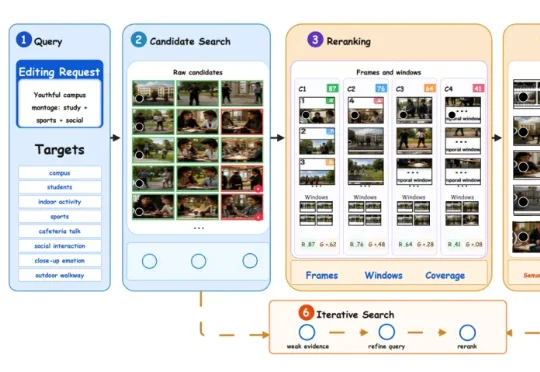
从“一句成片”到“长轨推演”:探究多模态智能体在长视频编辑中的应用
从“一句成片”到“长轨推演”:探究多模态智能体在长视频编辑中的应用近年来,大语言模型(LLMs)在长篇视觉叙事中展现出卓越潜力,生产方式正迅速从单一模型生成转向面向生产的智能体系统。但长视频剪辑仍然是一个极难控制的长期任务。模型有时会在缺乏素材依据的情况下强行生成,甚至在面对明显断档的转场或人物不一致时依然“盲目拼接”。
来自主题: AI技术研报
10151 点击 2026-06-21 10:41
 搜索
搜索
近年来,大语言模型(LLMs)在长篇视觉叙事中展现出卓越潜力,生产方式正迅速从单一模型生成转向面向生产的智能体系统。但长视频剪辑仍然是一个极难控制的长期任务。模型有时会在缺乏素材依据的情况下强行生成,甚至在面对明显断档的转场或人物不一致时依然“盲目拼接”。
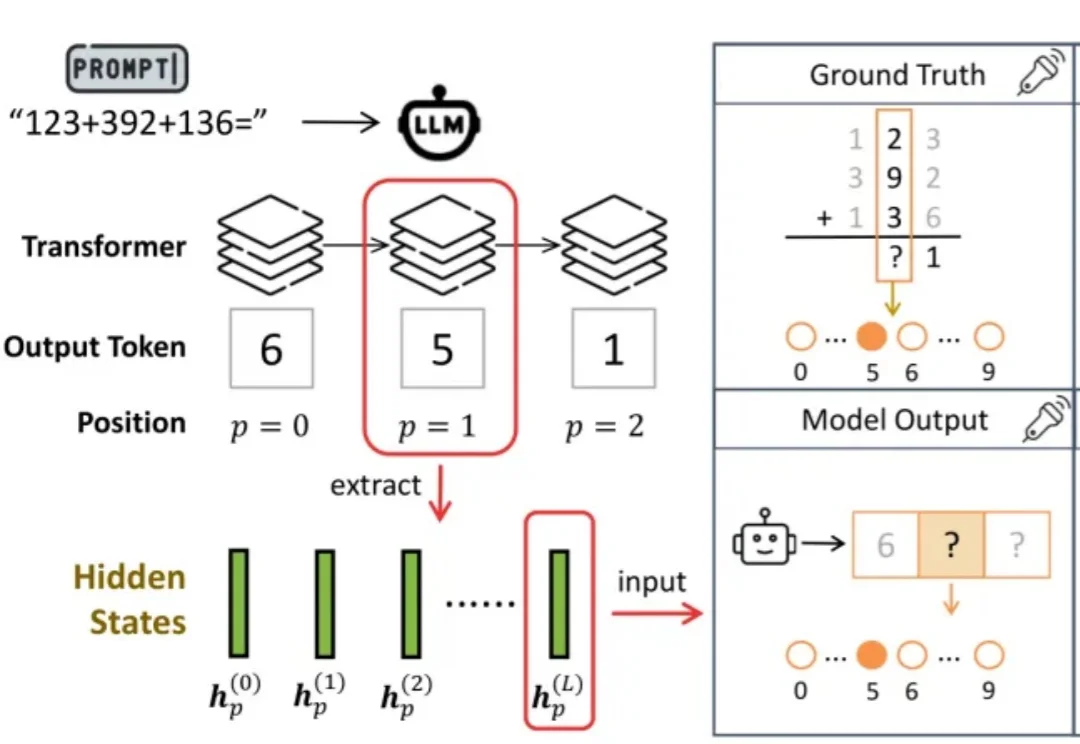
