
刚刚,中国AI闯入全球编程前二!前面只剩Claude
刚刚,中国AI闯入全球编程前二!前面只剩ClaudeCode Arena最新放榜,Qwen3.7-Max以1541分冲进全球第四,成为前五中唯一的非Claude模型。编程,中国模型第一次杀到这个位置。
来自主题: AI技术研报
11004 点击 2026-05-27 09:14
 搜索
搜索
Code Arena最新放榜,Qwen3.7-Max以1541分冲进全球第四,成为前五中唯一的非Claude模型。编程,中国模型第一次杀到这个位置。
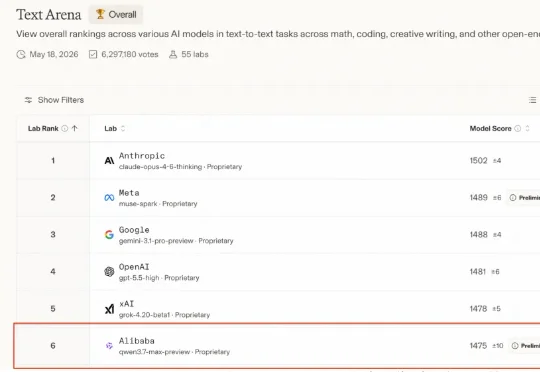
仅仅一个月后,阿里又带着最强旗舰模型杀回来了!今天上午,在 2026 阿里云峰会上,阿里全新一代千问旗舰模型 Qwen3.7-Max 登场了!在 Arena 公布的最新一期全球大模型盲测总榜中,Qwen3.7-Max 总成绩位列国产模型第一:傲视一众国产大模型
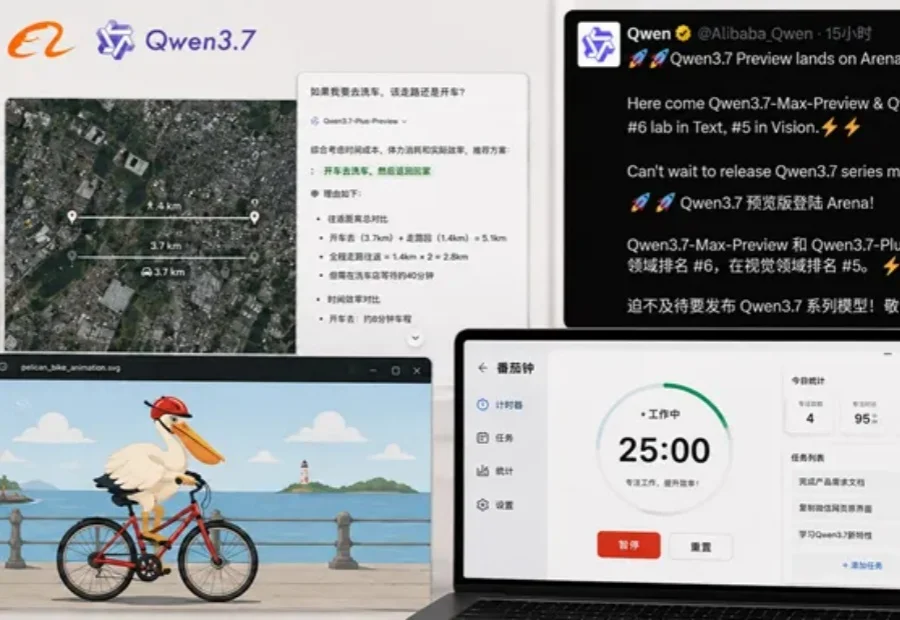
阿里正加速Qwen主模型的迭代节奏。

阿里你的嘴是真严啊,怎么一眨眼Qwen 3.7预览版突然就上线了!

当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。
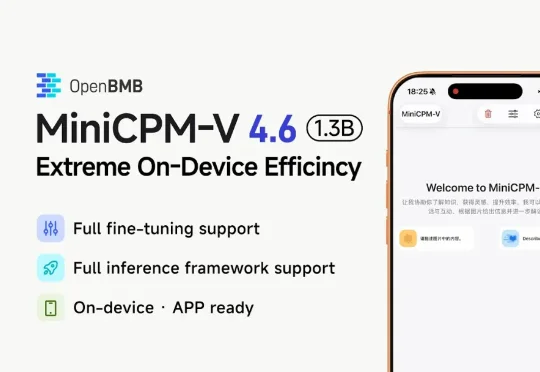
面壁智能正式发布并开源了 MiniCPM-V 系列新一代基础模型——MiniCPM-V 4.6。这款模型的整体参数规模仅约 1B(1.3B),是该系列有史以来参数规模最小的一款。但在多模态综合能力上,它却成功超越了被视为标杆的阿里 Qwen3.5-0.8B 和谷歌 Gemma 4 E2B-it,做到了「尺寸更小、效率更高、性能更好」。

