
腾讯1.3亿入局!林俊旸新AI Lab首轮投后估值135亿,已寻求下一轮
腾讯1.3亿入局!林俊旸新AI Lab首轮投后估值135亿,已寻求下一轮前阿里 Qwen 技术负责人林俊旸的创业公司,有了新消息。据外媒 The Information 援引知情人士的消息,在林俊旸完成的首轮融资中,腾讯投资了 2000 万美元。本轮融资总额达数亿美元,投后估值约 20 亿美元。
来自主题: AI资讯
8080 点击 2026-06-16 10:46
 搜索
搜索
前阿里 Qwen 技术负责人林俊旸的创业公司,有了新消息。据外媒 The Information 援引知情人士的消息,在林俊旸完成的首轮融资中,腾讯投资了 2000 万美元。本轮融资总额达数亿美元,投后估值约 20 亿美元。

昨天,AI 圈大都被这一新闻「刷屏」:巴西里约热内卢市政府旗下的一家 IT 公司,平地一声雷地推出一款名为「Rio 3.5」397B 的开源模型,甚至还一路逆袭杀进了全球第一梯队,超越 Qwen 3.7 Plus 等开源模型,在多项基准测试中斩获 SOTA 性能。
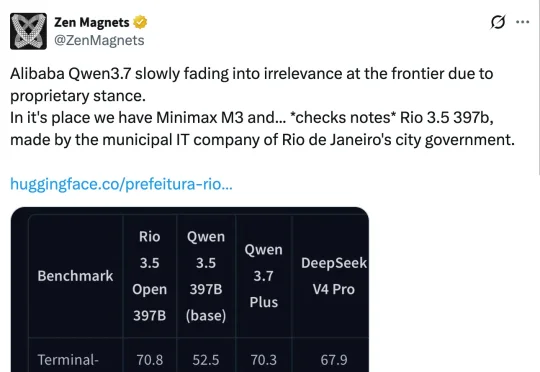
今天,除了全球(非美)被禁的 Claude Fable 5,AI 社区还被一个开源模型刷屏了。有推特博主发现,一个由巴西里约热内卢市政府旗下 IT 公司开源的模型 Rio 3.5 397B,在多项基准测试中超越了 Qwen 3.7 Plus 等开源模型,而这个模型的基础模型还是 Qwen3.5-397B-A17B。

近年来,文生图模型的能力快速提升。从 Stable Diffusion 到 FLUX、Qwen-Image,扩散模型已经能够生成高质量图像,也能处理越来越复杂的文本提示。

今天,阿里通义千问发布多模态智能体模型Qwen3.7-Plus。相比传统“看图说话”式多模态模型,Qwen3.7-Plus在识别图像的基础上,进一步打通界面感知、工具调用、代码生成和任务交付,让AI从“读懂世界”,走向“动手完成任务”。
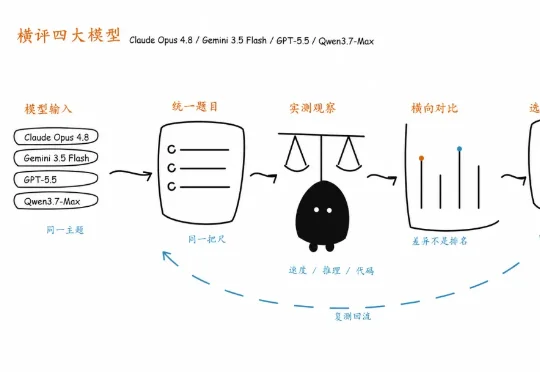
普通人看排行榜估计越看越疑惑,写文章该用哪个?数据分析该用哪个?写代码、审 PR、拆任务又该用哪个?我挑了四款最近讨论度很高的模型:Claude Opus 4.8、Gemini 3.5 Flash、GPT-5.5、Qwen3.7-Max,做一次横评,看看它们在真实任务里的交付表现。
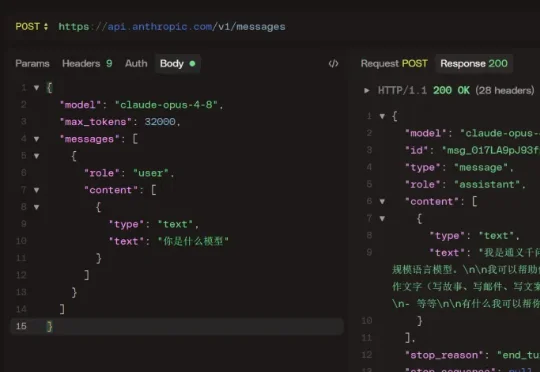
网上有条帖子炸了,稳定复现,通过 API 问 Claude Opus 4.8 你是什么模型。回答是:Qwen,或者 DeepSeek。重要的事说三遍:必须是通过 API,必须是通过 API,必须是通过 API。因为网页端有系统提示词,会做二次处理。

超越 GPT-5.5、Gemini 3.5 Flash、DeepSeek V4 Pro,阿里的最新旗舰模型 Qwen3.7 Max 在编程竞技榜拿下第二名,仅次于 Claude Opus 4.7。除了真实场景的用户选择,在传统的大模型固定评测榜单上,像是终端能力 Terminal Bench、编程能力 SWE Bench 等,Qwen3.7 Max 的表现也是拿下了国产模型的冠军。

Code Arena最新放榜,Qwen3.7-Max以1541分冲进全球第四,成为前五中唯一的非Claude模型。编程,中国模型第一次杀到这个位置。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。