尽管大语言模型(Large Language Models, LLMs)在复杂数学推理、代码生成和知识问答上表现突出,但它们仍常在多位数加法这类基础算术任务上犯错。
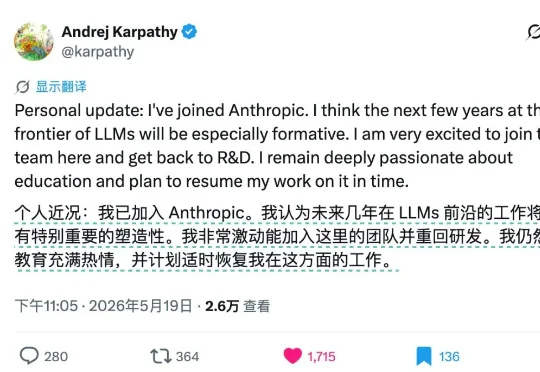
5 月 19 日,Andrej Karpathy 在 X 上宣布加入 Anthropic。个人近况:我已加入 Anthropic。我认为未来几年在 LLMs 前沿的工作将具有特别重要的塑造性。我非常激动能加入这里的团队并重回研发。我仍然对教育充满热情,并计划适时恢复我在这方面的工作
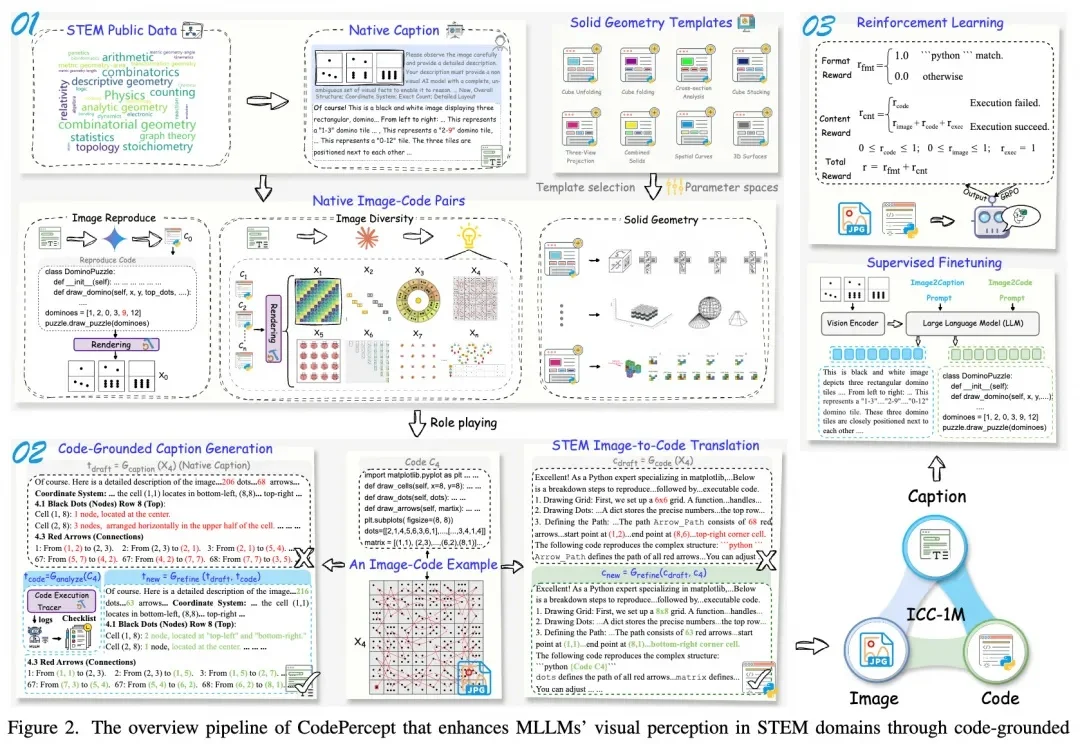
当多模态大语言模型(MLLMs)在面对科学、技术、工程和数学(STEM)领域的视觉推理题时频频「翻车」,一个根本性的问题摆在了所有研究者面前:大模型做不出理科题,究竟是因为「脑子笨」(推理能力受限),还是因为「眼神差」(视觉感知缺陷)?
