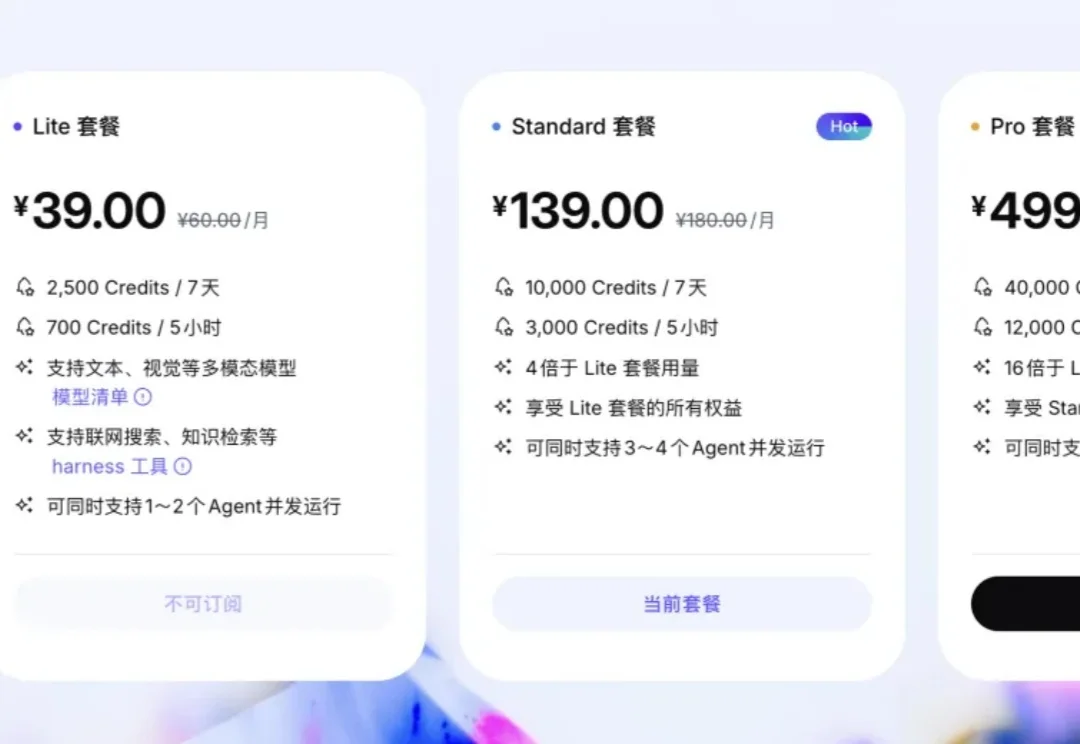
速测 Qwen3.8 预览版:我用 1 小时,开发了套撒币系统
速测 Qwen3.8 预览版:我用 1 小时,开发了套撒币系统我刚刚 AGI Bar 小程序里建了一个共享钱包,并往里面充了 1 万块,未来 24h可点开领取
来自主题: AI产品测评
10572 点击 2026-07-20 15:20
 搜索
搜索
我刚刚 AGI Bar 小程序里建了一个共享钱包,并往里面充了 1 万块,未来 24h可点开领取

算力承压,Kimi 暂停 C 端新用户订阅、OpenAI 战略未来负责人:Kimi K3 性能接近 2026 年第一季度最佳公开模型、Claude Fable 5 官宣永久可用、IDC 预计 2030 年全球活跃智能体将超过 22 亿个