独家获悉,字节跳动日前低调公布全球首个25B级、基于混合专家 (MoE) -扩散自注意力机制(DiT) 的开源增强统一多模态模型Mamoda2.5。Mamoda2.5依托Qwen3-VL-8B、128 个专家,Top-8 路由的MoE+DiT架构搭建,最终模型参数高达250亿,而每次仅激活约30亿参数(约12%)。
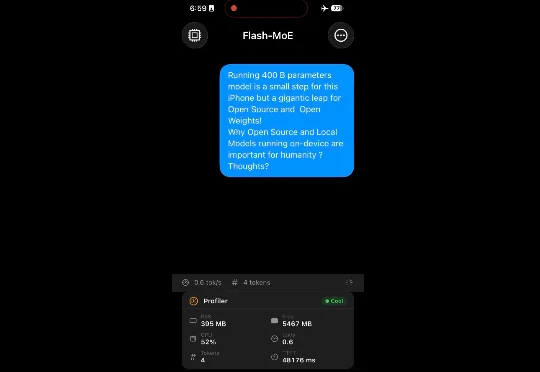
刚看到这个 Demo 的时候着实有些想笑,很久没有见过吐词如此之慢的大模型了。观感上就像「闪电」老师。尽管只有每秒 0.6 个 tokens 的输出速率,这依旧是一个令人不可思议的工作。因为这是一个跑在 iPhone 17 Pro 上的 400B 大模型!
Qwen3.6系列全员集结完毕。
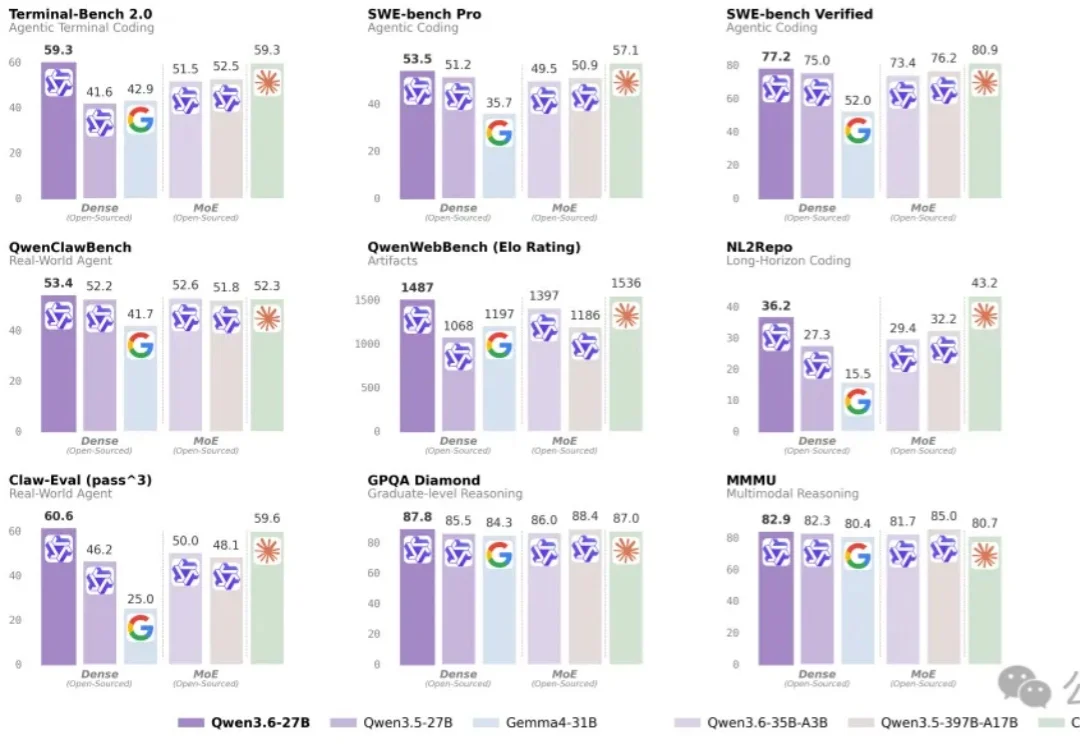
我秒了我自己??