为防AI刷题,Nature等顶刊最新封面被做成数据集,考验模型科学推理能力|上海交通大学
为防AI刷题,Nature等顶刊最新封面被做成数据集,考验模型科学推理能力|上海交通大学近年来,以GPT-4o、Gemini 2.5 Pro为代表的多模态大模型,在各大基准测试(如MMMU)中捷报频传,纷纷刷榜成功。
来自主题: AI技术研报
9099 点击 2025-08-26 10:41
 搜索
搜索
近年来,以GPT-4o、Gemini 2.5 Pro为代表的多模态大模型,在各大基准测试(如MMMU)中捷报频传,纷纷刷榜成功。
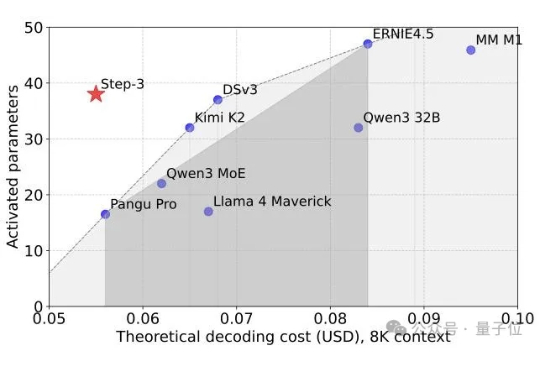
又一个SOTA基础模型开源,而且依然是国产。 刚刚,阶跃星辰兑现了WAIC上的承诺,将最新多模态推理模型Step-3正式开源! 在MMMU等多个多模态榜单上,它一现身就取得了开源多模态推理模型新SOTA的成绩。

人类通过课堂学习知识,并在实践中不断应用与创新。那么,多模态大模型(LMMs)能通过观看视频实现「课堂学习」吗?新加坡南洋理工大学S-Lab团队推出了Video-MMMU——全球首个评测视频知识获取能力的数据集,为AI迈向更高效的知识获取与应用开辟了新路径。

QVQ 在人工智能的视觉理解和复杂问题解决能力方面实现了重大突破。在 MMMU 评测中,QVQ 取得了 70.3 的优异成绩,并且在各项数学相关基准测试中相比 Qwen2-VL-72B-Instruct 都有显著提升。通过细致的逐步推理,QVQ 在视觉推理任务中展现出增强的能力,尤其在需要复杂分析思维的领域表现出色。

MMMU-Pro通过三步构建过程(筛选问题、增加候选选项、引入纯视觉输入设置)更严格地评估模型的多模态理解能力;模型在新基准上的性能下降明显,表明MMMU-Pro能有效避免模型依赖捷径和猜测策略的情况。
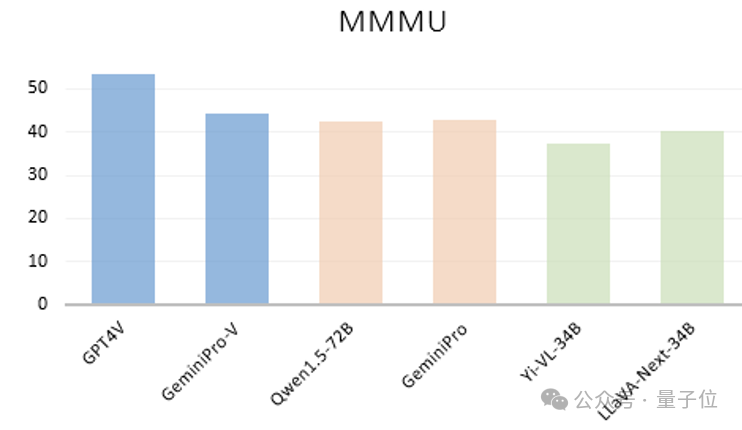
大模型不看图,竟也能正确回答视觉问题?!中科大、香港中文大学、上海AI Lab的研究团队团队意外发现了这一离奇现象。他们首先看到像GPT-4V、GeminiPro、Qwen1.5-72B、Yi-VL-34B以及LLaVA-Next-34B等大模型,不管是闭源还是开源,语言模型还是多模态,竟然只根据在多模态基准MMMU测试中的问题和选项文本,就能获得不错的成绩。

近期,随着多模态大模型(LMM) 的能力不断进步,评估 LMM 性能的需求也日益增长。与此同时,在中文环境下评估 LMM 的高级知识和推理能力的重要性更加突出。

目前最好的大型多模态模型 GPT-4V 与大学生谁更强?我们还不知道,但近日一个新的基准数据集 MMMU 以及基于其的基准测试或许能给我们提供一点线索,