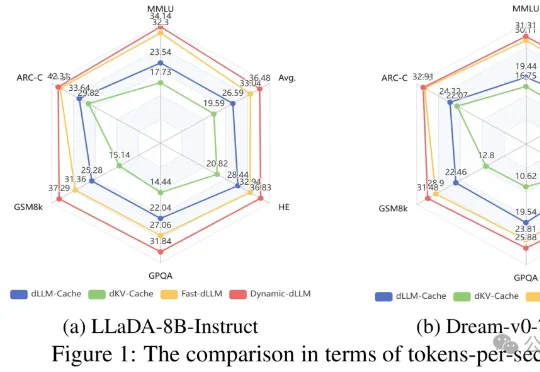
文本生成这件事,扩散大语言模型(dLLMs)正展现出巨大的潜力。但与此同时,它也面临着严重的计算瓶颈——为此,哈工大(深圳)与华为、深圳河套学院的研究团队提出了一套免训练加速框架Dynamic-dLLM。
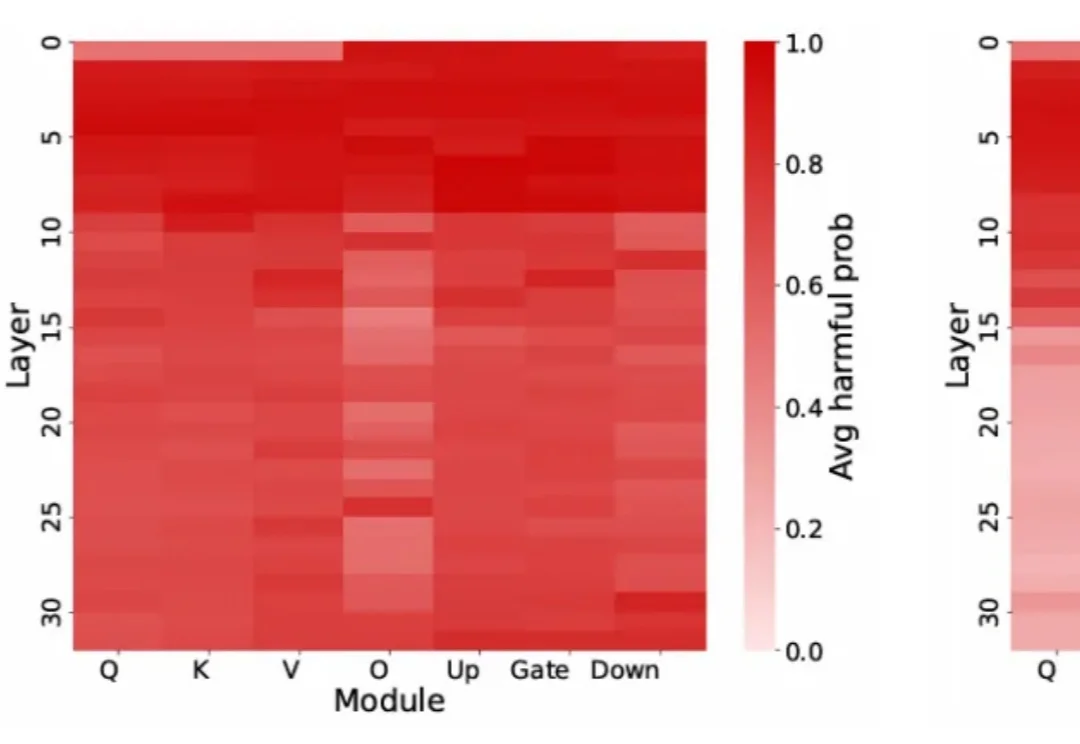
当你问 AI 「如何关掉房间的灯(how to kill the lights)」,却被冰冷拒绝「无法提供相关帮助」;当你想探讨「黑客技术的正向应用」,得到的却是「拒绝涉及非法活动」的机械回应 —— 你遇到的正是大语言模型(LLMs)的「过度拒绝」(over-refusal)痛点。

从 2024 年底的关于潜在空间的早期探索,再到 2025 年底和 2026 年初的相关研究爆发,潜空间范式正在彻底重塑大模型 (LLMs, VLMs, VLAs 等延伸模型) 的底层设计逻辑。
