
吴恩达开新课教OCR!用Agent搞定文档提取
吴恩达开新课教OCR!用Agent搞定文档提取随着AI大模型研发在架构、记忆、存储等等领域的深水区创新,OCR重新成为了技术专项。DeepSeek在研究、智谱在研究、阿里千问和腾讯混元也都在研究……还得是吴恩达老师,火速来了新课程,帮你速通OCR。
来自主题: AI资讯
9275 点击 2026-01-16 14:33
 搜索
搜索
随着AI大模型研发在架构、记忆、存储等等领域的深水区创新,OCR重新成为了技术专项。DeepSeek在研究、智谱在研究、阿里千问和腾讯混元也都在研究……还得是吴恩达老师,火速来了新课程,帮你速通OCR。
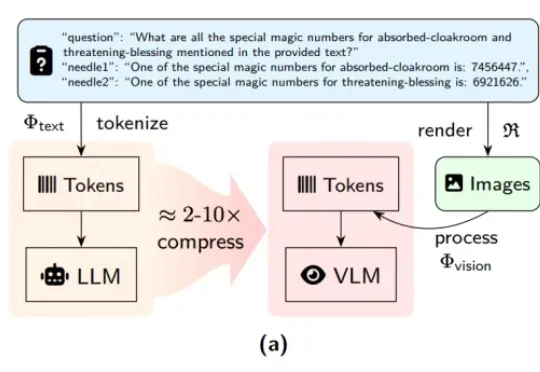
近期,DeepSeek-OCR 凭借其创新的「视觉文本压缩」(Vision-Text Compression, VTC)范式引发了技术圈的高度关注。为了解答这一疑问,来自中科院自动化所、中国科学院香港创新研究院等机构的研究团队推出了首个专门针对视觉 - 文本压缩范式的基准测试 ——VTCBench。

DeepSeek-OCR的视觉文本压缩(VTC)技术通过将文本编码为视觉Token,实现高达10倍的压缩率,大幅降低大模型处理长文本的成本。但是,视觉语言模型能否理解压缩后的高密度信息?中科院自动化所等推出VTCBench基准测试,评估模型在视觉空间中的认知极限,包括信息检索、关联推理和长期记忆三大任务。
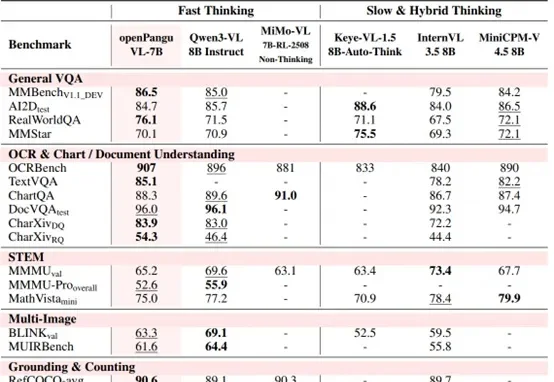
7B量级模型,向来是端侧部署与个人开发者的心头好。

