连不上Gemini CLI,试下DeepSeek-R1接入Claude code
连不上Gemini CLI,试下DeepSeek-R1接入Claude code这两天Google推出了Gemini-CLI这个编程工具,功能和Claude Code基本一致,结果根本排不上队,登录一下很快闪退,和下图一样,使用感受令人不愉悦。很多人都在等着体验这个新工具,但现实是您可能要等很久才能轮到。
来自主题: AI技术研报
10670 点击 2025-06-27 11:00
 搜索
搜索
这两天Google推出了Gemini-CLI这个编程工具,功能和Claude Code基本一致,结果根本排不上队,登录一下很快闪退,和下图一样,使用感受令人不愉悦。很多人都在等着体验这个新工具,但现实是您可能要等很久才能轮到。
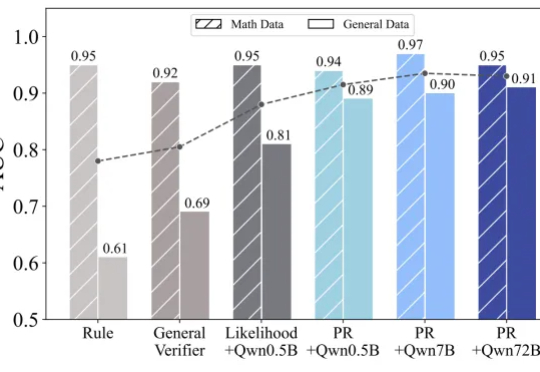
Deepseek 的 R1、OpenAI 的 o1/o3 等推理模型的出色表现充分展现了 RLVR(Reinforcement Learning with Verifiable Reward
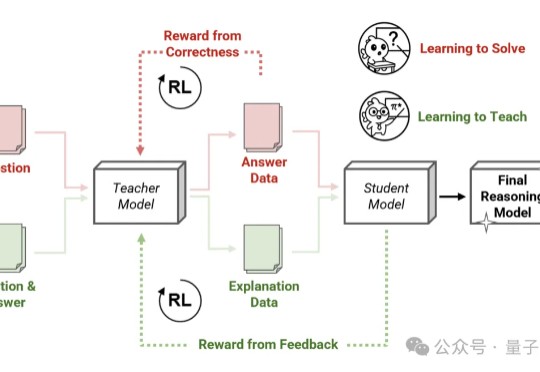
Thinking模式当道,教师模型也该学会“启发式”教学了—— 由Transformer作者之一Llion Jones创立的明星AI公司Sakana AI,带着他们的新方法来了!
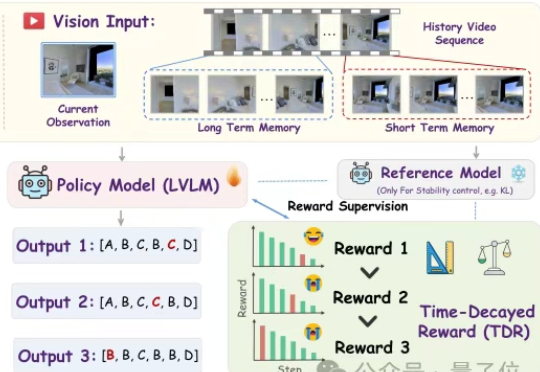
你对着家里的机器人说:“去厨房,看看冰箱里还有没有牛奶。”
强化学习可以提升LLM推理吗?英伟达ProRL用超2000步训练配方给出了响亮的答案。仅15亿参数模型,媲美Deepseek-R1-7B,数学、代码等全面泛化。
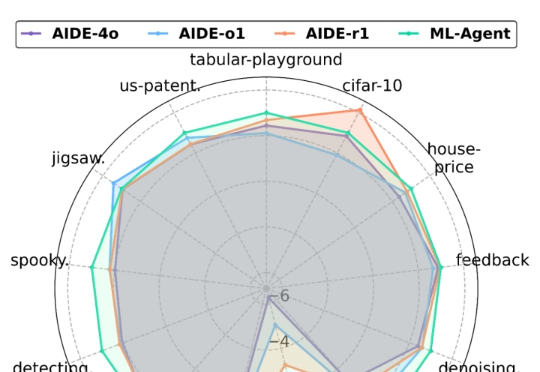
尽管人工智能(AI)在飞速发展,当前 AI 开发仍严重依赖人类专家大量的手动实验和反复的调参迭代,过程费时费力。

自年初起,DeepSeek-R1、OpenAI o3、Qwen3等推理模型相继问世,展现出令人惊叹的智能水平,但它们为什么突然变得这么聪明?东京大学联合Google DeepMind的研究者们终于找到了答案。
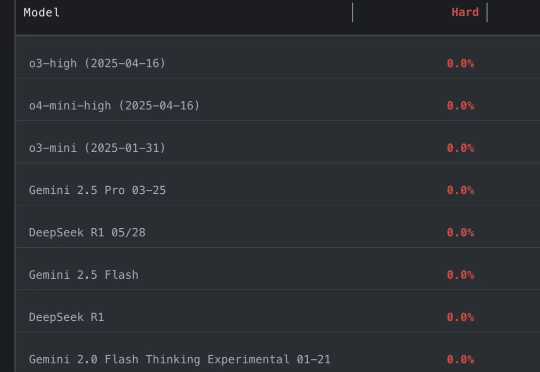
好夸张…… 参赛大模型全军覆没,通通0分。 谢赛宁等人出题,直接把o3、Gemini-2.5-pro、Claude-3.7、DeepSeek-R1一众模型全都难倒。
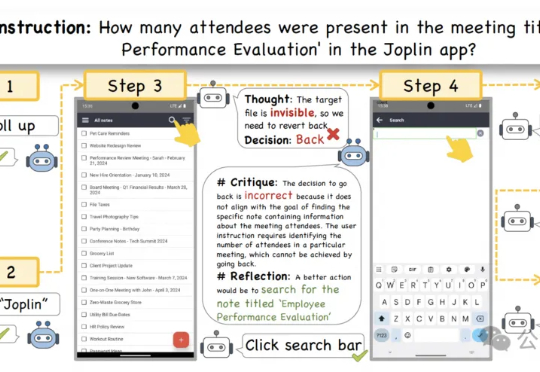
GUI智能体总是出错, 甚至是不可逆的错误。 即使是像GPT-4o这样的顶级多模态大模型,也会因为缺乏常识而在执行GUI任务时犯错。在它即将执行错误决策时,需要有人提醒它出错了。

在开源模型领域,DeepSeek 又带来了惊喜。