
迎接范式革命:最新、最全的大模型Latent Space综述,NUS、复旦、清华等联合出品
迎接范式革命:最新、最全的大模型Latent Space综述,NUS、复旦、清华等联合出品从 2024 年底的关于潜在空间的早期探索,再到 2025 年底和 2026 年初的相关研究爆发,潜空间范式正在彻底重塑大模型 (LLMs, VLMs, VLAs 等延伸模型) 的底层设计逻辑。
来自主题: AI技术研报
7666 点击 2026-04-13 14:31
 搜索
搜索
从 2024 年底的关于潜在空间的早期探索,再到 2025 年底和 2026 年初的相关研究爆发,潜空间范式正在彻底重塑大模型 (LLMs, VLMs, VLAs 等延伸模型) 的底层设计逻辑。

近日,哈尔滨工业大学(深圳)联合深圳河套学院、Independent Researcher提出了隐式思考模型 LRT(Latent Reasoning Tuning),通过一个轻量级的推理网络,将大模型冗长的「思维链」压缩为紧凑的隐式向量表征,一次前向计算即可完成推理,无需逐 token 生成数千字的中间推理过程。
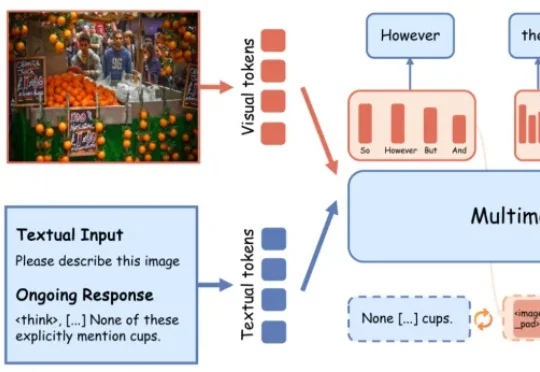
多模态大推理模型的幻觉,很多时候并非「没看见」,而是在最不确定的推理阶段想偏了。最新研究发现,模型在生成because、however、wait等transition words时,往往处于高熵关键节点,更容易脱离图像证据、转向语言脑补。LEAD在高熵阶段不急于输出单一离散token,而是先在潜在语义空间保留多种候选推理方向,并通过视觉锚点持续拉回图像证据,显著缓解幻觉。

总部位于首尔的 Wrtn Technologies 表示,该公司通过为韩国和日本的硬核动漫和游戏粉丝运营 AI 故事讲述应用,每月产生超过 800 万美元的收入。Wrtn(发音为"written")即将以一款名为 OOC("out of character"的缩写)的类似应用扩展到美国市场,这是龙与地下城角色扮演游戏中的常用术语。

就在大家都急头白脸地等待DeepSeek-V4的时候,冷不丁一篇新论文引起了网友们的注意—— 提出新稀疏注意力机制HISA(分层索引稀疏注意力),突破64K上下文的索引瓶颈,相比DeepSeek正在用的DSA(DeepSeek Sparse Attention)提速2-4倍。

据 Z Potentials 获悉,AI用户研究平台 Mizzen Insight 已完成天使+轮融资,融资金额近千万美元,由红杉中国种子基金领投,达晨创投、嘉程资本跟投。本轮融资将主要用于模型能力优化、产品迭代及市场拓展。

就在刚刚,据彭博社报道,iOS 27 将引入一套名为「Extensions」的新机制,允许用户通过设置面板,把 Google Gemini、Anthropic Claude 等第三方 AI 接入 Siri,就像现在调用 ChatGPT 一样直接从 Siri 发起请求。
前几天,一篇来自Kimi的论文「ATTENTION RESIDUALS」在 AI 圈引发了激烈讨论——马斯克罕见地发出评价:"Impressive work from Kimi"。同时,两位前Openai大佬也同样发出了高度评价,OpenAI 「推理模型之父」Jerry Tworek表示“深度学习2.0时代即将到来”。
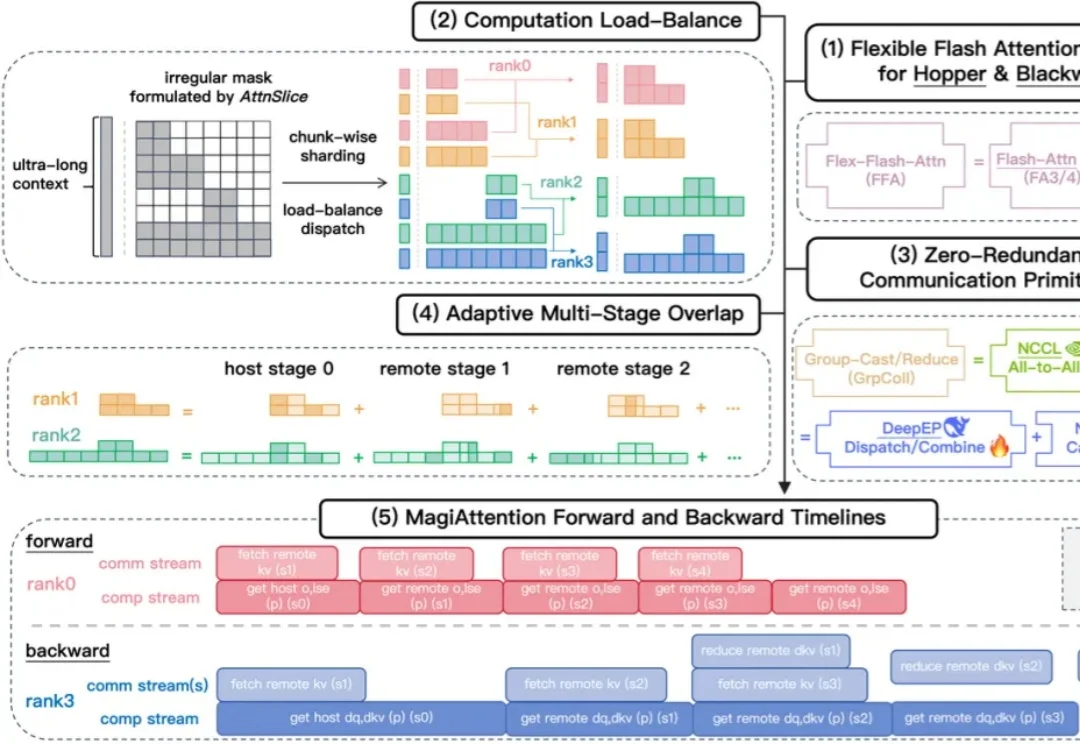
2025 年 4 月,Sand.ai 开源了 MagiAttention v1.0.0,定义了下一代分布式 Attention 的全新设计和系统框架。历经一年的深耕,今天 Sand.ai 正式发布:MagiAttention v1.1.0,以更成熟的原生算子组件,重新定义 Hopper 与 Blackwell 两代架构分布式 Attention 的性能上限。

所有用英伟达Blackwell B200的人,都在花冤枉钱??