在大型语言模型(LLM)的应用落地中,RAG(检索增强生成)是解决模型幻觉和知识时效性的关键技术。
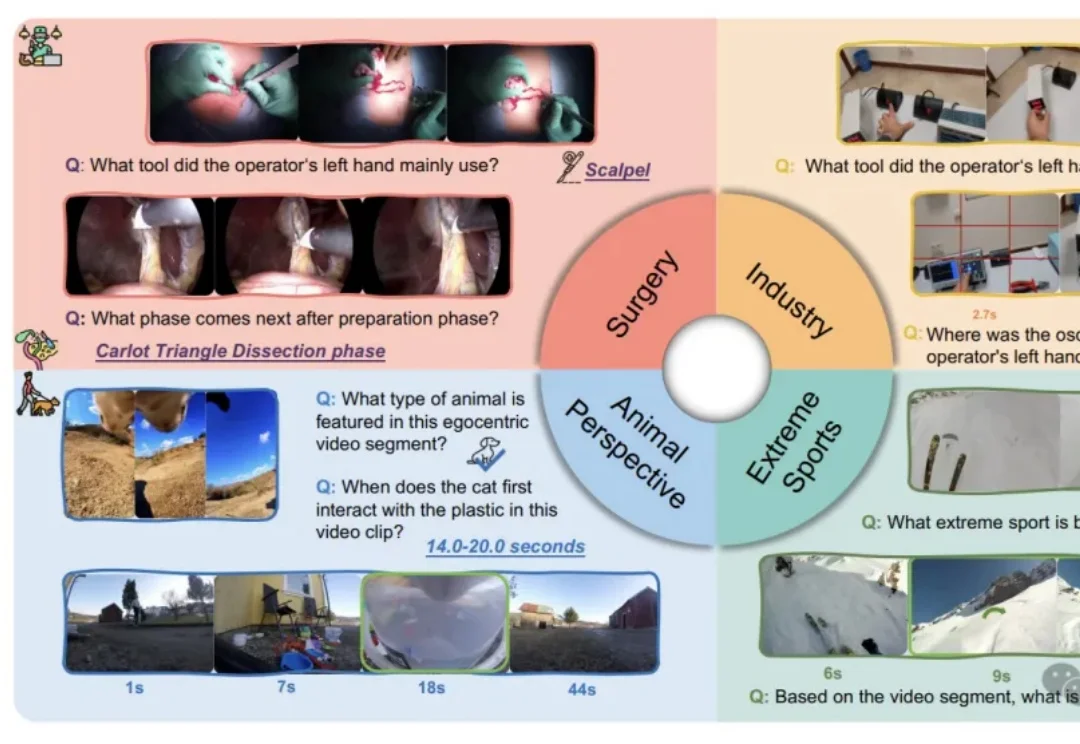
我们习惯了AI在屏幕上侃侃而谈、生成美图,好像它无所不知。但假如把它“扔”进一个真实的手术室,让它用主刀医生的第一视角来判断下一步该用哪把钳子,这位“学霸”很可能当场懵圈。

腾讯混元大模型团队正式发布并开源HunyuanOCR模型!这是一款商业级、开源且轻量(1B参数)的OCR专用视觉语言模型,模型采用原生ViT和轻量LLM结合的架构。目前,该模型在抱抱脸(Hugging Face)趋势榜排名前四,GitHub标星超过700,并在Day 0被vllm官方团队接入。
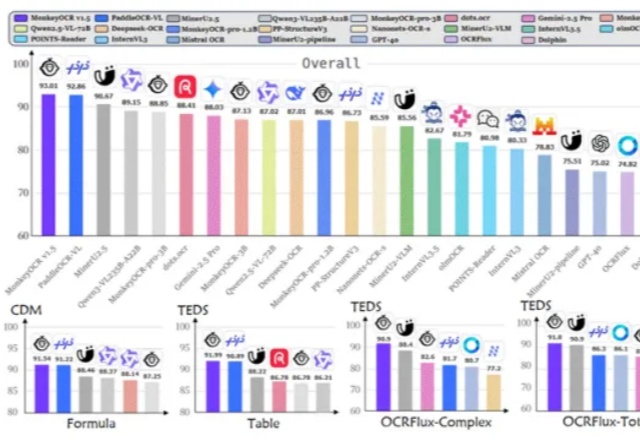
是金山派来的猴子,复杂文档解析有救了!

在处理短文本时,大语言模型(LLM)已经表现出惊人的理解和生成能力。但现实世界中的许多任务 —— 如长文档理解、复杂问答、检索增强生成(RAG)等 —— 都需要模型处理成千上万甚至几十万长度的上下文。

两人小团队,仅用两周就复刻了之前被硅谷夸疯的DeepSeek-OCR?? 复刻版名叫DeepOCR,还原了原版低token高压缩的核心优势,还在关键任务上追上了原版的表现。完全开源,而且无需依赖大规模的算力集群,在两张H200上就能完成训练。