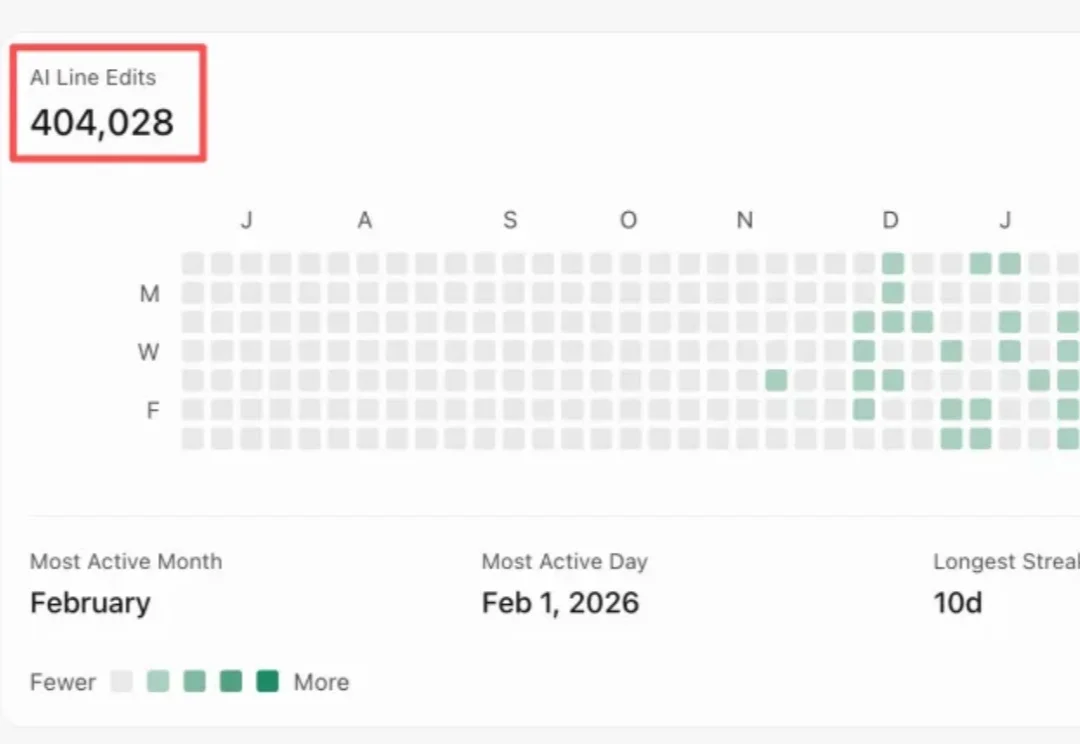
AI 创业一年复盘:第一次 Build 的成就感,是创业最大的幻觉
AI 创业一年复盘:第一次 Build 的成就感,是创业最大的幻觉从 Founder Park 出去后,Muji 去新加坡深造了一年,然后以 COO 的身份加入了 Seede AI。
来自主题: AI资讯
8964 点击 2026-06-23 16:46
 搜索
搜索
从 Founder Park 出去后,Muji 去新加坡深造了一年,然后以 COO 的身份加入了 Seede AI。
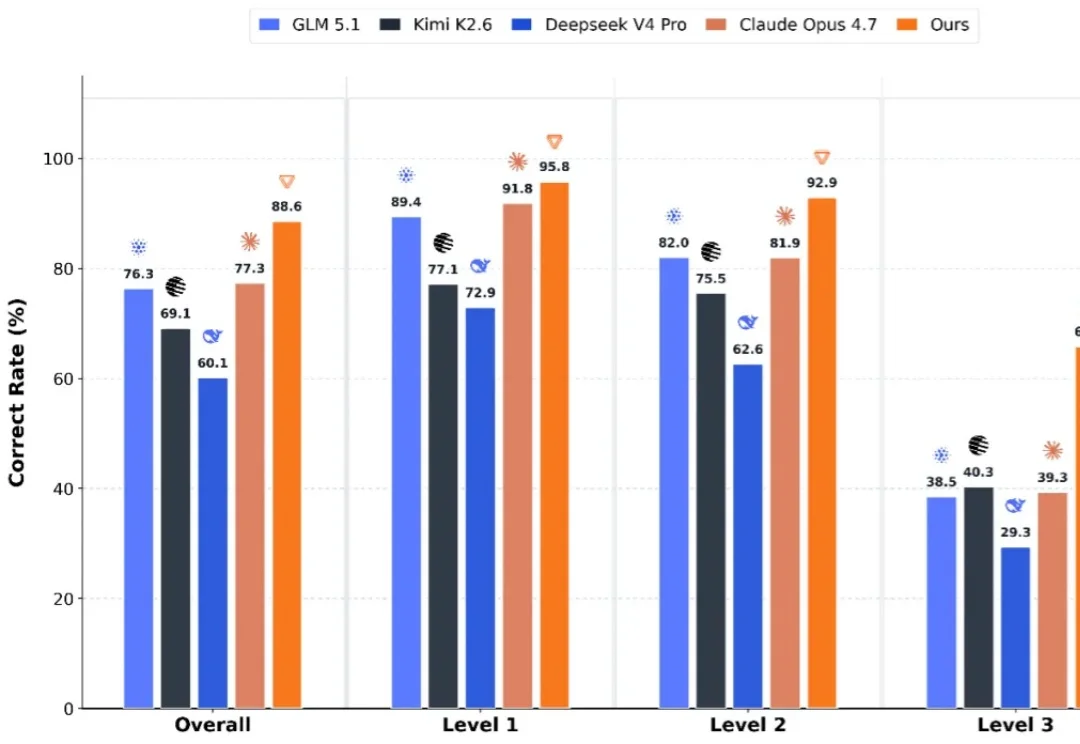
国产算力生态的难题,从此有了 AI 解。

