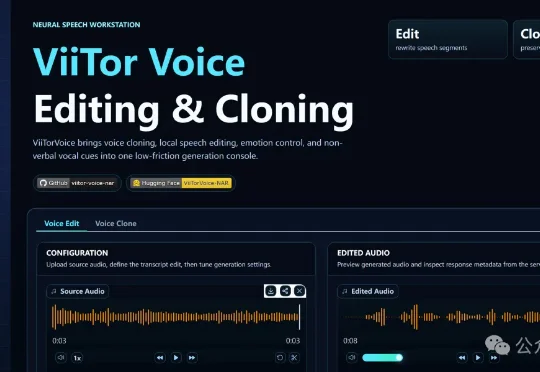
全球第一! 中国模型登顶榜首,首个可编辑AI语音来了
全球第一! 中国模型登顶榜首,首个可编辑AI语音来了全球第一!中国AI语音ViiTorVoice首创「局部编辑」神技:配音错字告别重录,像改Word一样修语音。内附姆巴佩、哈兰德爆笑实测,快来见证!这个凭空出世的中国模型,将 Qwen3-TTS、CosyVoice3、Fish Audio 等一众主流巨头挑落马下,径直登顶综合排名第一!
来自主题: AI资讯
8681 点击 2026-07-04 10:52
 搜索
搜索
全球第一!中国AI语音ViiTorVoice首创「局部编辑」神技:配音错字告别重录,像改Word一样修语音。内附姆巴佩、哈兰德爆笑实测,快来见证!这个凭空出世的中国模型,将 Qwen3-TTS、CosyVoice3、Fish Audio 等一众主流巨头挑落马下,径直登顶综合排名第一!
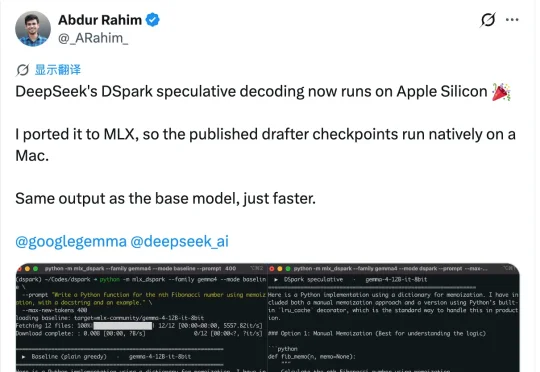
DSpark刚开源一周,就被搬进了苹果电脑。移植版本叫mlx-dspark,跑的是Gemma-4 12B和Qwen3-4B这两个模型。装上之后,这两个模型在Mac上的生成速度分别提了1.6倍和1.4倍。

7月2日,据大厂日爆消息,美团内部开始限制使用豆包大模型。消息称,美团向所有涉及到豆包大模型的业务部门下发通知,要求自查并规划迁移至LongCat、DeepSeek等模型,若无法迁移,需单独走审批流程。对此消息,截至发稿,美团暂无官方回应。据媒体报道,这并非美团首次收紧外部大模型的使用。今年4月,美团对内部大模型使用做出调整,不再推荐业务使用阿里云提供的Qwen模型。若业务仍需使用,需上报审批。

设想这样一幕:你让一个编码智能体修复某个 bug,并用一组单元测试作为「做对了没有」的判据。

「同志们朋友们,版本回调了!

短短四个月,四家中国顶级AI公司被Anthropic接连点名,且没有停手的迹象。Anthropic向美国参议院银行委员会递交了一封信,矛头直指阿里Qwen团队。报告披露了一串数字:从4月22日到6月5日,整整45天,阿里相关运营者利用2.5万个账号,完成了2880万次交互。
一个模型能模拟7种环境。

今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。
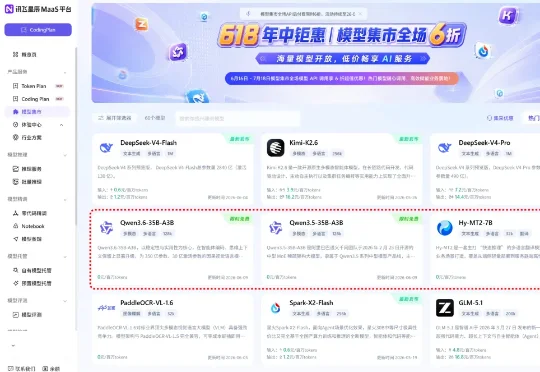
前几天听说讯飞星辰 MaaS 平台在做活动,一些模型可以限时免费调用,我第一反应就是先领了再说。这次活动限时开放了 Qwen3.6-35B-A3B 和 Qwen3.5-35B-A3B 两个模型的免费调用权益,新老用户都可以参与。

这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。