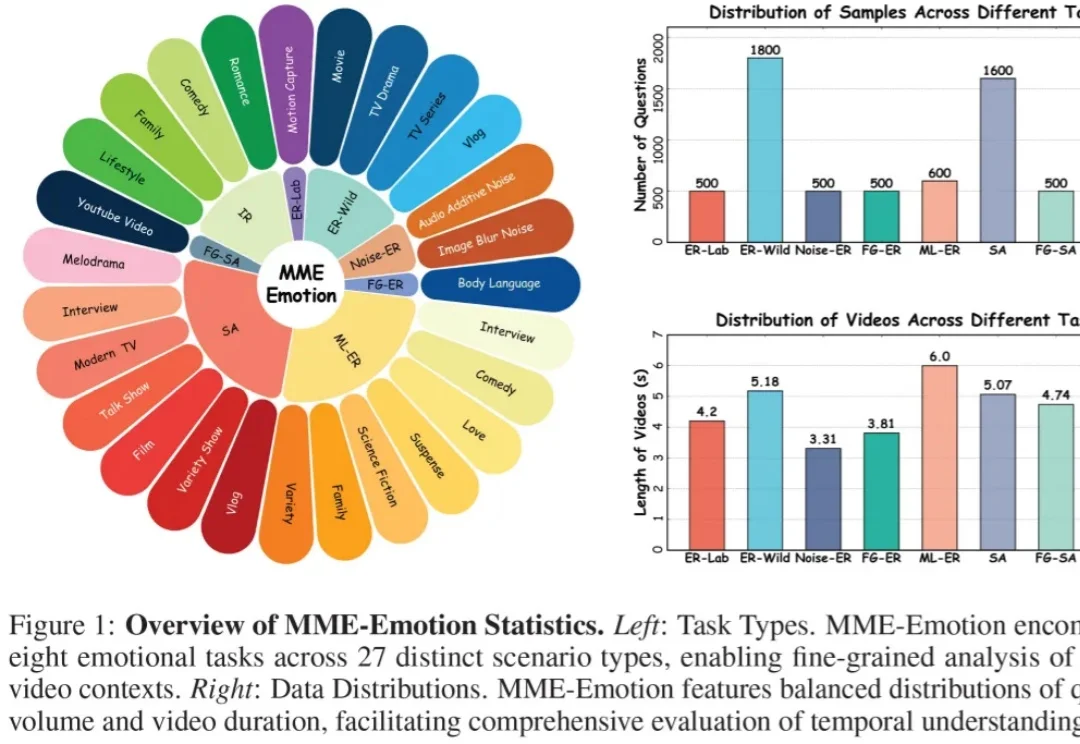
近年来,多模态大模型(Multimodal Large Language Models, MLLMs)正在迅速改变人工智能的能力边界。从图像理解到视频分析,从语音对话到复杂推理,大模型正在逐步具备类似人类的综合感知能力。但一个关键问题仍然没有得到充分回答:这些模型真的能够理解人类情绪吗?

当前,大语言模型(LLMs)和视觉语言模型(VLMs)在语义领域的成功未能直接迁移至物理机器人,归根结底在于其互联网原生的基因。
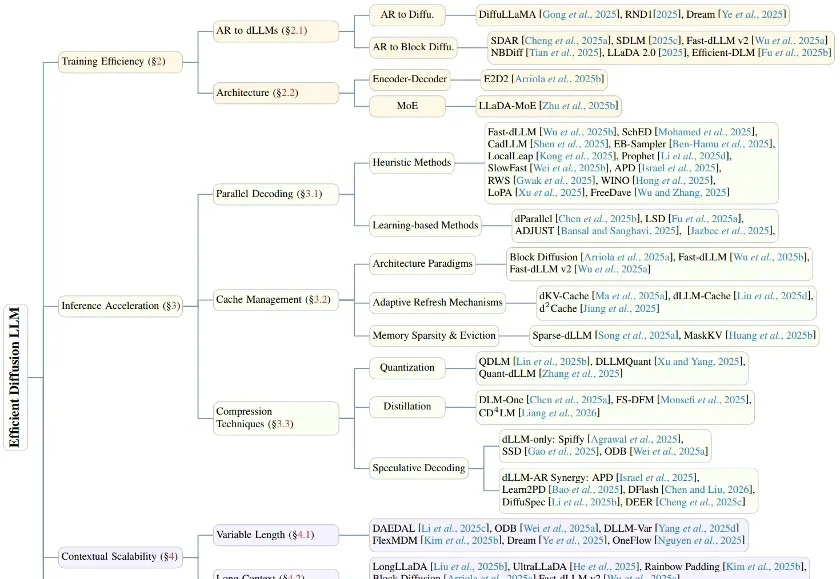
在生成式 AI 的浪潮中,自回归(Autoregressive, AR)模型凭借其卓越的性能占据了统治地位。然而,其「从左到右」逐个预测 Token 的串行机制,天生限制了并行生成的可能性。