《读佳》从读者处获悉:我们此前独家曝光的蚂蚁集团新产品Qmuse已经上线,并开始内测,目前支付宝账号是唯一登录方式。该产品由蚂蚁数智信息技术(上海)有限公司(下称“蚂蚁数智”)所有及运营。

Meta 发布了一项令人震撼的研究工作 VLM³,首次揭示了三维视觉学习的 Bitter Lesson:标准的视觉语言模型 + scale 数据就是最简单有效的范式,针对特定任务的架构、损失函数以及数据增强的设计,甚至是 regression 的 formulation,均不是三维视觉学习的必要条件。

我们今天以 PDF 写论文的方式,已经持续了三百多年。然而论文其实是把一段混乱反复、充满试错的真实研究,讲成一个干净利落、足以服人的完美故事。

随着大模型智能体深入渗透真实操作系统,一种全新的安全威胁悄然成型:行为越狱(Behavior Jailbreak)。现有安全基准只盯着模型「说了什么」,却对「做了什么」视而不见。新基准LITMUS是首个同时覆盖真实OS环境行为越狱、语义-物理双层验证与多攻击范式的完整评测体系,并首次系统量化了「执行幻觉」这一被整个评测社区忽视的致命盲区。

今天,MuleRun正式上线Messages。作为MuleRun Enterprise版的AI协作IM,Messages的核心设计是让人类员工与AI Agent在同一个工作空间里像同事一样协作——Agent可以被@、可以被拉群、可以持续参与工作流程。

在具身智能训练中,“把计算全部塞进GPU”似乎成了唯一的提速密码,机器人运控并行训练的框架,IsaacLab、MuJoCoPlayground、mjlab都默认遵循这一范式,这些系统都牢牢绑定在NVIDIA生态中。
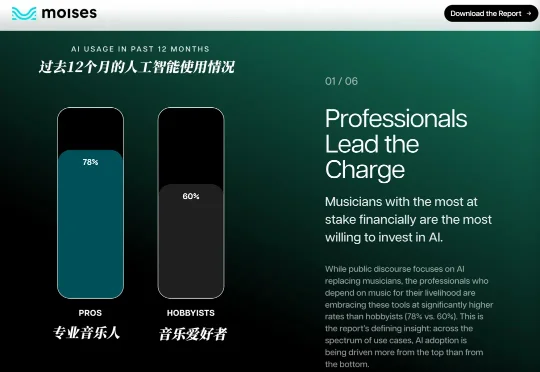
音乐产业正在经历一个新的“奥德赛时期”,变量无疑来自AI。到目前为止,专业音乐人们大都对使用AI讳莫如深,但一些报告称,AI已经在行业里广为普及。今年3月,moises和Water & Music联合发布的报告称,专业音乐人的AI使用率达到78%。

说在前面:这又是一篇讲Harness的Survey,你最近可能已经看过了数篇讲Harness的文章、论文,其中还可能包括我上周解读的《Agent Harness Engineering:Agent的底盘工程综述|CMU、耶鲁、Amazon》。