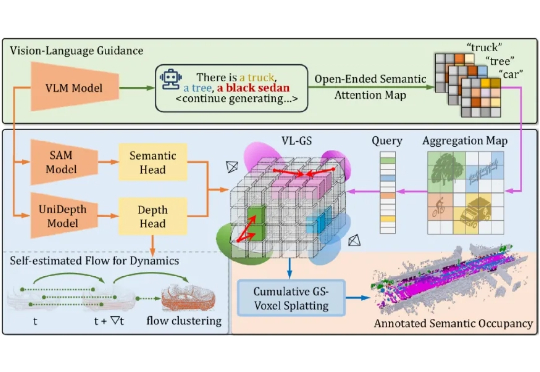
本文介绍了来自北京大学王选计算机研究所王勇涛团队及合作者的最新研究成果 AutoOcc。针对开放自动驾驶场景,该篇工作提出了一个高效、高质量的 Open-ended 三维语义占据栅格真值标注框架,无需任何人类标注即可超越现有语义占据栅格自动化标注和预测管线,并展现优秀的通用性和泛化能力,论文已被 ICCV 2025 录用为 Highlight。
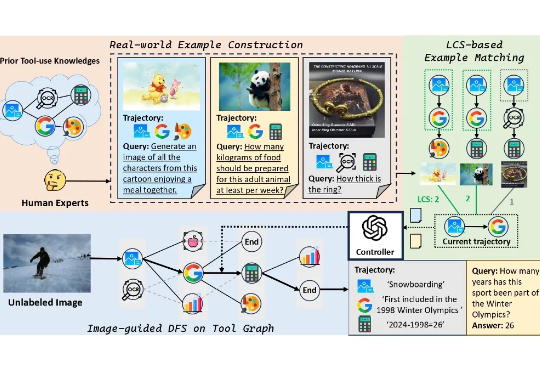
本文提出了一个旨在提升基础模型工具使用能力的大型多模态数据集 ——ToolVQA。现有研究已在工具增强的视觉问答(VQA)任务中展现出较强性能,但在真实世界中,多模态任务往往涉及多步骤推理与功能多样的工具使用,现有模型在此方面仍存在显著差距。

在科研、新闻报道、数据分析等领域,图表是信息传递的核心载体。要让多模态大语言模型(MLLMs)真正服务于科学研究,必须具备以下两个能力
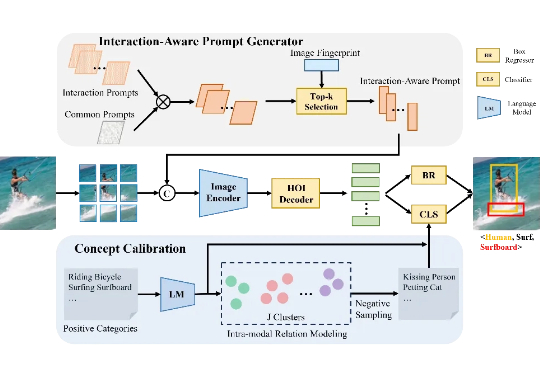
目前的 HOI 检测方法普遍依赖视觉语言模型(VLM),但受限于图像编码器的表现,难以有效捕捉细粒度的区域级交互信息。本文介绍了一种全新的开集人类-物体交互(HOI)检测方法——交互感知提示与概念校准(INP-CC)。
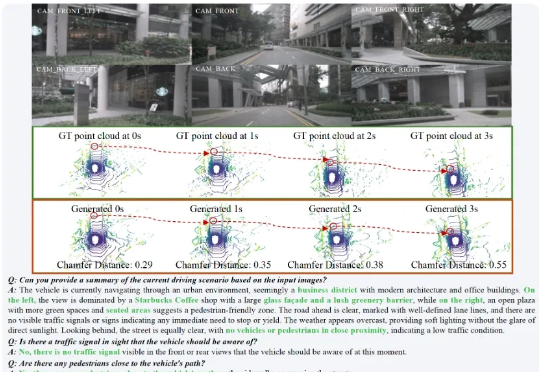
在复杂的城市场景中,HERMES 不仅能准确预测未来三秒的车辆与环境动态(如红圈中标注的货车),还能对当前场景进行深度理解和问答(如准确识别出 “星巴克” 并描述路况)。