由阿里巴巴集团孵化的空间智能企业“元境”,正在内测“JellyToken”,平台定位AI大模型一站式超市,支持一套密钥调用多款模型。该平台整合了Qwen3.7、Seedance2.0等多款国产大模型,面向个人创作者、中小团队、企业推出付费统一调用服务。
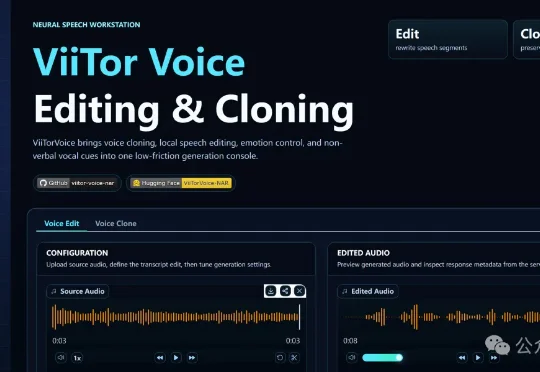
全球第一!中国AI语音ViiTorVoice首创「局部编辑」神技:配音错字告别重录,像改Word一样修语音。内附姆巴佩、哈兰德爆笑实测,快来见证!这个凭空出世的中国模型,将 Qwen3-TTS、CosyVoice3、Fish Audio 等一众主流巨头挑落马下,径直登顶综合排名第一!
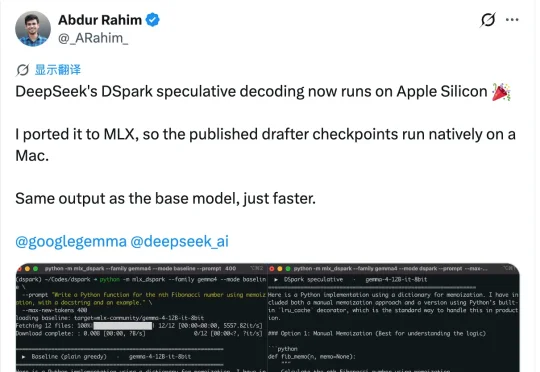
DSpark刚开源一周,就被搬进了苹果电脑。移植版本叫mlx-dspark,跑的是Gemma-4 12B和Qwen3-4B这两个模型。装上之后,这两个模型在Mac上的生成速度分别提了1.6倍和1.4倍。
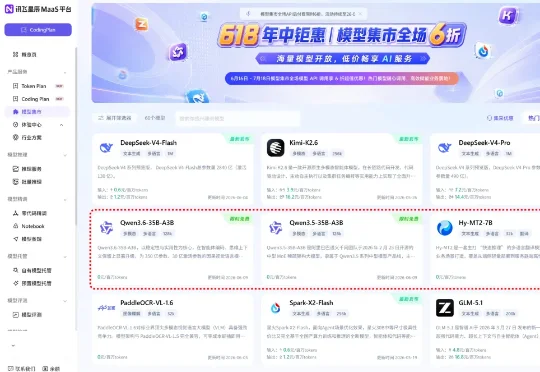
前几天听说讯飞星辰 MaaS 平台在做活动,一些模型可以限时免费调用,我第一反应就是先领了再说。这次活动限时开放了 Qwen3.6-35B-A3B 和 Qwen3.5-35B-A3B 两个模型的免费调用权益,新老用户都可以参与。
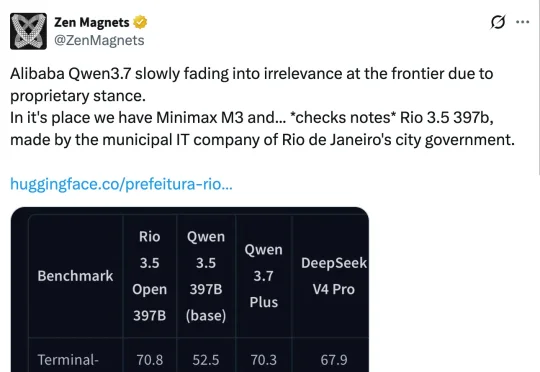
今天,除了全球(非美)被禁的 Claude Fable 5,AI 社区还被一个开源模型刷屏了。有推特博主发现,一个由巴西里约热内卢市政府旗下 IT 公司开源的模型 Rio 3.5 397B,在多项基准测试中超越了 Qwen 3.7 Plus 等开源模型,而这个模型的基础模型还是 Qwen3.5-397B-A17B。

今天,阿里通义千问发布多模态智能体模型Qwen3.7-Plus。相比传统“看图说话”式多模态模型,Qwen3.7-Plus在识别图像的基础上,进一步打通界面感知、工具调用、代码生成和任务交付,让AI从“读懂世界”,走向“动手完成任务”。
普通人看排行榜估计越看越疑惑,写文章该用哪个?数据分析该用哪个?写代码、审 PR、拆任务又该用哪个?我挑了四款最近讨论度很高的模型:Claude Opus 4.8、Gemini 3.5 Flash、GPT-5.5、Qwen3.7-Max,做一次横评,看看它们在真实任务里的交付表现。

超越 GPT-5.5、Gemini 3.5 Flash、DeepSeek V4 Pro,阿里的最新旗舰模型 Qwen3.7 Max 在编程竞技榜拿下第二名,仅次于 Claude Opus 4.7。除了真实场景的用户选择,在传统的大模型固定评测榜单上,像是终端能力 Terminal Bench、编程能力 SWE Bench 等,Qwen3.7 Max 的表现也是拿下了国产模型的冠军。