
字节Seedance,正在占领好莱坞
字节Seedance,正在占领好莱坞从被排斥到占领好莱坞,字节Seedance你都做了什么??现在好莱坞已经是酱婶儿的了:比如这部95分钟长片《Hell Grind》(地狱磨坊),Higgisfield AI出品。还有这部AI奇幻剧集《骸骨编年史》,包含了6条独立故事线和众多角色:
来自主题: AI资讯
8336 点击 2026-07-06 15:50
 搜索
搜索
从被排斥到占领好莱坞,字节Seedance你都做了什么??现在好莱坞已经是酱婶儿的了:比如这部95分钟长片《Hell Grind》(地狱磨坊),Higgisfield AI出品。还有这部AI奇幻剧集《骸骨编年史》,包含了6条独立故事线和众多角色:

两万多名快手员工,今年以来最关心的话题就是可灵。 这不仅因为它已成为快手最具想象力的AI业务,还因为5月传出拆分上市的消息后,可灵估值一度超过母公司快手的三分之二。 可灵几乎成为全村的希望。过去的舆论
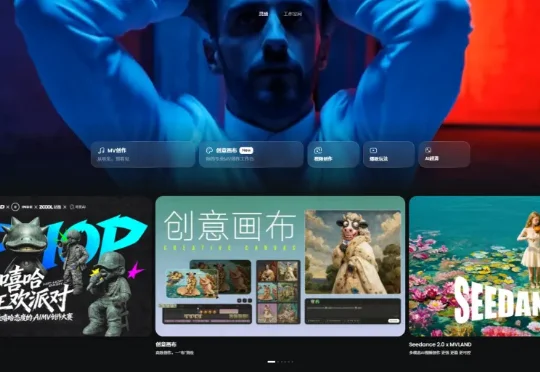
最近《在超市后门抽烟的二人》这部剧挺火的,尤其是里面的音乐我很喜欢,所以就想着做一个真人版音乐短片,正好发现美图旗下的 MVLAND 上线了创意画布模式,接入 Seedance2.0、可灵、HappyHorse 等顶尖视频生成模型。
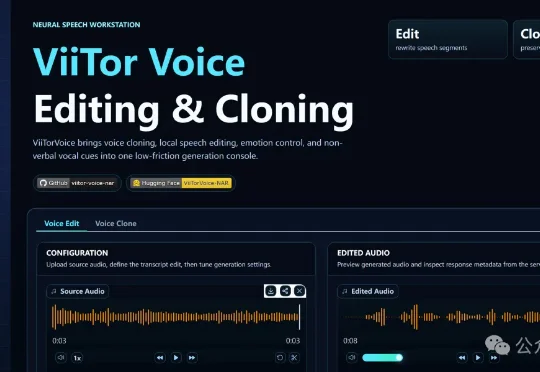
全球第一!中国AI语音ViiTorVoice首创「局部编辑」神技:配音错字告别重录,像改Word一样修语音。内附姆巴佩、哈兰德爆笑实测,快来见证!这个凭空出世的中国模型,将 Qwen3-TTS、CosyVoice3、Fish Audio 等一众主流巨头挑落马下,径直登顶综合排名第一!

豆包产品无敌,但Seed模型一直不温不火,大伙对它的印象就两个: 工资高,隔三差五就有千万年包上亿年包新闻,也不知道真假;多模态,但编程能力不太行。

今天 Seed 2.1 Pro 正式发布,我提前用它做了一些测试。
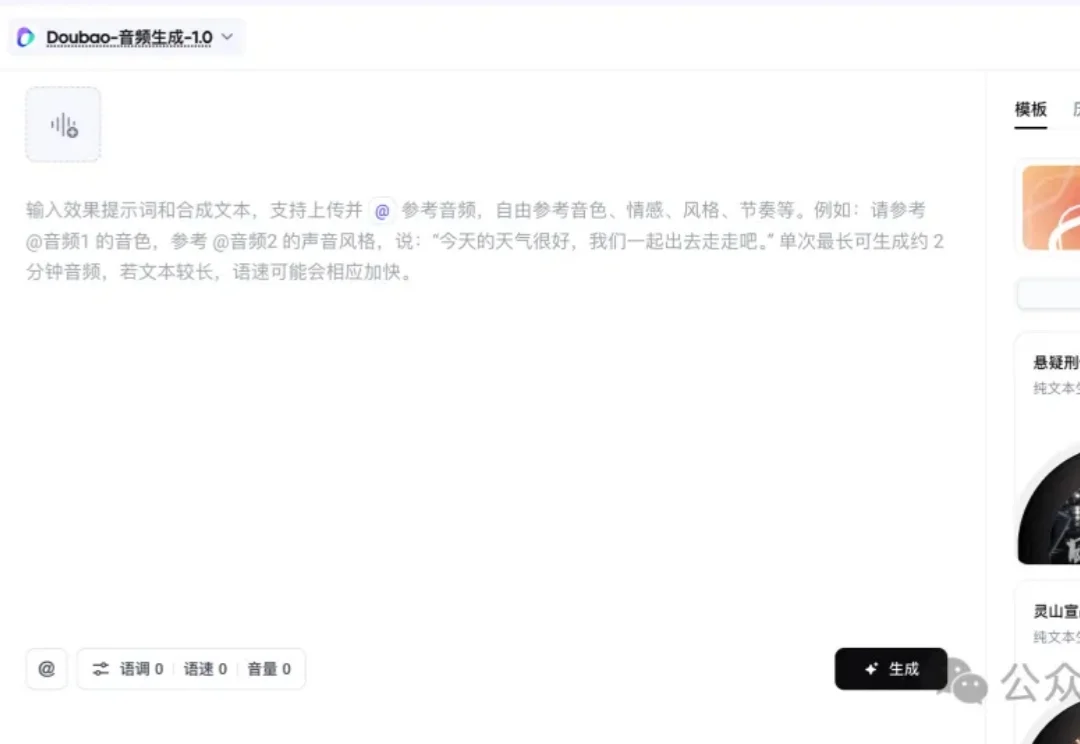
火山引擎今天上线了全新的语音模型—— 豆包音频生成模型 1.0(Seed-Audio 1.0)。

180 万亿。这是截至今年 6 月,豆包大模型的日均 token 调用量。
从 Founder Park 出去后,Muji 去新加坡深造了一年,然后以 COO 的身份加入了 Seede AI。

豆包大模型2.1 Pro正式发布。但字节这次没有像某些厂商那样疯狂堆参数、刷榜单,而是把刀锋对准了一个更硬核的方向:让AI真正能“干活” 。作为本次大会发布的主力模型,豆包2.1 Pro 在 Coding(编程)、Agent(智能体)、VLM(视觉语言模型)三大核心方向实现能力跃升,多项评测表现优于Claude Opus 4.6